2025-9-7
1. 详细的标注规则手册准则
- 准则一:全景分割原则 (The Panoptic Principle)
- 图像中的每一个像素点都必须被赋予且仅被赋予一个类别标签和实例ID。
- 这意味着最终的标注结果中,不同物体的掩码(mask)绝不能重叠 1。这完美符合食物在餐盘中的物理现实。
- 准则二:标注食材,而非菜品 (Annotate Ingredient, Not Dish)
- 标注员在为某个区域选择标签时,应选择其基础食材类别(例如
pork、cauliflower、lotus_root),而不是菜品名称(如guo_bao_rou)。 - 菜品名称将通过后续的属性进行标注。
- 标注员在为某个区域选择标签时,应选择其基础食材类别(例如
- 准则三:区分“物体(Things)”与“材料(Stuff)”
- 物体 (Things):指那些可数的、有明确独立形态的个体 1。
- 示例:图片3中的每一块锅包肉、每一朵花菜;图片2中的鸡腿、煎蛋。
- 操作:每一个“物体”都应被标注为一个独立的实例。
- 材料 (Stuff):指那些不可数的、无定形的区域 1。
- 示例:所有图片中的
rice(米饭);图片2中右下角的炒三丁(mixed_vegetable_stir_fry);流淌的酱汁。 - 操作:整个连续的“材料”区域应被标注为一个实例。
- 示例:所有图片中的
- 物体 (Things):指那些可数的、有明确独立形态的个体 1。
- 准则四:处理混合菜肴的决策流程
- 情况A:如果混合物中的主要成分大块且可分,则应尽力将它们作为独立的“物体(Things)”进行标注。
- 示例:图片3中的“腊肉炒藕丁”。标注员应分别圈出每一块可辨认的
cured_pork(腊肉)和lotus_root(藕丁)。
- 示例:图片3中的“腊肉炒藕丁”。标注员应分别圈出每一块可辨认的
- 情况B:如果混合物中的成分已高度融合、细小且不可分,则应将整个区域作为一个单一的“材料(Stuff)”实例进行标注。
- 示例:图片2中的“炒三丁”。应将整个区域标注为
mixed_vegetable_stir_fry,并在属性中注明其主要成分。
- 示例:图片2中的“炒三丁”。应将整个区域标注为
- 情况A:如果混合物中的主要成分大块且可分,则应尽力将它们作为独立的“物体(Things)”进行标注。
- 准则五:处理遮挡与覆盖的图层逻辑
- 标注逻辑:当一个物体(如图片2的鸡腿)遮挡了另一个物体(煎蛋)时,标注员应尽力将被遮挡物体的轮廓补全,画出其逻辑上完整的形状。这是为了给模型提供物体完整形态的学习信号。
- 最终结果:在生成最终的无重叠掩码图时,系统会根据图层顺序解决冲突。对于重叠区域的像素,只保留最上层物体的标签。因此,最终数据仍然严格遵守“准则一”。
- 准则六:最小尺寸原则 (Minimum Size Rule)
- 忽略过于微小、无法清晰辨认的食材碎屑。例如,可以设定一个经验阈值,如“任何小于10x10像素的区域都不予标注”。
- 示例:图片1中牛肉饭上的芝麻(
sesame_seed)应被忽略。
- 准则七:基础类别与属性的划分
- 基础类别 (Base Category):用于区分食材的本质来源,特别是当它们在视觉上有稳定且显著的差异时。
- 示例:
pork(猪肉)、pork_trotter(猪蹄)、pork_ear(猪耳朵)应是不同的基础类别。
- 示例:
- 属性 (Attribute):用于描述由后期加工(如切法、烹饪方式)导致的视觉变化。
- 示例:肉片、肉末、肉块,其基础类别都是
pork,但通过属性"form": "slice"、"form": "mince"、"form": "chunk"来区分。
- 示例:肉片、肉末、肉块,其基础类别都是
- 基础类别 (Base Category):用于区分食材的本质来源,特别是当它们在视觉上有稳定且显著的差异时。
2. 如何高效标注繁复的Attribute?
