Sat Oct 11 2025 00:00:00 GMT+0800 (中國標準時間)
感觉今天去听华为的会呢,引发了我自己的一些思考。
发现我自己对待未来的规划还是做的太少,我应该更多的思考这方面的事情了。
比如,或许我的目标是在今年年底写完一篇论文,最好是构思好下一个工作要做什么,这样就可以按部就班的去做了。然后考虑明年或者今年年底可以实习。
研究的目标:解决图片中不同类(不同菜品)的边界重叠/混合/覆盖的问题。
目前的背景:(也就是存在的困境不止一个challenge)
- 现在的场景(scenario)存在图片中不同类(不同菜品)的边界重叠/混合/覆盖的问题,导致对于中餐的识别/检测的准确度急速下降。
- 目前没人做中餐分割数据集(都不是数据集少的问题),是根本没人做。有关于中餐的复杂场景的数据集。
- 在复杂的菜品环境下,这样的数据被收集的很少。
我个人感觉这个逻辑上还是存在问题,怎么样可以把逻辑组合的顺畅一点?
背景:中餐词条
对中餐的理解、其体系、其内容等。
【来源于百度百科-中餐词条】
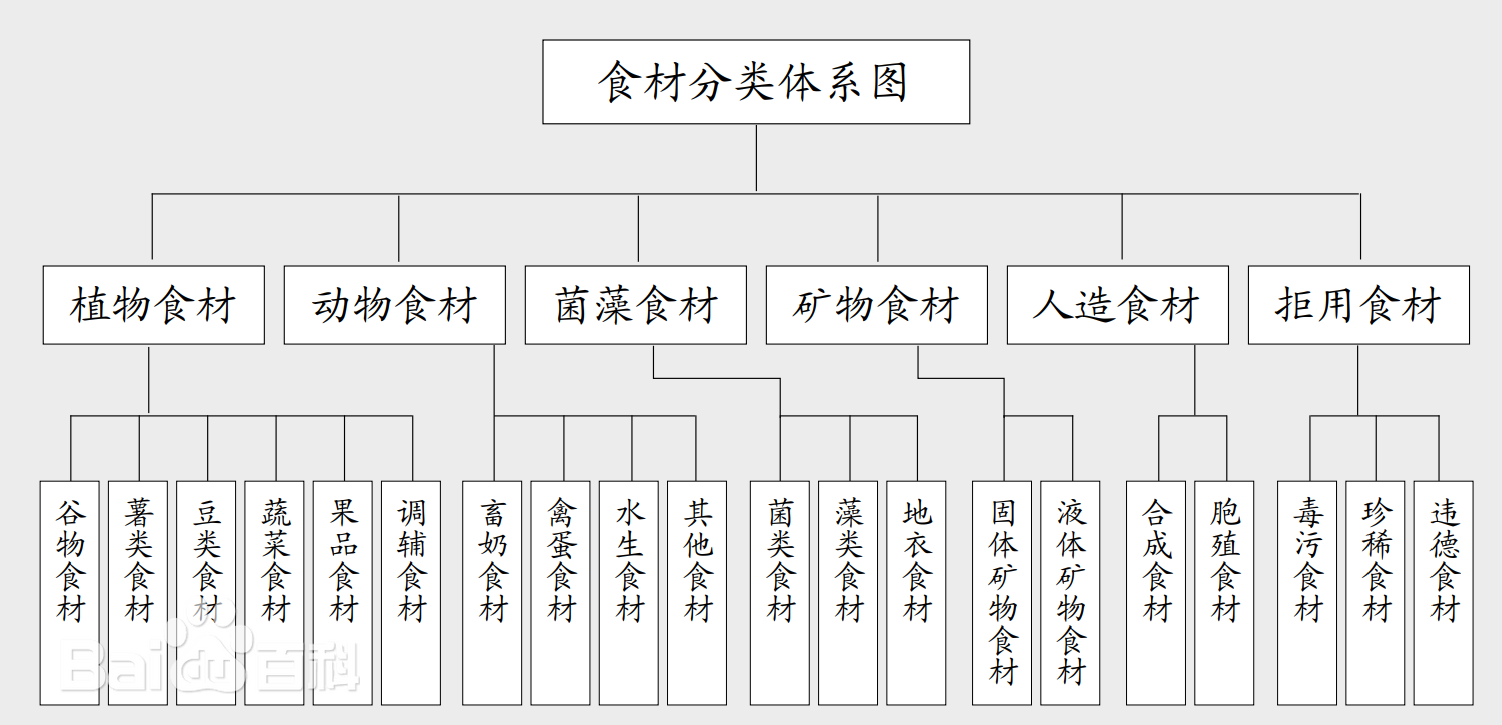
中餐食材是一个庞大体系,常用食材就有2000余种。食材分类主要有:按食材的原生性角度分类,按食材的商品性质分类,按食材的加工状况分类,按食材的烹饪运用分类,按食材的产业来源分类,按食材的化学介入分类,按食材的生物属性分类。
中餐工艺又称中餐加工工艺,由碎解工艺(刀法)、烹饪工艺、发酵工艺组成。中餐诞生以来,始终没有离开过这三种加工模式,它们包括了中餐所有的加工内容。
碎解工艺
通过物理的方法对食物进行加工。食材进入厨房后的物理性加工包括清理工作和食材切配两方面。
- 清理技法:食材清理工艺分为食材的清洁方法、食材的解冻方法、食材的涨发方法、食材的分割方法。
