Mon Oct 13 2025 00:00:00 GMT+0800 (中國標準時間)
目前有关于食品分割的相关工作
Liu, C.; Sheng, G.; Min, W.; Wu, X.; Jiang, S. Multi-View Edge Attention Network for Fine-Grained Food Image Segmentation. Foods 2025, 14, 3016. https://doi.org/10.3390/foods14173016
这个是针对FFoodSeg103/UECFoodComplete提出了一个网络,做的是闭源的分割。而且框架模型都是选择的已有模块。对比实验结果:
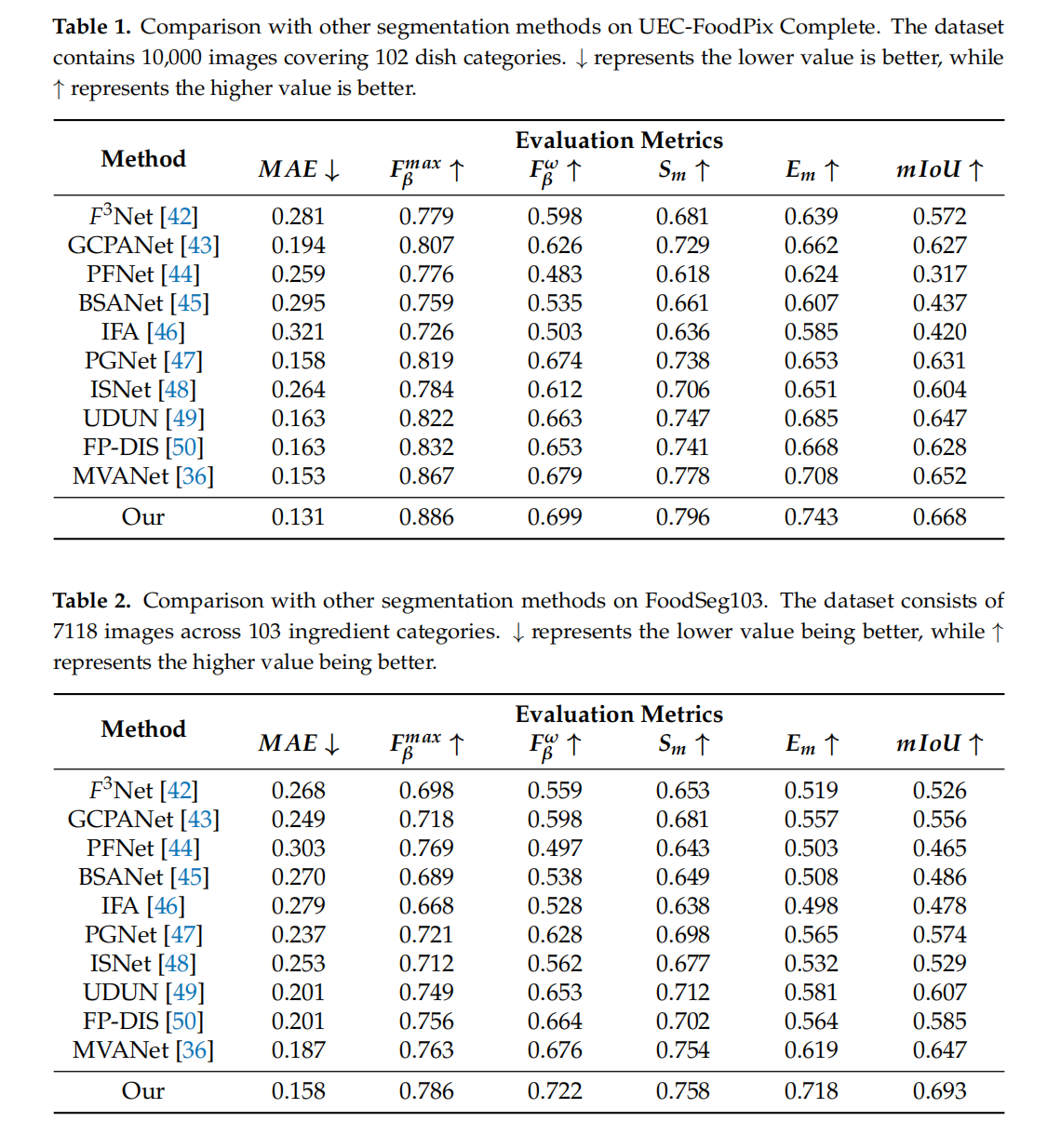
论文的实验设计围绕“细粒度食物分割”的核心痛点(边界模糊、食材多样、遮挡严重)展开:
- 指标选择上,用MAE衡量像素误差、$F_{\beta}$系列保障小食材完整性、$S_m/E_m$关注结构合理性、mIoU作为核心分割精度指标,形成全方位评估体系;
- 环境与超参数设置上,适配大尺寸图像训练(1024×1024、Batch Size=1、A800显卡),并通过消融实验验证各模块必要性,确保模型性能可解释;
- 数据集选择上,覆盖“食材级”(FoodSeg103)与“菜品级”(UEC-FoodPIX)场景,保证结果的泛化性,为后续 dietary logging(饮食记录)、nutritional analysis(营养分析)等应用提供可靠技术支撑。
一、评估指标
论文中用于评估细粒度食物图像分割性能的指标共6项,涵盖误差、综合性能、结构相似度及分割准确性等维度,具体定义与意义如下:
| 指标名称 | 符号/全称 | 核心含义 | 评价标准 | 在食物分割中的作用 | ||
|---|---|---|---|---|---|---|
| 平均绝对误差 | MAE(Mean Absolute Error) | 计算预测分割图与真实标签图(二值化)在像素级的绝对差值平均值,公式为: $MAE=\frac{1}{W\times H}\sum_{i=1}^{W\times H} |
Pred_i - GT_i | $ ($W$=图像宽度,$H$=图像高度,$Pred_i$=预测像素值,$GT_i$=真实像素值) |
数值越低越好(↓) | 衡量分割结果的整体误差水平,尤其反映食物区域与背景/容器边界的像素级偏差,如米饭颗粒、酱料等模糊边界的分割精度。 |
| 最大Fβ分数 | $F_{\beta}^{max}$ | 综合精确率(Precision) 和召回率(Recall) 的最大值,其中$\beta^2=0.3$(论文固定设置,侧重召回率权重),公式为: $F_{\beta}=\frac{(1+\beta^2)\times Precision\times Recall}{\beta^2\times Precision + Recall}$ |
数值越高越好(↑) | 评估模型对“小尺寸食物”(如坚果、蔬菜丁)的分割完整性,避免因食物遮挡或细碎形态导致的漏分割/误分割。 | ||
| 加权Fβ分数 | $F_{\beta}^{\omega}$ | 带权重的$F_{\beta}$分数,通过权重调整精确率与召回率的平衡,$\beta^2$同样为0.3 | 数值越高越好(↑) | 针对“混合食材”(如沙拉、炒饭)场景,更灵活地平衡“避免将背景误判为食物”(精确率)和“完整分割所有食材”(召回率)。 | ||