您完全正确,如果让标注员为每一个分割出的物体手动填写一长串属性,效率会非常低下且容易出错。解决方案在于优化标注工具和工作流程。
高效的属性标注工作流:
- “先分割,后赋属性”:标注员首先专注于完成一道菜中所有食材实例的分割任务。
- 示例:在图片3中,标注员先一口气圈出“腊肉炒藕丁”这道菜里所有可见的腊肉块和藕丁。
- 批量选择与批量赋值:现代标注平台(如Label Studio, CVAT)都支持多选功能。标注员在完成分割后,可以框选或点选所有属于“腊肉炒藕丁”的实例(包括所有的腊肉块和藕丁块)。
- 操作:选中所有相关实例后,在属性面板中一次性为它们赋予共享的属性。
- 示例:为所有选中的腊肉和藕丁,一次性填入
"dish_context": "cured_pork_with_lotus_root"和"cooking_method": ["stir-fried"]。
- 分步细化:在批量赋予了共享属性后,再对不同基础类别的实例进行细化。
- 操作:取消全选,然后只选中所有的腊肉块,为它们批量赋予
"category_id": "cured_pork"和"form": "dice"。接着,再选中所有的藕丁块,为它们批量赋予"category_id": "lotus_root"和"form": "dice"。
- 操作:取消全选,然后只选中所有的腊肉块,为它们批量赋予
- 利用工具特性:
- 预设与下拉菜单:在标注工具中,将常用的属性值(如
stir-fried,deep-fried,slice,dice)设置为下拉菜单选项,而不是让标注员手动输入字符串,这能极大减少拼写错误。 - 快捷键/模板:为常见的菜品组合创建属性模板。例如,可以创建一个“锅包肉”模板,当标注员选择这个模板时,
dish_context,cooking_method等属性会自动填充。
- 预设与下拉菜单:在标注工具中,将常用的属性值(如
通过这种“分层、批量”的工作流,可以将原本需要上百次点击和输入的任务,简化为几次批量操作,效率和准确性都会得到质的提升。
3. 实现最终目标的完整步骤(路线图)
这是一个从零开始构建您的数据集并达到最终目标的完整路线图。
阶段一:基础设计与定义 (Foundation & Scoping)
- 步骤1:确定基础类别列表 (Finalize Base Category List)
- 基于中餐菜谱,并参考您现有的图片,列出所有需要识别的基础食材。
- 应用我们在第一个问题中讨论的准则,决定哪些(如猪蹄、猪耳)应成为独立类别,哪些(如肉片、肉块)应通过属性区分。
- 为每个类别确定其是“物体(Things)”还是“材料(Stuff)”,即
isthing标志 2。
- 步骤2:确定属性模式 (Finalize Attribute Schema)
- 最终确定您需要的属性字段列表,例如:
dish_context,cooking_method,form,sauce_coverage,is_staple,constituents。 - 为每个属性字段定义可能的取值(例如,为
form定义slice,dice,chunk,shred,mince等)。
- 最终确定您需要的属性字段列表,例如:
