Thu Oct 30 2025 00:00:00 GMT+0800 (中國標準時間)
实验说明
数据
- metadata: new_metadata.csv
- HSI 原始文件目录: processed_npy/
- 有效样本数(过滤了无效 toxin_value): 200 样本
值得说明的是:此处的样本数量是因为内存空间不足,导致目前仅能运行200样本。昨天已对服务器空间进行整理,后续可以用全部样本进行测量。
- HSI 原始空间尺寸:多为 960×960(预处理会 resize 到 target_size)
- 目标尺寸:256×256
- CBAM 检测到的 common spectral channels: 600(preprocess_data 输出);实际用于训练时由 loader 返回的 channels = detected_input_channels(本实验自动使用该值构造模型)
- 注意:部分 .npy 文件存在 header/大小不一致(示例:6-22.npy),已在 loader 中做容错(记录 bad_npy.log,并在必要时填充/裁剪)
数据预处理
已统一并复用 CBAM_model.py 的预处理流程(preprocess_data):
- HSI:
- resize -> target_size (256×256)
- 统一通道数推断/重采样(使用 CBAM 的 channel inference / resample 逻辑)
- 全局 per-channel mean/std 计算并应用(Z-score 标准化) — 这保证 Fusion 与 CBAM 在 HSI 数值尺度上一致
- Fluor (Value_Raw):
- 计算并记录 mean/std,training 时可做标准化(preprocess_data 已计算并可返回 scaler)
- Toxin label:
- 计算并缓存 MinMax (或其他) scaler(preprocess_data 输出 label_scaler)
- RGB:
- 通过 metadata 尝试定位并读取图像(若找不到,返回全零张量);图像被 resize 到 target_size 并 ToTensor()
模型
