2025-12-9
有关分割的信息
语义分割+卷积
语义分割:不区分同类别的不同实例。
早期研究(2017): 由卷积神经网络(CNN)主导,以全卷积网络(FCN)、DeepLab系列和Mask R-CNN为代表,确立了“编码器-解码器”(Encoder-Decoder)的标准架构范式。以扩大感受野为主。
[Mask RCNN cite:46840]He, Kaiming, et al. “Mask r-cnn.” Proceedings of the IEEE international conference on computer vision. 2017.
[DeepLab cite:26157]Chen, Liang-Chieh, et al. “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs.” IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848.
[PSPNet cite:19248]Zhao, Hengshuang, et al. “Pyramid scene parsing network.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
DeepLab系列(空洞卷积dilated conv)
Q:传统的CNN通过池化层(Pooling)逐步降低特征图分辨率以扩大感受野,但这导致了空间细节信息的不可逆丢失,使得分割边界模糊。(==下采样导致细节丢失==)
A:DeepLab通过空洞卷积,在不降低特征图分辨率的情况下指数级扩大感受野。特别是DeepLabV3+,它结合了空洞空间金字塔池化(ASPP)模块,通过不同扩张率的并行卷积层捕获多尺度上下文信息,并引入了一个简单高效的解码器模块来恢复物体边缘细节。
PSPNet(Pyramid Score Parsing Net)
A:提出了金字塔池化模块(Pyramid Pooling Module, PPM)。该模块将特征图划分为不同大小的子区域(如1x1, 2x2, 3x3, 6x6),分别进行池化操作并上采样,最后将不同尺度的全局先验信息与原始特征图拼接。
Mask R-CNN(实例分割)
A:在Faster R-CNN检测框架之上,增加了一个并行的掩码预测分支。
创新:提出了RoIAlign层,取代了传统的RoIPool。RoIAlign取消了坐标的量化取整操作,通过双线性插值精确提取特征,从而解决了特征图与原始图像之间的像素不对齐问题。这一改进对于生成精确的像素级掩码至关重要。
全景分割(?)+LLM起步
全景分割:统一语义分割(关注背景“Stuff”)和实例分割(关注前景“Things”)。
近年(2017-2023):以Transformer为标志。ViT打破了卷积的局部性限制,引入了全局上下文建模能力。大模型开始崛起/2022年底,GPT发布。
[!TIP]
这个就非常的像SAM3的推理功能。
[ViT cite:79811]Dosovitskiy, Alexey. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[SegFormer cite:8360]Xie, Enze, et al. “SegFormer: Simple and efficient design for semantic segmentation with transformers.” Advances in neural information processing systems 34 (2021): 12077-12090.