| 结构相似度 | $S_m$ | 同时从区域级(如食物整体轮廓)和目标级(如食物内部纹理)评估预测图与真实图的结构一致性,融合亮度、对比度和结构特征 | 数值越高越好(↑) | 衡量食物分割的“视觉合理性”,如蛋糕分层、披萨配料分布等结构是否与真实场景匹配,避免分割结果“形状正确但结构错乱”。 | ||
| 像素-图像对应度 | $E_m$(原文未展开全称,结合上下文推测为Pixel-Image Correspondence Metric) | 评估像素级分割结果与图像级语义(如“一盘炒饭”整体类别)的匹配度,反映局部像素分割与全局语义的一致性 | 数值越高越好(↑) | 解决“局部误分割”问题,如将餐盘边缘像素误判为食物时,$E_m$会降低,确保分割结果符合食物的整体语义逻辑。 | ||
| 平均交并比 | mIoU(mean Intersection over Union) | 计算预测区域与真实区域的“交集”与“并集”比值的平均值,公式为: $IoU=\frac{Pred\cap GT}{Pred\cup GT}$,$mIoU$为所有类别IoU的均值 |
数值越高越好(↑) | 分割任务的核心指标,直接反映食物区域的分割准确性,如牛排与酱汁、面条与汤汁等相邻食物的边界区分精度。 |
二、实验设置
1. 数据集设置
论文在2个主流公开食物分割数据集上验证性能,数据集参数差异如下表:
| 数据集名称 | 图像数量 | 类别数量 | 标签质量 | 训练/测试划分 | 图像预处理 |
|---|---|---|---|---|---|
| FoodSeg103 | 7118张 | 103种食材(如米饭、牛肉、番茄等) | 基于Recipe1M筛选,确保类别区分度,标签为像素级手动标注 | 训练集:4983张(含对应掩码) 测试集:2135张(含对应掩码) |
统一resize为1024×1024像素 |
| UEC-FoodPIX Complete | 10000张 | 102种菜品(如寿司、拉面、炒菜等) | 原始数据集标签为GrabCut半自动生成(边界不准),此版本由人工按规则修正,标签精度更高 | 训练集:9000张 测试集:1000张 |
统一resize为1024×1024像素 |
2. 硬件与软件环境
- 硬件配置:
- 显卡:NVIDIA A800(80GB显存,满足大尺寸图像(1024×1024)的批量处理需求)
- CPU:Intel(R) Xeon(R) Platinum 8358(2.60 GHz,用于数据预处理与模型参数初始化)
- 内存:8 GB RAM(保障数据加载速度)
- 存储:1TB SSD(用于存储数据集、模型权重及日志文件)
- 软件环境:
- 操作系统:Ubuntu 20.04 LTS(稳定的Linux环境,适合深度学习训练)
- 框架:PyTorch 1.12.0(主流深度学习框架,支持Transformer与自定义损失函数)
- 编程语言:Python 3.8(兼容PyTorch 1.12.0及其他依赖库)
3. 超参数设置
(1)训练超参数
| 超参数类别 | 具体参数 | 取值 | 设置原因 |
|---|---|---|---|
| 批量大小 | Batch Size | 1 | 因图像尺寸大(1024×1024),单张图像特征图占用显存高,Batch Size=1可避免显存溢出,同时保证训练稳定性。 |
