2025-9-1
有时候深刻地感觉自己怀有罪孽,主要体现在:浪费食物的时候、直接丢弃没有喝完的水时。
好吧,写这段文字的时候,我刚丢掉了我喝了半杯的咖啡。阿门。
话说回来了,开始看论文了。
目前做食品分割数据集存在的难点:
- 缺乏高质量的、细粒度的成分标签&像素级的位置掩码 数据集。目前存在的数据集要么就是成分标的很粗糙、要么就是数据量太小。
- 食品外观的变化,导致了很难去识别、定位其在食物图片中的类别和位置。
- 长尾分布:可以说是二八定律吗?20%的食材会常常出现。
在写论文的时候需要先定义什么是食品图像分类/分割。具体上有什么区别:更复杂、识别出图片中的每个成分类别及其掩码。
Food相关数据集
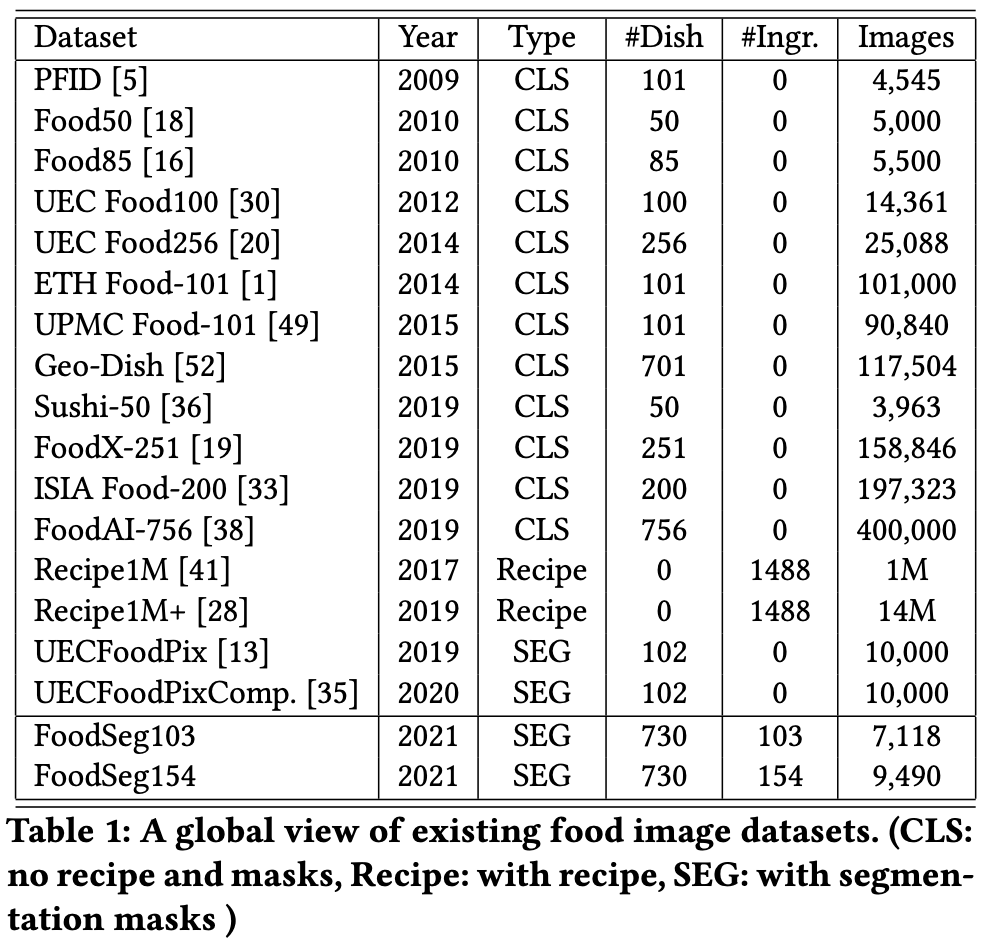
识别:
- [ ] Food101, 101k images, 101 categories.
- [ ] UEC Food100, 15k images, 100 categories.
- [ ] ISIA Food500, 400k images, 500 categories.
多模态:
- [ ] Recipe 1M, 900k images, 1 million recipes.(常用于多模态学习)
- [ ] Recipe 1M+, 13 million+ images.
分割(菜品级,未细致到食材级):
- [ ] UECFoodPix, 10k images, 102 categories.