- 刀工技法:分为直刀法、平刀法、斜刀法、剂刀法和其他刀法五种类型。
- 碎解形制:根据成菜要求,运用不同刀法,将食材加工成块、片、条、丝、丁、粒、末、泥、段等应用食材。
- 碎解组拼:冷拼技法有排、堆、叠、围、摆、覆、扎、瓤、包、塑、穿、串、酿、贴、扣、填等;依据食材类型,生食技法分为水果生食技法、蔬菜生食技法和动物生食技法。
烹饪工艺
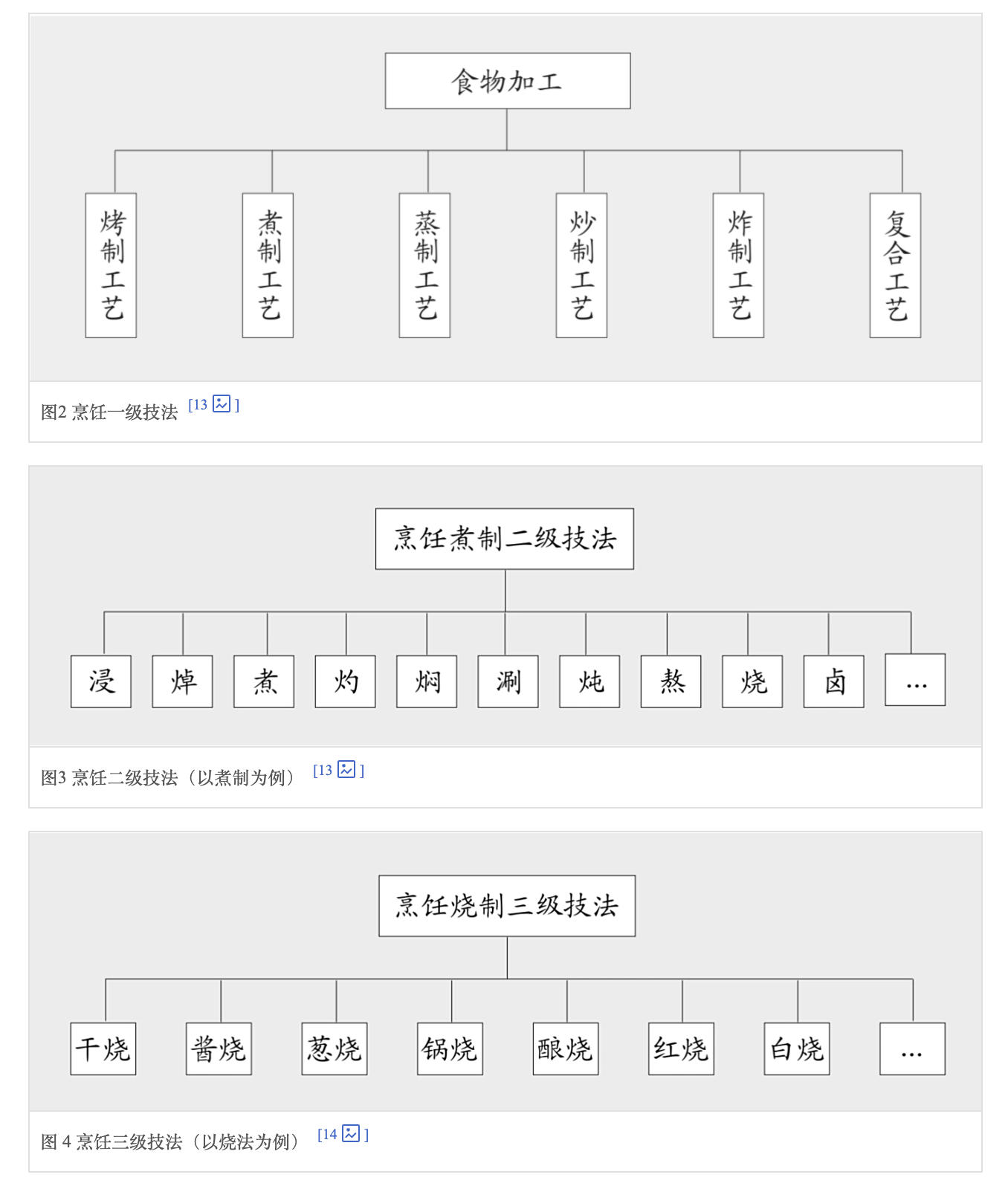
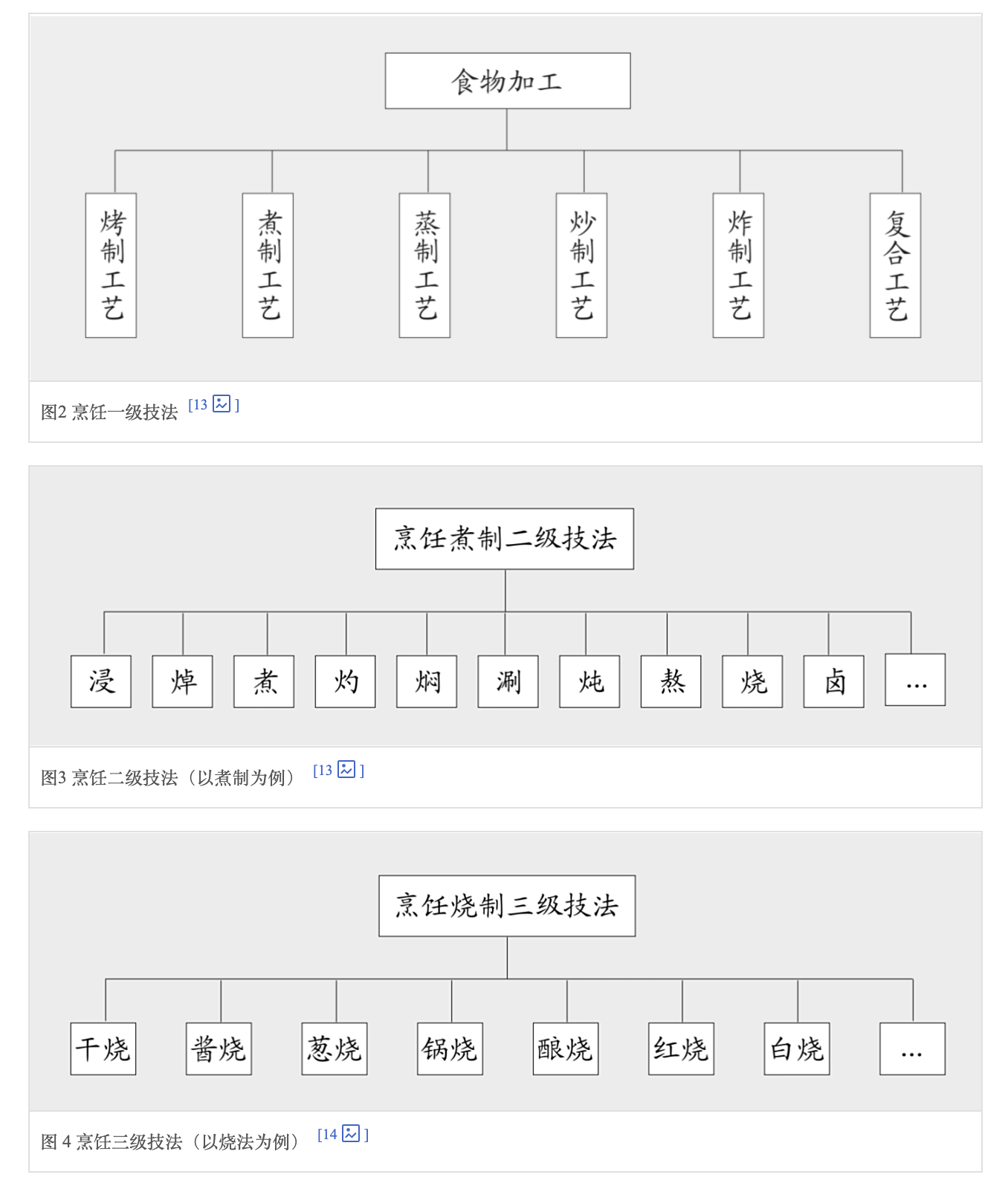
通过热传导对食物进行加工,也是中餐加工中最重要的一种工艺模式。烹饪预熟工艺包括焯水、过油、汽蒸、走红、挂糊、上浆、烹前调味、烹前发酵等工艺环节。对于烹饪技法体系,迄今“有名有姓”、全国通用的技法就有四十余种,地方性的技法、不见于经传的技法更多。 从烹饪技法的科学原理入手,搭建了中餐烹饪7-3技术体系。“7”是“6+1”结构。6指依据传热介质的不同,将其分为烤、煮、蒸、炸、炒、复合6个烹饪技法类型。1指无热技法。“3”指中餐技法的三个层级。
发酵工艺
利用微生物改变食物的性状。发酵工艺体系有三个层级,第一层级为菌种层级;第二层级依据各菌种下的生物类别划分,称为生类层级;第三层级为成品层级。中餐发酵二级技法体系见图:
背景:目前面临的挑战
数据收集上
中餐以多种烹饪方式、多种食材进行加工而出名。
一是有关于中餐图片的数据集比较少;比如分类数据集,分类数据集只能够将整张图片作为一个整体去识别出一个类/菜品。此外,其粒度太粗,基本上是对于菜品整体进行识别,但是一到菜品中存在不同的食材。甚至说会有有不同的食材,但是被算作同一道菜的情况。这导致了类内差异大。
目前已有的有关于中餐的数据集有:ChinaFoodNet,Food2k等。
比如,宫保鸡丁,可以是黄瓜+鸡丁,也可以是花生+鸡丁,有时也会有辣椒等。