| 损失函数 | Total Loss $L$ | $L=l_f+\sum_{i=1}^{5}(l_l^i+\lambda_g l_g^i+\lambda_a l_a^i)$ | - $l_f$:最终预测图损失(BCE+加权IoU) - $l_l^i$:局部特征损失,$l_g^i$:全局特征损失,$l_a^i$:注意力图损失 - 权重系数$\lambda_g=\lambda_a=0.3$(继承自MVANet,平衡多特征损失) |
| 损失组成 | 基础损失 | 二进制交叉熵(BCE)+ 加权IoU损失 | BCE解决类别不平衡(如“大盘菜中少量配菜”),加权IoU侧重边界区域损失,提升食物边缘分割精度。 |
(2)模型结构超参数
| 模型模块 | 核心超参数 | 取值/配置 |
|---|---|---|
| STViT backbone | 注意力机制 | 采用Super Token Attention(STA),每次计算仅使用token周围3×3超像素,降低计算复杂度 |
| MCLM/MCRM | 池化分支数 | 多粒度池化(Multi-grained Pooling)分支数$N$未明确,但继承MVANet的并行池化结构 |
| HQ-SAM Decoder | HQ-Token | 注入1个可学习的HQ-Token,融合STViT早期低维特征(细节)与晚期高维特征(全局) |
4. 消融实验设置
为验证各模块有效性,论文设计两组关键消融实验,设置如下:
(1) backbone对比实验(评估不同骨干网络的性能与效率)
- 实验目的:选择“精度-速度”平衡最优的骨干网络
- 对比对象:Swin-Transformer、SAM-Encoder、CAS-ViT、STViT
- 评估指标:mIoU(精度)、FPS(推理速度,帧/秒)
- 测速方法:
- 先进行10次无计时推理(热身,消除GPU初始化干扰)
- 再进行100次连续推理,计算总时间并取平均值
- 测速前同步GPU计算流,确保时间精度
- 结果:STViT最优(FoodSeg103上mIoU=0.693,FPS=6.3),兼顾精度与速度,最终选为骨干网络。
(2)核心模块消融实验(验证Multi-View、MCLM、MCRM、HQ-Token的作用)
- 实验基准:仅保留Multi-View策略的模型(无MCLM、MCRM、HQ-Token)
- 增量验证:依次添加模块,观察MAE与mIoU变化,结果如下:
| 模型配置 | Multi-View | MCLM | MCRM | HQ-Token | UEC-FoodPIX Complete(MAE/mIoU) | FoodSeg103(mIoU) |
|---|---|---|---|---|---|---|
| 基准模型 | √ | × | × | × | 0.179 / 0.594 | - |
| 基准+MCLM | √ | √ | × | × | 0.171 / 0.641 | - |
| 基准+MCRM | √ | × | √ | × | 0.173 / 0.633 | - |
| 基准+MCLM+MCRM | √ | √ | √ | × | 0.169 / 0.652 | - |
| 完整模型(全加) | √ | √ | √ | √ | 0.158 / 0.667 | 0.693 |
- 关键结论:
- MCLM(多视图互补定位模块)对定位精度提升最显著(mIoU+4.7%),负责准确识别食物区域位置,过滤背景噪声;
- MCRM(多视图互补细化模块)侧重细节优化(如食物纹理),与MCLM存在协同作用(两者结合mIoU高于单独添加);
- HQ-Token进一步提升边界精度(mIoU+1.5%),解决复杂形状食物(如环形甜甜圈、带籽水果)的分割漏洞。