- [ ] UECFoodPixComplete
FoodSeg103/154
作者自己说是“the first and the largest ingredient-level dataset for fine-grained food image segmentation.”
在这篇paper中也使用了food computing的概念。他们认为food computing的重要目标之一就是自动识别不同类型的食物、并对其营养和热量值进行分析。
数据集贡献:为了便于细粒度的食物图像分割,构建了FoodSeg103/154(103个成分类➡️7,118张西餐图像, 154类➡️额外的2,372张亚洲食物图像)。在实验中,使用Food Seg103进行域内训练和测试,使用Food Seg154中的附加集进行域外测试。
数据集构建
源数据集:我们使用Recipe1M作为源数据集。该数据集包含900k张带有烹饪指令和食材标签的图像,用于食品图像检索和食谱生成任务。
类别:首先,我们统计了所有成分类别在Recipe1M中的频率,其中涉及到1.5k种成分类别,大部分成分不容易被清楚分割。因此,我们只保留前124个成分类别(随着进一步细化,这个数字变为103),并在不属于上述124个类别的情况下将成分分配到”其他”类别。 最后,我们将这些类别归为14个超类类别,例如,Main 是一个超类类别,涵盖了面条和米饭等更细粒度的类别。
图像选择规则:在每个细粒度成分类别中,基于以下两个标准对Recipe1M图像进行采样,最终获得了7,118张标注掩码的图像。
- 图像应包含至少两个成分(具有相同或不同的类别)但不超过16个成分;
- 配料应在图像中可见且易于标注。
注释成分标签和掩码
给定上述图像,下一步需要注释分割掩膜,即覆盖不同成分像素位置的多边形。 这项工作包括掩码标注和掩码精化步骤。
注释:聘请一个数据注释公司来执行掩码注释。对于每幅图像,人类注释工作者首先识别图像中成分的类别,并为每个成分标注合适的类别标签,并绘制像素级掩膜。我们要求标注者忽略图像中面积小于5 %的小区域(即使它可能含有某些成分)。