WIKI百科上说:宫保鸡丁是中国四川、山东、贵州和北京的传统名菜,以鸡肉为主料,搭配花生米、辣椒等辅料经急火快炒制成,具有糊辣荔枝味型特征,红而不辣、肉质滑脆。 该菜起源于鲁菜酱爆鸡丁与贵州胡辣子鸡丁,由清朝山东巡抚丁宝桢改良推广形成新菜式,其名源自丁宝桢被追赠的“太子太保”官衔,并被归纳为北京宫廷菜。
黄瓜,胡萝不,花生,鸡丁
辣椒,花生,鸡丁,葱
比如,目标检测数据集FoodDet100k。虽然可以在一张图片中识别出多道菜品,但是其粗粒度地只能识别出这是什么菜品,还是无法处理其食材种类。也存在上述的问题。
至于分割数据集,目前有有简单的FoodSeg103,一共有103种食材,是食材级别的分割。但是这个是西餐为主的数据集。综上,目前缺乏中餐、分割、多道菜品、食材级别的数据集。
现有方法上
因为我们的场景是对于粘连的菜品(不同类别)进行识别,因此需要勾勒出其边界,因此我们将从分割任务的方法上进行调研。
(稍微感觉这一句话不知道在哪里提出会比较好)
这就引出了第二个挑战。由于数据集导致的现有方法都不太准确。分为通用方法和专门方法。通用方法基于其他通用数据集设计,导致其泛化到食品上这种复杂情况下,准确度不高,mIoU在10-20左右。比如MaskFormer,OneFormer、MaskCLIP等。(我觉得选取对比方法上需要有自己的一个考量)
但是目前专门设计用来处理菜品的方法,OvsegFood的方法是闭源的,而且其目前达到的mIoU也是30左右。但是这个方法是在FoodSeg103上处理的,在中餐上的效果还是不好。那么有关于被设计用来专门处理中餐的复杂情况的分割方法就是没有。
总结
那么基于上述的两个方面的研究空白,我们对此开展了研究。此研究的重点/重要之处在于:
- 中餐在全球范围内有大部分的人以中餐为主要日常饮食摄入。通过对中餐进行评估,有助于我们可以对中餐中包含的营养物质进行研究、以及对于人体每日摄取对于人体健康的影响有更好的评估。