[OneFormer cite:632]Jain, Jitesh, et al. “Oneformer: One transformer to rule universal image segmentation.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023.
[InternImage cite:1298,CVPR 2023 Highlight]Wang, Wenhai, et al. “Internimage: Exploring large-scale vision foundation models with deformable convolutions.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023.
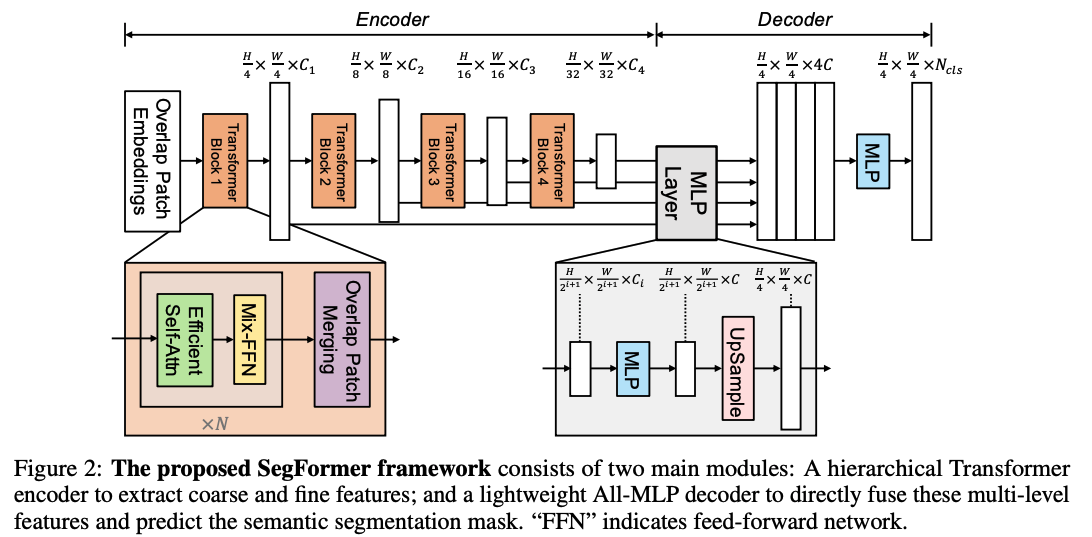
SegFormer-简单高效/实时分割
A:解决了早期ViT在分割任务中计算量大、对位置编码敏感的问题。
框架:
- 层次化结构:SegFormer采用类似CNN金字塔的层次化Transformer编码器,生成多尺度的特征图,这对于捕获大小不一的物体至关重要。
- MLP解码器:其最令人惊讶的设计在于解码器极其简单,仅由几个全连接层(MLP)组成。这表明,只要编码器的特征足够强大(具备全局感受野),解码器可以非常轻量化。SegFormer在保持高效率的同时,在Cityscapes和ADE20K上均取得了优异性能,成为实时Transformer分割的首选 。
OneFormer-通用分割架构
此前,MaskFormer和Mask2Former虽然统一了掩码分类范式,但在训练时仍需针对不同任务进行调整。
创新:
任务Token机制。OneFormer的核心创新在于引入了可学习的任务Token(Task Token)(例如 “The task is semantic segmentation”)。该Token作为查询条件输入模型,动态调节模型的注意力机制,使其在推理阶段能够根据指令在语义、实例或全景分割之间无缝切换。
统一训练:OneFormer仅需在全景数据集上训练一次,即可在所有三个任务的基准测试中取得SOTA性能,极大地简化了训练流程和模型部署成本。
InternImage-无敌参数量30B(?)
创新:重新用回卷积,但是这个参数量是不是也太大了点?
- 可形变卷积v3 (DCNv3):InternImage的核心算子是DCNv3。不同于ViT的全局自注意力(计算复杂度为二次方),DCNv3通过动态调整卷积核的采样位置来捕获长距离依赖,既保留了卷积的归纳偏置,又具备了类似Attention的自适应能力。
- 超大规模:InternImage成功将CNN扩展到了30亿参数规模,在COCO目标检测和ADE20K语义分割上均刷新了记录(ADE20K mIoU 62.9),证明了基于高级算子的CNN在基础模型时代仍有一席之地。
提示分割与SAM生态—>开放词汇分割
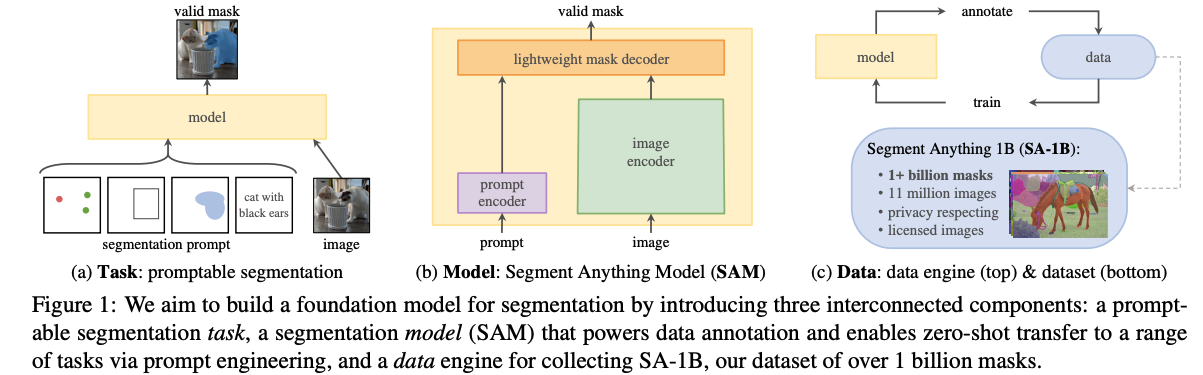
2023年4月,Meta AI发布的Segment Anything Model (SAM) 彻底改变了图像分割的研究方向。分割任务的目标不再仅仅是拟合某个数据集,而是构建能够响应任何提示(Prompt)的通用视觉基础模型。
SAM的出现,将任务目标从封闭集合的类别预测转变为开放世界的“提示分割”;再结合LLM,则催生了“推理分割”(Reasoning Segmentation),赋予了模型理解复杂隐含指令的能力。
[SAM cite:16088,ICCV2023]Kirillov, Alexander, et al. “Segment anything.” Proceedings of the IEEE/CVF international conference on computer vision. 2023.