选用了不同的encoder对各个模态的数据提取特征之后,进行特征融合。此处选择了晚期融合的四种方式。
- CBAMFusion: HSI 用 CBAM 卷积路径,RGB 用 ResNet18(fc 替换),Fluor 用小 MLP,late fusion(concat -> fc)
- SimpleFusion: 简单 late fusion(HSI-CNN + ResNet18 + Fluor-MLP -> concat -> classifier)
- AttentionFusion: 3 模态特征后用小注意力网络学习加权融合
- WeightedLateFusion: 可学习的模态权重(参数化向量 -> softmax)
实验配置
训练/验证划分:由 preprocess_data 返回(使用其默认划分策略)
1 | metadata_csv = "/Users/.../processed_npy/new_metadata.csv" |
实验运行结果
评估指标选用:MAE、RMSE、R²
训练时长:450min(例如:每 epoch 平均 3 分钟)
最佳验证 loss (MSE): 0.0006
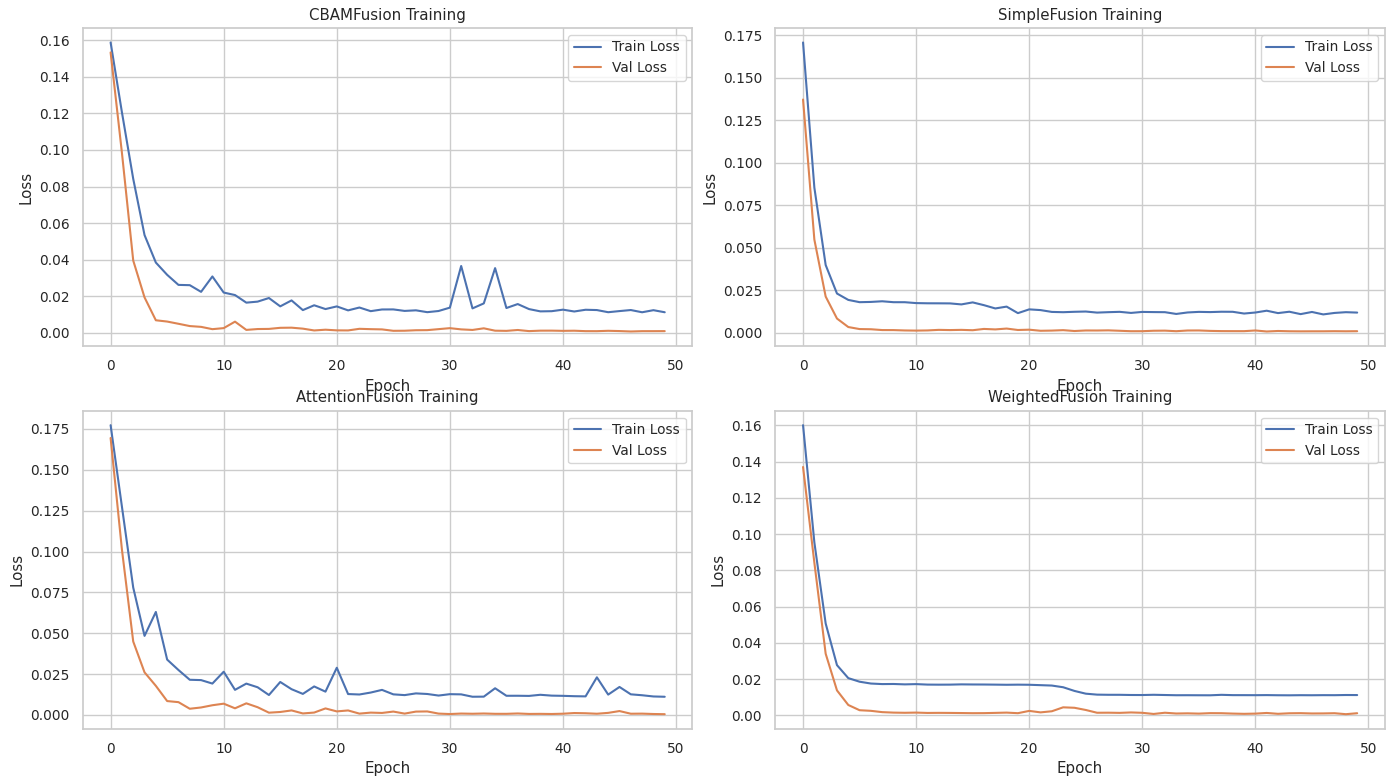
CBAMFusion | MAE: 4.0241 | R²: 0.9961 | RMSE: 4.6529
SimpleFusion | MAE: 3.5551 | R²: 0.9969 | RMSE: 4.1378
AttentionFusion | MAE: 2.7030 | R²: 0.9978 | RMSE: 3.4530
WeightedFusion | MAE: 3.2109 | R²: 0.9970 | RMSE: 4.0845
我现在需要做一个消融实验,也就是对三种模态的数据检测:高光谱,rgb,荧光值分别单独输入模型得到的结果,从三个模态中选两个得到的结果,以及三个模态全用得到的训练结果。
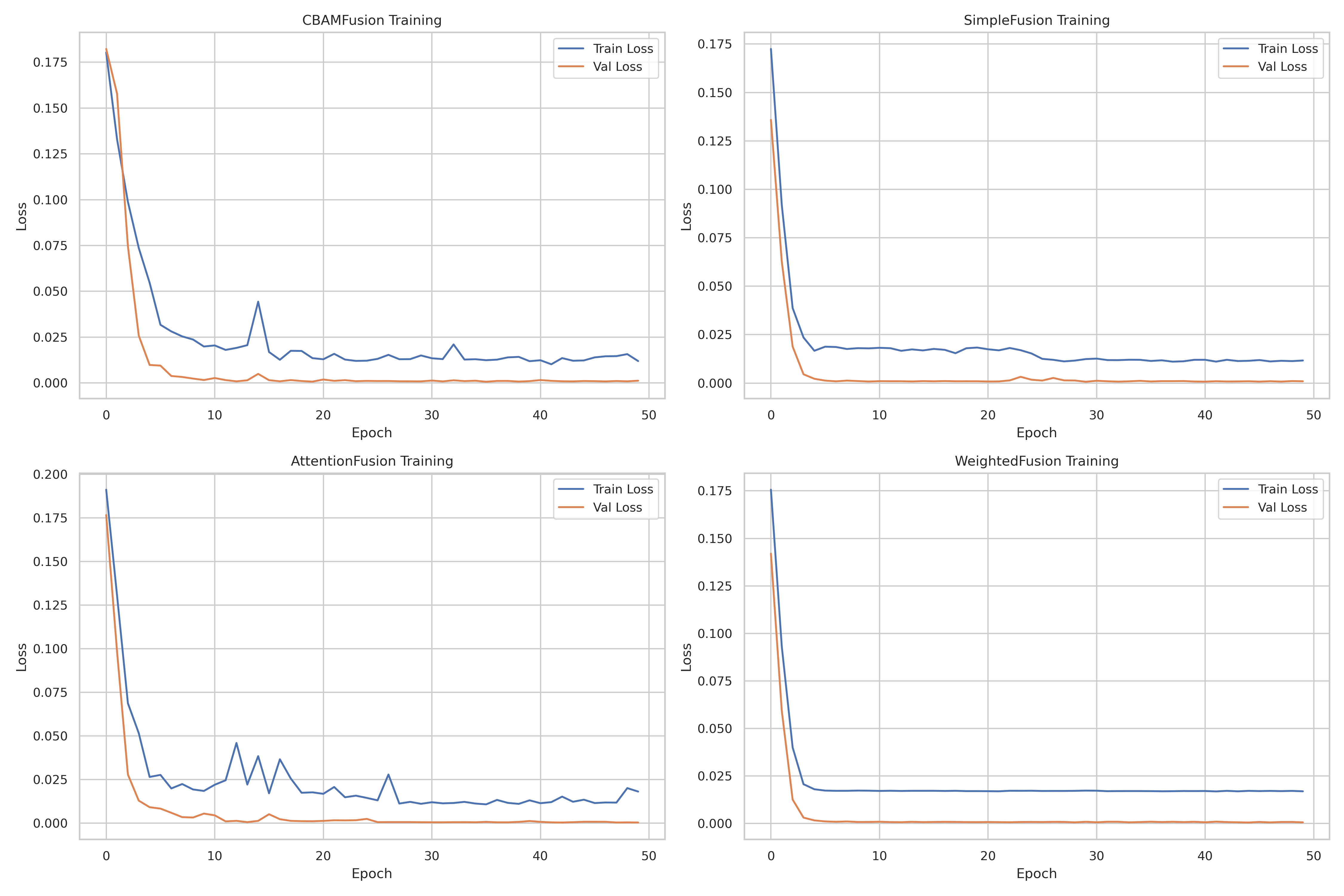
CBAMFusion | MAE: 3.5327 | R²: 0.9967 | RMSE: 4.2312
SimpleFusion | MAE: 3.6707 | R²: 0.9966 | RMSE: 4.3289