一些自己的思考
能不能基于决策树?决策树的优势是 “可解释性强、处理离散标签高效”
在最后预测cls的时候输出的vec可以是是一个多位数,每一个bit都包含一定的信息。这样可以压缩最后分类的维度。
负采样 减少负标签冗余计算,或许可以化用。因为使用二进制的cls,导致label的稀疏性变得更大。或在标注时对高频维度(如食材)标注更密集,低频维度(如切割方式)用 “弱标注”(如仅标注关键区域),减少冗余。
相当于我们现在也是具有两种模态信息,也就是文本和图像。但是问题在于,现在有关于多模态的方法可以被分为encoder-only和encoder-decoder的方法。
现在还有一个问题就是我们收集的图片数据是从网上扒的,也是包含很多的noise的。目前的研究比较倾向于img对应的text是alt text,其中包含很多的noise的信息。(FLIP生成文本较好)
alt text 噪声处理可分 “预处理 - 训练 - 后处理” 三阶段
论文的数据集无噪声(人工标注),但你的数据来自网络,可借鉴 “领域规则 + 模型筛选” 的思路:①预处理:用正则表达式过滤无意义文本(如 “图片 123”),保留含食品关键词的文本(如 “食材”“烹饪”“做法”);②训练:用 “对比学习” 筛选高质量样本(如将图像与 alt text 输入 CLIP,相似度 > 0.5 的样本用于训练,否则丢弃);③后处理:对预测结果进行 “语义一致性检查”(如 “清蒸鱼” 的文本描述中不应出现 “油炸”,若出现则修正为 “蒸鱼”),类似论文 “负采样确保标签一致性”。
hard negative 挖掘需结合 “食品领域语义” 设计
