Tue Nov 11 2025 00:00:00 GMT+0800 (中國標準時間)
假设你是一个计算机视觉方面的专家,对于图像处理,强化学习,大模型等研究方向十分擅长。我想和你讨论一下我现在进行的研究课题,请指导一下我:我要解决的目标是图片中类与类之间的混合、重叠、覆盖的问题。具体来说,我是在食品场景中。在中餐中,作为十分常见的盖饭或是学校餐盘场景,经常会有不同的菜的边缘会混合在一起,甚至不只是边缘,而是混合的程度比较深。因为每一道中餐都是有不同的食材组成的,菜与菜之间可能含有相同的食材,或是比较相似的食材,这导致在边缘混合的情况下准确的定位并识别出不同的菜是十分困难的。因此我的目标就是在这种scenario下可以准确的识别菜品。目前我遇到的问题有:1.我的数据来源:现在有一个FoodDet100K的数据集,但是这个是一个目标检测的数据集,其类别是菜品的种类,而且由于每道菜都是被放在不同的碗里,所以不存在边缘混合的问题,我要以这个数据集作为我主要训练的数据集,此外,为了适用到边缘混合的情况下,我额外收集了一个数据集,是有关于图片中只有一个餐盘,餐盘中有数道混合在一起的菜品的2000张图片的分割数据集。我现在最终的输出是分割,可以分割出图片中的不同菜品。我不是理解的地方在于,这两个数据集的item/输出是不一样的,那么我要如何把这两个数据集利用起来?2.在框架的构建上,我本来的想法是利用DeepSeek-MoE的transformer结构+强化学习进行,但是我现在想是不是也可以加CLIP,可以将菜品名字+可能存在的食材作为文本信息输入模型,以便于获得多模态的信息帮助识别准确,比如 如果使用CLIP的话如何构架一个模型呢?MaskCLIP (ECCV2022)这种结构都是比较老了,有没有更新的模型可以借鉴使用,并帮我想想合理性。为了解决我上面提到的问题,我的框架应该如何设计比较好,以及相关的损失函数,是不是应该围绕边缘混合设计一些,还是说MoE分配一个专家是专门解决这个问题?
损失函数:
- 对于有像素级标注的数据(你的2000张分割数据集),直接使用分割损失(如交叉熵损失、Dice损失等)。
- 对于只有边界框的数据(FoodDet100K),我们可以将边界框转化为二值掩码(框内为1,框外为0),然后使用弱监督分割损失,例如,我们可以使用交叉熵损失,但只计算边界框内的区域。注意,边界框标注通常比像素级标注噪声更大,所以我们可以使用一个加权损失,降低边界框标注的权重。
- 关于边界感知损失,Dice损失是一种常用的分割损失,它计算预测掩码和真实掩码之间的重叠度,对于不平衡的分割任务(如边界通常只占很少的像素)有较好的效果。此外,可以额外添加一个边界损失,例如,通过计算预测边界和真实边界之间的距离(如Hausdorff距离)或使用边界加权的交叉熵损失。
具体来说,Dice损失的定义为:
Dice = 1 - (2 * |X ∩ Y| + smooth) / (|X| + |Y| + smooth)
其中X是预测掩码,Y是真实掩码,smooth是一个平滑常数。
边界感知损失可以通过以下方式实现:
- 首先从真实掩码中提取边界(使用边缘检测算法,如Canny或通过形态学操作)。
- 然后,我们可以计算一个边界权重图,在边界处的像素给予更高的权重。
- 在计算分割损失(如交叉熵)时,将这个权重图乘以每个像素的损失。
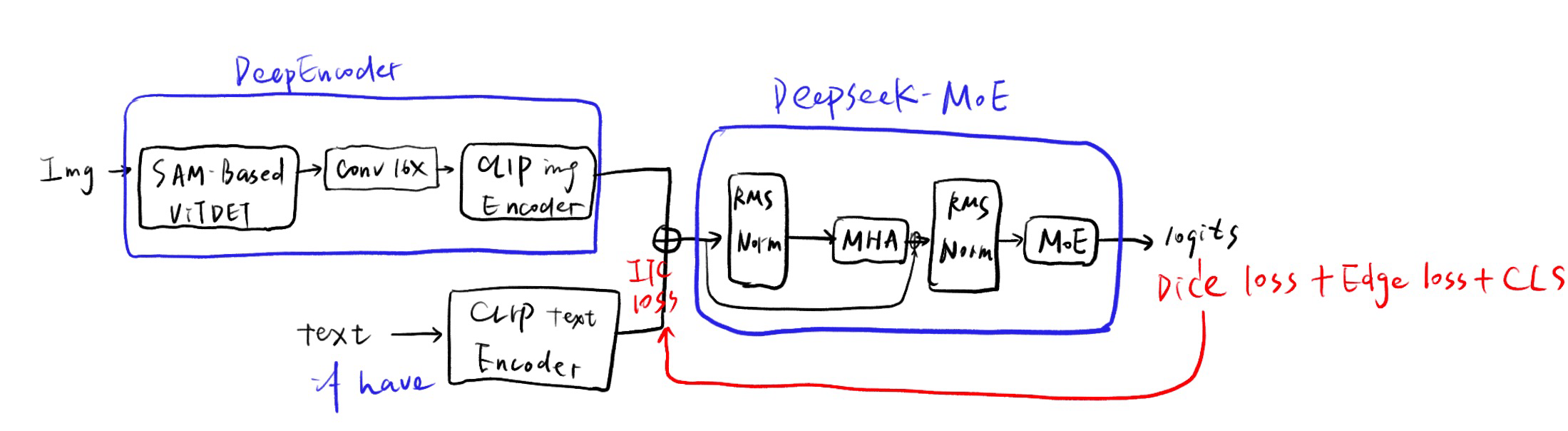
最小改造清单(在 FoodEdgeMoE 项目里动手)
- Encoder部分
- SAM:已接入 SamVitBBackbone,保持。