AttentionFusion | MAE: 2.5240 | R²: 0.9981 | RMSE: 3.2732
WeightedFusion | MAE: 2.9873 | R²: 0.9973 | RMSE: 3.8291
找
我的数据集是具有三模态的数据高光谱.spe+.hdr,荧光值(标量),以及原始rgb图像.bmp.假如说我想按照我的数据集来加载入这个I2MoE的方法,用I2MoE的方法在我的数据集上训练得到回归数值的结果。那么我首先需要在/Users/schwertlilien/Downloads/test/I2MoE-main/src/common/datasets中加载入我的数据集,其模态是HRF(hsi,rgb,flour)。预测结果是回归得到数值。然后再在train_transformer.py中加载我的数据集,然后在/Users/schwertlilien/Downloads/test/I2MoE-main/scripts/train_scripts/imoe/transformer中写入脚本,我是否就能成功运行?首先告诉我我想要得到结果“用I2MoE的方法在我的数据集上训练得到回归数值的结果。”这个的步骤是否正确,然后指导我一步步的做。我的数据集的数据处理部分你可以参考/Users/schwertlilien/Downloads/test/I2MoE-main/CBAM_model.py,以及/Users/schwertlilien/Downloads/test/I2MoE-main/Fusion.py,/Users/schwertlilien/Downloads/test/I2MoE-main/src/common/datasets/mosi.py中的内容,并告知我如何一步步完成我的目的。需要说明的是,因为我的数据是三模态,做的回归任务,因此我认为也可以借鉴:/Users/schwertlilien/Downloads/test/I2MoE-main/src/common/datasets/mosi.py中的def load_and_preprocess_data_mosi_regression(args)
再次训练了一下,得到的结果是:
🎯 WeightedFusion 训练完成!