论文无 hard negative 设计,但你的任务需区分相似食材,可参考 “领域内语义差异” 生成 hard negative:①食材层面:对 “鸡胸肉” 样本,将 “鸭胸肉”“火鸡胸肉” 作为 hard negative(而非 “土豆” 这种易区分的负样本);②烹饪方式层面:对 “水煮” 样本,将 “清蒸” 作为 hard negative(二者质地相似);③文本层面:对 alt text “番茄炒蛋”,生成 “番茄炒鸡蛋”(相似表述)、“番茄蛋汤”(烹饪方式差异)作为 hard negative。通过 “hard negative 对比损失”(如将样本 - 正文本的相似度与样本 - hard negative 文本的相似度差值最大化),提升 CLIP 对细粒度语义的区分能力,弥补其 “浅层相似度” 的不足。
再一个,我不看好clip在我的任务中得到比较好的结果,因为clip是提取的img-text的非常shallow的similarity,对于我们图片中属于一个大的食品空间下的十分多非常相似的食材来看,他们的相似度应该非常的高,所以需要一个hard negative,然后再找找看看有什么策略可以比较好处理noise。
在损失函数的设计上,一种想法是针对我们这个特定的领域去施加正则化约束/也就是添加适应的loss function。另外一种想法是做通用的loss,而不需要很多的loss,因为“简单就是最强的”。
BCE loss(交叉熵损失)-分割分类,类似ITM(img-text matching)但是不太一样,这个是与GT计算,ITM是计算img-text是不是匹配的,都可以要。
ICT loss(对比学习损失)-img-text的匹配,(如 “番茄块” 区域与 “番茄” 文本的相似度最大化,与 “土豆” 文本的相似度最小化)
MLM(Mask language matching loss)-文本进行完形填空(或许img也可以?)