这样看我们忽略出现极少的食材可能是合理的。
细化:从注释公司收到所有掩码后,进行整体细化。 我们遵循三个精化标准:
- 纠正错误标记的数据;
- 删除分配给少于5张图片的不受欢迎的类别标签,
- 合并视觉上相似的成分类别,例如橙子和柑橘。
合并的理由是???没有交代。
精化后,我们将125个成分类别的初始集合减少到103个。注释和完善工作历时一年左右。
在图2 ( a )中,我们给出了一些简单的情况,其中成分的边界是清晰的,图像成分并不复杂。在图2 ( b )和( c )中,我们展示了图像中成分区域重叠、成分复杂的一些困难情况。
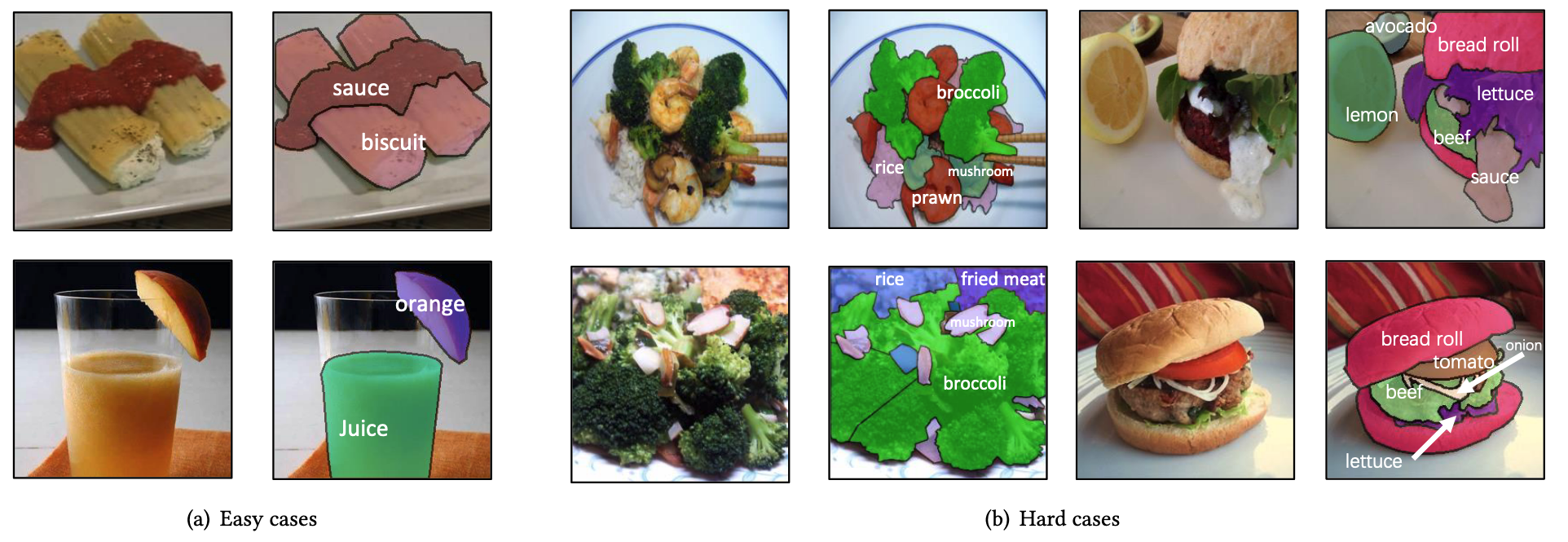
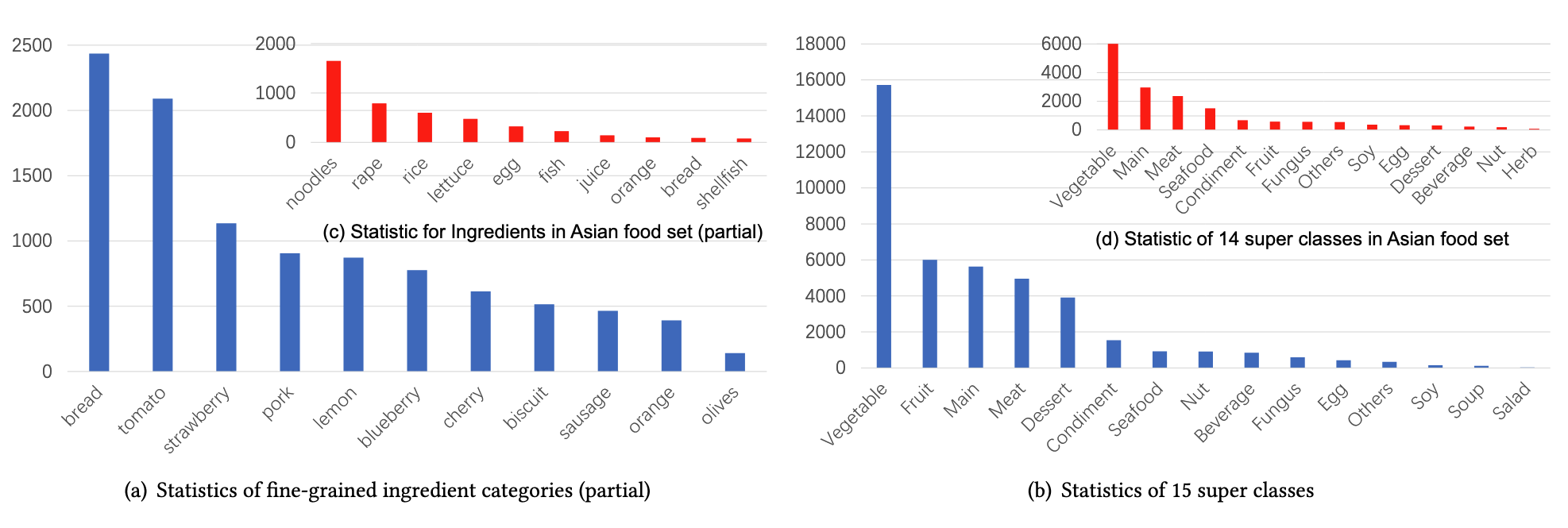
图3显示了细粒度成分类别和超类类别的分布情况。图3 ( a )和图3 ( c )显示了由于页限制对类别的小子集的部分统计。在发布数据集时将公布完整的统计数据。
用于实验-参数设置
数据集设置:在我们的实验中,我们使用Food Seg103进行域内训练和测试,使用额外的亚洲食物集进行域外测试。我们按照7:3的比例将Food Seg103数据集随机分为训练集和测试集两部分。我们的训练集包含4,983张包含29,530个成分掩膜的图像,而测试集包含2,135张包含12,567个成分掩膜的图像。对于ReLe M训练,我们使用1M +的训练集学习食谱表示(训练时隐藏Food Seg103中的测试图像)。
分割器设置:我们基于两种类型的视觉编码器进行实验:基于卷积神经网络的Res Net-50 [ 15 ]和基于视觉转换器的Vi T-16 / B [ 12 ]。 ResNet50网络由ImageNet - 1k [ 10 ]上的预训练模型初始化而来,被广泛应用于多个视觉任务[ 4、24、37 ]。ViT-16 / B [ 12 ]是一个基于Transformer的模型,它是由ImageNet - 21k上的预训练模型初始化而来。ViT-16 / B包含12个带有12头自注意力模块的Transformer编码器。