[SAM2 cite:2606]Ravi, Nikhila, et al. “Sam 2: Segment anything in images and videos.” arXiv preprint arXiv:2408.00714 (2024).
SAM-基础模型
[!NOTE]
==为什么从SAM开始就叫Data Engine了?==
Data Engine:SA-1B,1100w张img+11b的mask。
超大数据集让SAM可以zero-shot泛化。
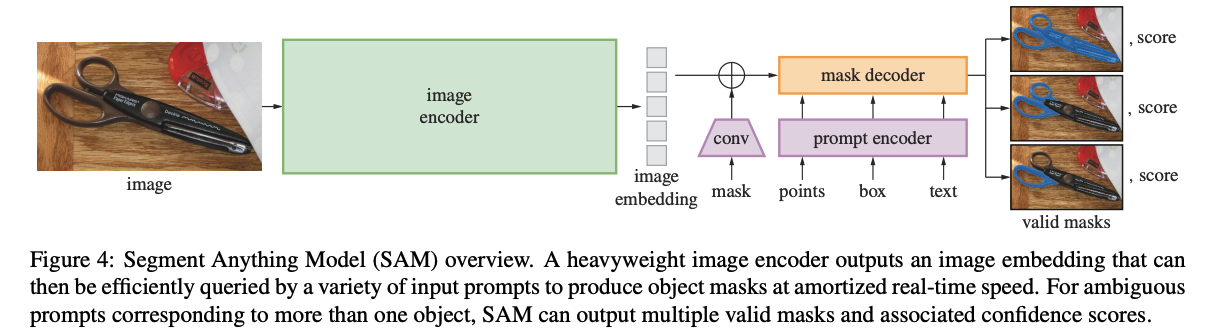
架构:
- 图像编码器:使用重型ViT(如ViT-H)处理图像,生成一次性图像嵌入。
- 提示编码器:轻量级模块,将点、框、文本等提示映射为向量。
- 掩码解码器:基于Transformer的轻量级解码器,能在毫秒级时间内根据提示和图像嵌入生成掩码。
歧义性处理:SAM承认分割的歧义性(例如,点击一个人的衬衫,是想分割衬衫还是整个人?),因此默认输出三个不同层级(整体、部分、子部分)的掩码。
基于SAM的改进“们”
SAM2-扩展至视频
- 流式记忆机制(Streaming Memory):SAM 2的核心突破在于引入了记忆库。当在视频的第一帧分割了一个物体后,模型会将该物体的特征存储在记忆库中。处理后续帧时,模型不仅关注当前帧,还会通过注意力机制查询记忆库,从而实现对目标在遮挡、形变下的持续追踪。(==相当于是增加了内存开销?==)
- 统一架构:SAM 2将图像视为单帧视频,从而用一套架构统一了图像分割和视频对象分割(VOS)。在SA-V视频数据集上的测试表明,其性能大幅超越了传统的VOS方法,且交互次数减少了3倍 。
HQ-SAM-改进细微处分割精度不足
- 高频Token:HQ-SAM不改变SAM的预训练权重,而是引入了一个可学习的“高质量输出Token”到掩码解码器中。这个Token专门负责捕获高频细节信息。
- 数据微调:利用HQSeg-44K高精度数据集进行轻量级微调,使其在保持零样本能力的同时,大幅提升了边缘贴合度(IoU提升显著)。
FastSAM-基于YOLOv8
现在都出到YOLOv12/13了
基于CLIP-融合文本和图片信息
SAM3 - 概念分割
我的疑问
为什么只有mIoU的一个指标,对于Dice重叠度算一个/准确分类与否也算一个?关于语义分割的评估指标上。