我认为或许可以结合这两种?就是设计一个通用于Food领域的loss,保证在Food领域具有很强的通用性。但是其实做通用loss的原因之一是因为:反复算很多的loss,有的输入不一样,会导致做多次的feedforward前馈过程,会加剧计算量/时间消耗。
食品领域约束:添加轻量化正则化项
在通用 loss 基础上,添加 1-2 个食品领域专属正则化项,而非多个复杂 loss,平衡性能与效率:①“食材 - 烹饪方式一致性约束”:若标签为 “油炸鸡翅”,则 “鸡翅” 区域的 “油炸” 语义概率需高于 “清蒸”(通过 L1 损失强制二者差值 > 0.3),避免出现 “清蒸鸡翅标注为油炸” 的矛盾;
②“切割方式 - 区域形态约束”:若标签为 “切丁胡萝卜”,则胡萝卜区域的外接矩形长宽比需接近 1(通过形态学特征与语义概率的相关性损失优化),类似论文 “负采样约束标签稀疏性” 的思路,用领域知识引导模型学习关键语义关联。这种设计既保留了通用 loss 的简洁性,又通过轻量化约束提升了食品领域的适配性,避免 “为了精度添加过多 loss 导致计算量失控”。
总的来说,目前的挑战可以再丰富一点:还是分为数据上的和方法上的。上面的都可以归结进去。
下面是豆包总结的,但只是对前面的进行总结,实际上也不是很fit
(一)数据层面挑战
- 噪声数据的 “质量 - 数量” 平衡:网上爬取的图像 /alt text 存在 “文本与图像不匹配”(如 “红烧肉图片配番茄炒蛋文本”)、“语义模糊”(如仅标注 “家常菜”)问题,需设计高效的清洗策略(如 CLIP 相似度筛选、决策树规则纠错),避免噪声影响模型训练;同时,需保证清洗后的数据量足够支撑多维度语义学习(如每种烹饪方式至少 1000 个样本)。
- 标签的 “细粒度 - 标注成本” 矛盾:需标注 “菜品 + 食材 + 烹饪方式 + 切割方式” 等多维信息,像素级标注成本极高,如何借鉴论文 “图像级标注降低成本” 的思路,设计 “弱标注 + 自动补全” 方案(如先标注图像级菜品类别,再通过模型预测补全像素级食材标签),平衡标注精度与效率。
- 相似食材的 “数据稀缺性”:如 “鸡胸肉” vs “鸭胸肉”“普通番茄” vs “圣女果” 等细粒度类别,网上数据量少且易混淆,需人工扩充数据(如拍摄专业样本)或通过数据增强(如调整色泽、添加纹理)生成相似样本,避免模型对小众食材的漏识别。
(二)方法层面挑战
- CLIP 的 “浅层相似度” 与 “细粒度语义” 的适配:CLIP 难以区分食品领域的相似语义(如 “切丝” vs “切末”“油炸” vs “油煎”),需设计 “领域微调 + hard negative 对比学习” 方案,提升跨模态匹配的细粒度,同时避免微调导致的过拟合(如用少量高质量数据微调)。
- 多维度语义的 “特征关联与冲突解决”:不同语义维度可能存在关联(如 “油炸”→“小块食材”)或冲突(如 “大块食材” 标注为 “切丝”),如何通过 “特征融合(多尺度 CLIP 特征)+ 领域约束损失(语义一致性)” 让模型学习合理的语义关联,避免维度间的相互干扰。
- “效率 - 精度” 的平衡:多模态、多尺度、多 loss 的组合易导致计算量激增(如 encoder-decoder 的多次前馈、hard negative 的额外计算),需优化架构(如轻量化 CLIP 模型、多 loss 共享特征提取层),在保证分割精度的同时,满足实际应用的实时性需求(如推理速度 > 10fps)。
一些与GPT交流的内容
你计划将该研究聚焦于图像分割(semantic/instance/panoptic segmentation)中的哪一类任务?是以菜品为类,还是以食材为类?我将聚焦于语义分割,想要通过以菜品级分割+食材级属性额外信息 来识别到图片中哪些区域属于什么菜,这个菜中包含什么食材。通过额外的信息,我们后续可以去开展一些下游工作,比如中餐的营养评估或VQA等。
你是否计划构建一个新的中餐分割数据集,还是使用已有数据(比如从FoodDet100k或ChinaFoodNet中抽取)?是的,我们现在已经收集了10k的混合菜品的数据图片,但是目前在标注分割的mask中。你或许可以指导一下我的数据集要怎么继续标注、以及我现在的数量级是不是太小了,如果我想要提高方法的效率,我应该将数据集扩大到多大是比较合理且efficient的?有什么流程或者是理论上可以支撑?
