Fri Oct 10 2025 00:00:00 GMT+0800 (中國標準時間)
scaling law?扩展数据集是否值得?
大模型的Scaling Law是OpenAI在2020年提出的概念[1],具体如下:
- 对于Decoder-only的模型,计算量$C$(Flops), 模型参数量$N$, 数据大小$D$(token数),三者满足: $C\approx 6ND$。(推导见本文最后)
- 模型的最终性能主要与计算量,模型参数量和数据大小三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。
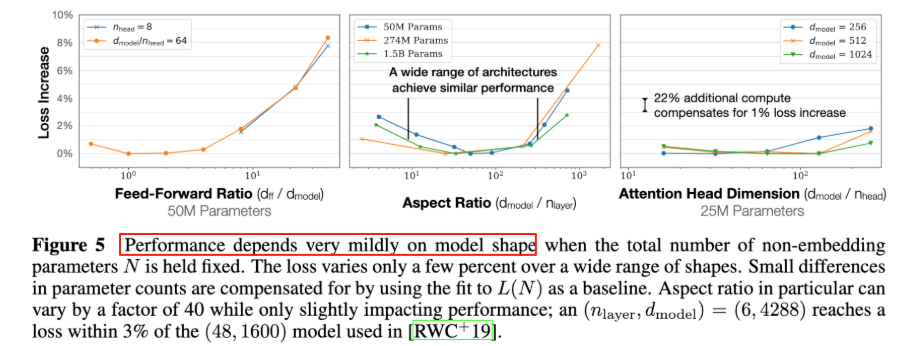
这导致固定模型的总参数量$N$,调整层数/深度/宽度,不同模型的性能差距很小,大部分在2%以内。
当非嵌入参数总数$N$固定时,损失(性能指标)在 “广泛的模型形状范围” 内仅变化几个百分点。参数计数的微小差异,可通过 “以 (L(N)) 为基线的拟合” 来补偿;模型结构的 “纵横比”(如层数与模型维度的比例)甚至能在 40 倍范围内变化,对性能影响仍很小。
- 左图(Feed-Forward Ratio):横轴是 “前馈网络比例((d_{\text{ff}} / d_{\text{model}}))”,纵轴是 “损失增加量”。不同 (d_{\text{model}}) 配置下(蓝色$n_{head}=8$,黄色$d_{model}/n_{head}=64$),损失随前馈比例的变化幅度都很小(当横轴从(10^0)变化到(10^1)时,纵轴上升幅度都很小),说明前馈比例对性能影响弱。
- 中图(Aspect Ratio):横轴是 “纵横比((d_{\text{model}} / n_{\text{layer}}))”,不同参数规模(50M、274M、1.5B)的模型,在广泛的纵横比范围内,损失(性能)都很接近。即 “纵横比变化时,只要参数总数固定,性能差异小”。
- 右图(Attention Head Dimension):横轴是 “注意力头维度((d_{\text{model}} / d_{\text{head}}))”,纵轴是损失。不同头维度(256、512、1024)下,损失变化幅度小;且注释提到 “22% 的额外计算,就能补偿 1% 的损失增加”,进一步说明结构变化对性能的影响可通过计算量微调来弥补。
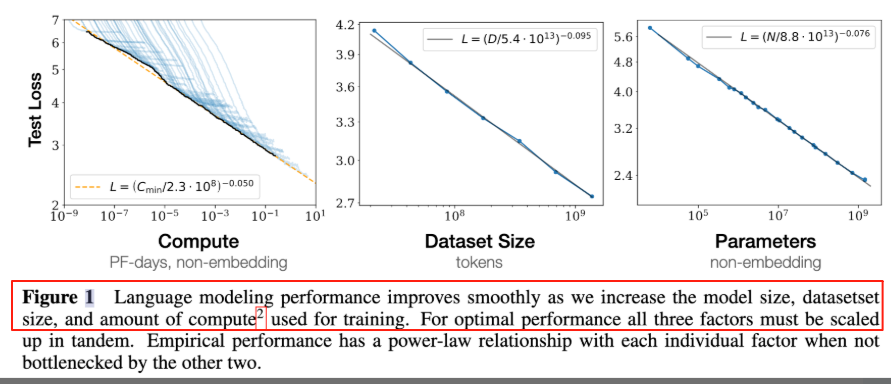
- 对于计算量$C$,模型参数量$N$和数据大小$D$,当不受其他两个因素制约是,模型性能与每个因素都呈现幂律关系。
一些启示
- 数据规模的 “边际收益递减”当数据从 10k 扩展到 100k 时,性能提升幅度会小于从 1k 到 10k 的提升,但若当前数据仅 10k,仍处于 “收益较显著的区间”(尤其是小数据集阶段)。
- 例:某语义分割任务中,数据从 10k→50k 时,IoU 可能从 70→80(提升 10 个点);但从 50k→100k 时,IoU 可能仅从 80→85(提升 5 个点)。
- “数据 + 模型 + 训练时长” 必须协同缩放
- 模型容量:只有大模型(如 SwinV2-G、SAM 等)才能 “消化” 大规模数据。若你用的是轻量级模型(如小型 U-Net),即使数据扩到 100k,性能也可能因模型容量不足而饱和甚至过拟合。
- 训练时长:大数据集需要更长的训练迭代(如从 125k 步→500k 步)才能发挥价值。若训练不充分,100k 数据的性能提升可能不明显。
- 数据多样性比 “单纯数量” 更重要分割标注成本极高(像素级标注),若 100k 图片的场景、目标分布单一(如仅室内场景、仅小目标),模型泛化能力提升有限。需通过以下方式增强多样性:
- 生成式数据增强:用 GAN、扩散模型生成合成标注数据(如 DiverGen 方法,通过 “类别多样性 + prompt 多样性 + 生成模型多样性” 扩充分布);
- 跨域数据融合:引入公开数据集(如 Cityscapes、ADE20K)或合成数据集(如 SYNTHIA)补充场景。
具体做法
步骤 1:先做 “小步扩展实验”,验证数据规模的影响
- 实验设计:先将数据扩到 20k、50k,保持模型和训练策略不变,测试验证集性能(IoU、AP 等)。
- 若 50k 时验证损失(或 IoU)仍在持续下降,说明数据未饱和,扩到 100k 可能有收益;
- 若 50k 时性能已趋于平稳,说明当前模型 / 训练策略下数据已饱和,需先优化模型或增强数据多样性。
步骤 2:拟合 “数据规模 - 性能” 的幂律曲线,定量预测收益
- 幂律公式:分割任务中,性能(如 IoU)与数据量 N 通常满足 (\text{IoU} = a \cdot N^b)(b 为负数,绝对值越小表示收益递减越慢)。
- 操作:收集不同数据规模(如 1k、5k、10k、20k)下的验证集 IoU,用对数回归拟合 (\log(\text{IoU}) = \log(a) + b \cdot \log(N)),预测 100k 时的 IoU。
步骤 3:评估 “成本 - 收益比”
- 成本:标注 100k 图片的人力、时间、算力投入(尤其是像素级标注的成本很高);
- 收益:性能提升对业务的价值(如 IoU 从 75→85 是否能满足下游应用需求)。