⏰ 总用时: 1407.15 秒 (23.45 分钟)
📊 平均每轮用时: 28.14 秒
✅ WeightedFusion Results:
MAE: 315382.7500, R²: 0.2437, RMSE: 356854.2667
MODEL COMPARISON RESULTS
CBAMFusion | MAE: 260728.6562 | R²: 0.4745 | RMSE: 297479.2839
SimpleFusion | MAE: 225593.0156 | R²: 0.6269 | RMSE: 250650.9322
AttentionFusion | MAE: 184261.1094 | R²: 0.7401 | RMSE: 209189.9109
WeightedFusion | MAE: 315382.7500 | R²: 0.2437 | RMSE: 356854.2667
I2MoE:
Best model saved to ./saves/imoe/transformer/hrf_regression/seed_0_modality_HRF_train_epochs_100_val_loss_0.00.pth
Weight sum statistics: min=0.9999998807907104, max=1.0000001192092896
{‘model’: ‘Interaction-MoE-Transformer’, ‘lr’: 0.0001, ‘temperature_rw’: 1, ‘hidden_dim_rw’: 256, ‘num_layer_rw’: 1, ‘interaction_loss_weight’: 0.01, ‘modality’: ‘HRF’, ‘data’: ‘hrf_regression’, ‘gate_loss_weight’: 0.01, ‘train_epochs’: 100, ‘num_experts’: 16, ‘num_layers_enc’: 1, ‘num_layers_fus’: 1, ‘num_layers_pred’: 1, ‘num_heads’: 4, ‘batch_size’: 2, ‘hidden_dim’: 128, ‘num_patches’: 16}
[Val] Average Loss: 0.0000 ± 0.0000
[Test] Mean Absolute Error: 0.0045 ± 0.0000
无语了

一些训练结果:Epoch 57/100 | LR: 4.83e-05 | Train Loss: 0.0039 | Val Loss: 0.0004 | Val R²: 0.8296 | Trigger: 11/15
Epoch 58/100: 100%|███████████████████████████████████████| 5/5 [00:56<00:00, 11.40s/it]
Epoch 58/100 | LR: 4.65e-05 | Train Loss: 0.0041 | Val Loss: 0.0005 | Val R²: 0.7489 | Trigger: 12/15
Epoch 59/100: 100%|███████████████████████████████████████| 5/5 [00:54<00:00, 10.90s/it]
Epoch 59/100 | LR: 4.48e-05 | Train Loss: 0.0059 | Val Loss: 0.0005 | Val R²: 0.7174 | Trigger: 13/15
Epoch 60/100: 100%|███████████████████████████████████████| 5/5 [00:53<00:00, 10.79s/it]
Epoch 60/100 | LR: 4.30e-05 | Train Loss: 0.0063 | Val Loss: 0.0004 | Val R²: 0.8041 | Trigger: 14/15
Epoch 61/100: 100%|███████████████████████████████████████| 5/5 [00:54<00:00, 10.86s/it]
Early stopping triggered! No improvement for 15 consecutive epochs.
Training complete. Best model at epoch 46: R²: 0.8705, Loss: 0.0003
Toxin min=2139.00931444048, Toxin max=9499122.31743333
—- Final Model Evaluation —-
Final performance on test set:
MAE (original scale): 123147.8203
R² Score (original scale): 0.7876
Best model achieved R²: 0.8705 at epoch 46
[Seed 0/2] [Epoch 99/100] Task Loss: 1.90, Router Loss: 0.00 / Val Loss: 1.90, Val MAE: 2.41
[Seed 0/2] [Epoch 100/100] Task Loss: 1.87, Router Loss: 0.00 / Val Loss: 1.87, Val MAE: 2.39
再写一个PPT的,对结果进行总结
CBAM原模型:
Training complete. Best model at epoch 18: R²: 0.6562, Loss: 0.0002
Toxin min=2057.80681921, Toxin max=15012381.5119922
—- Final Model Evaluation —-
Final performance on test set:
MAE (original scale): 116817.9766
R² Score (original scale): 0.6562
Best model achieved R²: 0.6562 at epoch 18
CBAM fusion:144793.4844, R²: 0.6314, RMSE: 245337.0193
SimpleFusion:120648.1797, R²: 0.6279, RMSE: 246501.0411
120648.1797, R²: 0.6279, RMSE: 246501.0411
Attn:125674.0234, R²: 0.6734, RMSE: 230937.7103
MODEL COMPARISON RESULTS
CBAMFusion | MAE: 104706.8516 | R²: 0.6597 | RMSE: 235736.8306
SimpleFusion | MAE: 154869.4531 | R²: 0.6070 | RMSE: 253328.5654
AttentionFusion | MAE: 125674.0234 | R²: 0.6734 | RMSE: 230937.7103
WeightedFusion | MAE: 120461.5312 | R²: 0.6496 | RMSE: 239227.2487
子集测试+消融实验—>定位问题