你是否已有一些初步的方案(比如数据增强、图像生成、边界建模、跨模态等)或希望调研的方法方向?是的,因为我们要标注的类别非常的多、但是类别对应的图片/数据又很少。我现在的想法是:在数据上,对现有数据进行数据增强来增加数据量。考虑能不能以少量的精确标注(比如额外信息标注出一个菜品中包含什么食材、都是以什么方式被处理的、包含什么佐料等),能够泛化到更大的范围进行识别。在方法上,考虑机遇CLIP来结合文本数据和图像数据去设计自己的方法,然后可能采用MoE的架构,强化学习的方法来进行优化等等。
是否有特定应用场景,比如餐盘估算、卡路里识别、智能食堂等?是的,目前先针对的特定的场景是想要落地的应用:比如给出一个餐盘,我需要准确的识别出来这里都有什么菜(原来是因为菜品粘连导致识别的准确度不高),这样可以帮助在食堂或餐厅中能够智能计算价格之类(以菜品不同来收钱)。后续可能会扩展下游任务,比如进行卡路里识别、营养评估等。
经过GPT完善的研究背景与挑战
在图像分割领域,中餐菜品具有独特挑战。
- 一方面,中餐菜品种类繁多、制作方法复杂,同一道菜在不同地区和做法下可能包含截然不同的食材和配料。已有研究指出,“单个食品的外观可能因不同加工方式而存在极大差异,这在复杂菜系(如中国菜)中尤为明显”mdpi.com。(例子:宫保鸡丁)
- 另一方面,多道菜品常在同一餐盘上出现且相互重叠,菜品之间的边界常常不清晰。例如,混合菜识别任务的研究就提到:“同一餐盘上的不同菜肴可能相互重叠,且它们之间可能没有明确的边界”openreview.net。这样的重叠和边界模糊会大幅降低现有识别/检测方法的准确率。
简而言之,多道中餐图像分割面临着类内差异大、类间重叠边界模糊等问题,亟需针对性的数据集和方法研究。
当前相关研究主要集中在单道西餐的分割或中餐的分类与检测,但几乎没有专门针对多道中餐分割(即在一张图像中同时对多道不同中餐进行区域划分)的公开数据集。
- 一方面,数据集不足:例如,中国菜分类数据集“ChineseFoodNet”包含18万张图像、208类ar5iv.labs.arxiv.org;FoodDet100k等目标检测数据集能标注出一张图中多个菜名,但仅提供粗粒度的菜品框选标签,无法细致地勾勒出各菜品的区域和内部成分。现有以食材为分割对象的数据集如FoodSeg103(包含7118张图像、103种西餐食材的像素级标注)huggingface.co,主要面向西餐环境,且图片通常只有单一道菜。因此目前缺乏一个多道中餐场景的、食材级别或菜品级别的分割数据集。
- 另一方面,算法方法局限:通用分割方法(如MaskFormer、OneFormer、MaskCLIP等)多基于通用场景数据训练,迁移到复杂的中餐场景时往往性能不佳。例如在FoodSeg103等公开数据集上,MaskCLIP的mIoU仅约为33%openaccess.thecvf.com。尽管有针对食物分割的研究(如最新的OVFoodSeg在FoodSeg103上表现略有提升),但这些方法主要面向食材分割,且目前专门处理中餐复杂情况的公开方法并不存在。
综上所述,现有的数据和方法都难以应对多道中餐的重叠混合问题,这就引出了我们研究的必要性。
经过GPT完善的研究任务与目标
针对上述挑战,我们计划聚焦于语义分割任务。具体而言,我们将把每种菜品作为一个语义类别,对单张图像中的各区域进行分类,进而确定哪些像素属于哪道菜。
这一段相当于在解释,食品分割中的语义分割的含义。
此外,我们还计划引入菜品的属性信息(如所含食材类型)作为辅助。通过先做菜品级语义分割并识别出不同菜品区域,然后结合识别出的菜名或额外标签,进一步推断该菜品包含哪些食材。
这一段比较空泛,不够细致。