- Conv16x:按需替换成更强版(可加残差/多层)。
- CLIP image encoder:用 open_clip 真正的视觉编码,输出全局 img_emb。
- CLIP text encoder:用 open_clip 文本编码。文本构造:把图中所有菜品名拼成一句/一段描述(可附加“菜A的特征/食材,菜B的特征/食材…”),暂时作为单条 text 输入,得到 text_emb。
- ITC:你说多菜品文本不精确,可以先降权或关闭 (—itc-weight 0),等有更好的文本构造再开。
- DeepSeek-MoE替换
- 从 /model/DeepSeek-OCR/DeepSeek-OCR-master/deepencoder/ 里摘出 RMSNorm、MHA、MoE(shared/experts)模块,整理成一个独立文件(例如 foodedgemoe/deepseek_moe.py)。
- 在 model.py 中把现有的 MoEStub 换成 DeepSeek-MoE 结构(RMSNorm→MHA→RMSNorm→MoE)。输出用于 FiLM/后续 heads。
- Heads 与 Loss
- seg/edge/cls 头保持现状(已支持 dice/edge/cls)。
- Dice loss 你已经改成只对出现的类、排除背景,继续用。
- Edge loss 维持 Sobel 边界 → BCE。
- Class loss:多标签 BCE 已有。如果想让文本/ITC 弱监督菜品,可把 cls 权重点亮(如 0.2),ITC 低权或关掉。
- 数据与文本构造
- FoodSeg103 / UEC 的类别 id→类别名,需要一个映射表(可在
category_id.txt或自建字典)。 - 训练时在 collate 或 mapper 中,把 mask 的唯一类 id 转成菜名列表,拼接成文本描述,喂给 text encoder。这样每张图的文本就与标注一致(即便描述粗糙,也比空文本强)。
- 若文本太长,可限制最长 token。
- 训练/评估流程(保持简单)
- 继续用 FoodEdgeMoE 的 train_foodseg103.py / eval_foodseg103.py,改完模块后重新跑。
- CPU 会非常慢,尽量用 GPU;若只能 CPU,先用小尺寸、少步数验证链路。
- 可能的短板与修补
- ITC 不精准:先调低/关闭 ITC 权重,等有更好文本生成策略(比如按每类单独句子、多句拼接)再打开。
- 计算/显存:SAM + open_clip 较重,必要时减小输入分辨率或换轻量 clip 模型(ViT-B/32)。
- 数据缺少真实菜品描述:当前只能用类名或模板文本;更好的文本需要外部知识或生成式模型。
- 如果坚持在 OneFormer 上改
- 需要新建一个
META_ARCH,改数据 mapper 输出格式、改解码器/损失,全局侵入大,工作量远高于在 FoodEdgeMoE 里直接集成你的 DeepSeek 模块。建议放弃在 OneFormer 主干上硬改。
总结:最小成本是继续在 FoodEdgeMoE 里,把 MoE Stub 换成 DeepSeek-MoE,把 CLIP encoder 换成 open_clip 真模型,并在数据管线里自动生成菜品描述文本。ITC 可暂关/低权,先让 seg/edge/cls 收敛,再逐步加文本分支。需要我可以帮你把 DeepSeek-MoE 和 open_clip 接入的代码骨架补上,以及类名→文本的构造函数。