阶段二:工具准备与试点标注 (Tooling & Pilot)
- 步骤3:配置标注平台 (Set Up Annotation Environment)
- 选择一个支持全景分割和自定义属性的标注平台(如CVAT, Label Studio, Encord)。
- 将您在步骤1和2中定义的类别和属性模式配置到工具中(创建下拉菜单、文本框等)。
- 集成半自动分割工具(如SAM)以加速掩码绘制。
- 步骤4:撰写标注手册并进行试点 (Create Manual & Run Pilot)
- 将第一部分总结的“详细标注规则”整理成一份图文并茂的PDF文档。
- 选取10-20张具有代表性的复杂图片,让2-3名核心标注员按照手册进行标注。
- 关键:开会对照他们的标注结果,讨论所有不一致的地方,并根据讨论结果更新和澄清标注手册。这个迭代过程是保证最终数据质量的生命线。
阶段三:规模化生产与质检 (Full-Scale Production & QA)
- 步骤5:全面开展标注 (Annotate the Dataset)
- 将所有数据分配给标注团队,按照最终版的标注手册和高效工作流进行大规模标注。
- 步骤6:质量保证 (Quality Assurance)
- 由一位经验丰富的审核员或您自己,对已完成的标注进行抽样检查(例如,随机检查15%的数据)。
- 对发现的系统性错误进行记录,并反馈给整个标注团队,进行纠正和再培训。
阶段四:数据导出与模型训练 (Data Export & Model Training)
- 步骤7:导出为COCO-Panoptic格式 (Export to COCO-Panoptic Format)
- 从标注平台导出所有标注。您将得到两部分核心产出:
- PNG掩码文件:每张原图对应一个PNG文件,像素值代表实例ID。
- JSON标注文件:一个大的JSON文件,包含了所有图片的元数据、类别定义以及每个实例ID对应的语义信息(包括您自定义的
attributes)2。
- 从标注平台导出所有标注。您将得到两部分核心产出:
- 步骤8:训练分割模型 (Train Segmentation Model)
- 利用导出的高质量数据集,您可以开始训练先进的全景分割模型。
- 由于您的数据结构设计,模型将自然地学习到食材的视觉特征以及它们在菜品上下文中的组合关系。
- 步骤9:支撑下游任务 (Enable Downstream Tasks)
- 营养评估:利用无重叠的分割掩码估算体积和重量。
- VQA:利用JSON文件中的结构化属性,自动生成大量的(问题,答案)对来训练VQA模型。例如,通过查询
dish_context为"guo_bao_rou"且cooking_method包含"deep-fried"的实例,可以自动生成问答对(“锅包肉是炸的吗?”,“是”)。 - 开放词汇/零样本识别:您的数据集鼓励模型学习可组合的视觉概念(
pork+deep-fried),为识别训练集中未见过的新菜品(如“炸鸡排”)打下了坚实的基础。
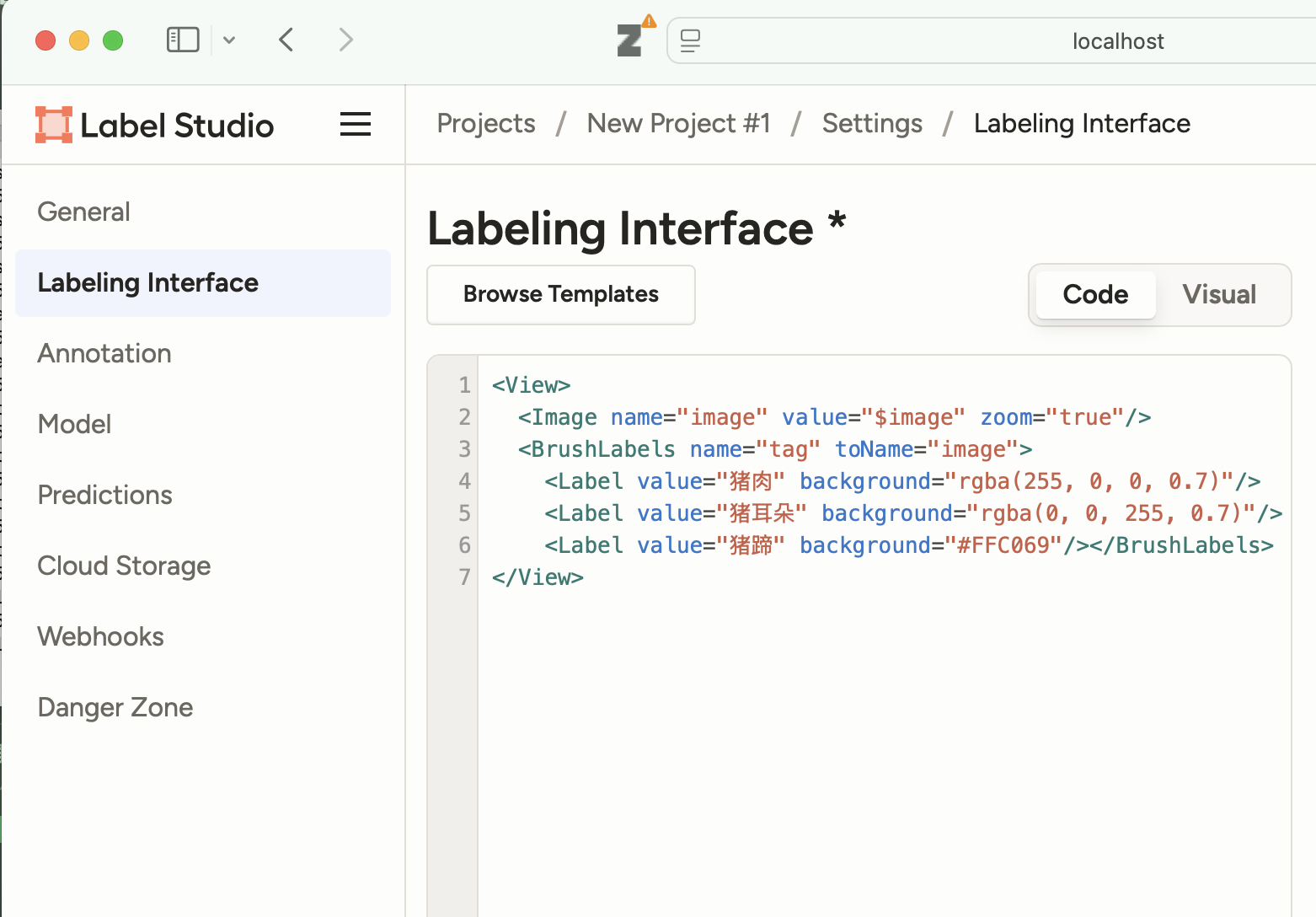
使用Label-Studio
此处上传所有的Label。
XML