这样的方法有助于下游任务,如营养评估或视觉问答等。例如,已有研究表明,精确的食物图像分割对于自动化饮食记录、营养成分分析具有重要意义mdpi.com。在我们的应用场景中,分割结果可用于智能食堂结算——准确勾勒出各菜品区域后,可精确统计每种菜品的数量并估价;后续也可用于卡路里计算和营养分析。
这一段相当于是研究意义。当然,作为研究意义的话还需要补充:就是这个补充了/弥补了目前在中餐分割上研究的空白。我认为有研究能够证明这个研究确实对于营养评估是有用的,这个还是蛮有必要的。
需要注意的是,虽然语义分割将每道菜视为一个类别进行像素级划分,但在多盘同一道菜同时出现的情况下,或者需要区分同一类菜的不同实例时,实例分割或全景分割也值得考虑。实例分割能够区分相同类别的不同实例,全景分割则整合了语义和实例信息。但鉴于目前我们关注的是“画出不同菜品的边界”,且目标是先识别菜品种类,我们将首先采用语义分割,并在有需要时结合实例分割策略(如必要时应用带类别标签的Mask R-CNN等)作为补充。
技术路线
我们可以从多模态融合(借助菜品文本信息)、网络结构创新(MoE、边缘增强)、训练策略(多任务、迁移学习)等方面协同发力,以应对类别多样、样本有限且边界模糊的挑战。在早期实验中,我们会对比纯视觉分割模型和引入文本食材信息的模型,以评估后者在菜品-食材关联上的效果。
多模态信息融合:借助文本-图像模型(如CLIP)将视觉特征与菜品名称或食材信息关联。比如,可以为每种菜品构造描述(“宫保鸡丁包含鸡肉、花生、辣椒”等),利用CLIP提取图像和文本的共同嵌入空间,从而帮助分割模型更好地区分视觉相似的菜品。这类似于开放词汇分割(open-vocabulary segmentation)的思路,已有方法(如OVFoodSeg)通过图像指导的文本嵌入提升分割性能openaccess.thecvf.com。我们也可借鉴其架构,将图像特征注入到文本编码器中,生成食材或菜名的图像感知文本嵌入,用于指导分割。
模型架构设计:在网络架构上,可探索混合专家(MoE)或模块化设计:针对不同菜系或菜品特点设计专门的网络分支(专家),再通过路由机制选择合适专家来处理输入。这有助于模型应对菜品多样性。
也可以尝试层级分支,先分割出所有菜品区域(大类别),再对每个区域做细分类或细分食材掩码。另一种思路是结合边缘感知网络(如MVEANetmdpi.com)强化对边界的捕捉能力,以更精细地勾勒粘连菜品的轮廓。
训练策略:对于多类极不平衡的数据,强化学习(RL)\可以用于优化样本选择或数据增强策略,例如用RL来学习最佳的增强组合或负样本挖掘策略,从而提升训练效率。但RL直接用于分割优化较为少见,需要谨慎考虑应用场景。更实际的做法是结合*多任务学习*:联合训练分割和食材/菜名分类任务,通过共享特征和互相约束,提高整体性能。
其他技术:考虑到同类食材形态多变,我们也可以尝试迁移学习与自监督预训练。如先在大规模通用图像或食物图片上预训练(参考Wu等人提出的ReLeM模型对食物进行预训练mdpi.com),再微调到我们的中餐分割任务上。此外,使用密集监督如边界损失(dice loss、IoU loss等)来对重叠边缘进行正则化,也常见于分割任务openaccess.thecvf.com。
应用前景或影响
研究多道中餐图像分割的意义不仅在算法上,更在于实际应用价值。精准分割出每道菜品区域有助于智能食堂或餐饮业场景:系统可以自动识别盘中有哪些菜、各自面积比例,进而实现按菜收费、菜品盘点等功能,减轻人工成本。同时,分割结果可用于营养和热量估计:结合食材识别结果和餐厅配餐数据库,可以计算每道菜的营养成分,从而辅助个人膳食记录和健康管理。有研究表明,食物分割是自动饮食记录和营养分析的基础mdpi.com。因此,我们的工作可为进一步的卡路里计算、膳食评价乃至健康监测提供重要支撑,具有较高的社会效益。
TFN
1 | import torch |
LMF
1 | # 核心思路:拆解为“模态线性变换 + 低秩交叉” |