我们使用双线性插值方法重新初始化预训练的位置嵌入。在本文中,我们使用了三种类型的分割器:CCNet [ 17 ],FPN [ 22 ]和SeTR [ 54 ]。CCNet和FPN是基于ResNet - 50的,而SeTR是基于ViT - 16 / B的。值得注意的是,SeTR从第12个变压器编码器中提取特征图,然后使用两组卷积层进行预测。分割器的其他组件遵循默认设置,随机初始化。
ReLeM设置:我们在ReLeM中使用了两种类型的视觉编码器:ResNet - 50和ViT - 16 / B,它们遵循与分割器相同的设置。在文本预处理阶段,我们使用了文献[ 29 ]中预训练权重的跳跃指令模型。
ReLeM(Recipe Learning Module x)
多模态、pre-training、知识迁移
方法:以word-embedding的方式将食物食谱数据与食物图像的视觉特征融合。通过这种方式,它迫使出现在不同菜肴中的食材的视觉表示通过公共word-embedding(从食材的标签及其烹饪说明中提取)使其外观在特征空间中”相连”。
Baseline:Pyramid,ViT,

第二行的图片展示了识别食材(Ingredient)的难点:食材的颜色、形状会发生改变;同时也会与其他种类的食材接近。例子是:不同状态下的菠萝、以及与其相似的土豆。
框架
我们的食物图像分割框架由两个模块组成:食谱学习模块和图像分割模块。对于ReLeM,我们将食谱信息编码到食物图像的视觉表征中。我们使用余弦相似度来计算两个不同模态模型之间的距离,并加上一个语义损失。训练完成后,我们使用训练好的编码器对分割器的编码器进行初始化。分割器的解码器使用随机初始化的分割掩码进行训练。
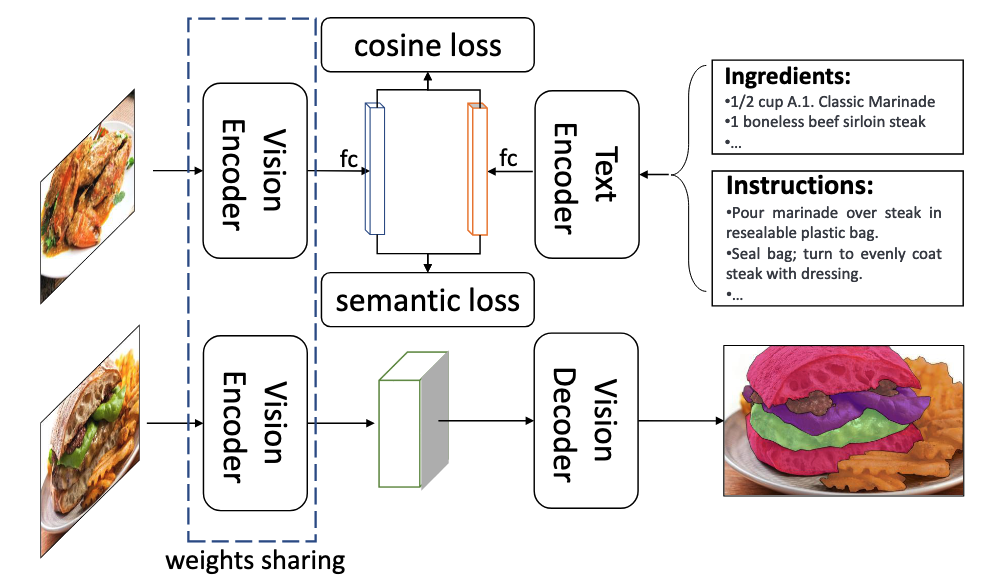
最终优化目标:
其中$\phi$表示分割器的Decoder。$v_1,v_2$表示同一食材的视觉表示;$r_1,r_2$是包含此食材的不同菜品(word-embedding)。此式子想表示的意思是最终得到的分割结果,同一食材+食谱之间的距离要小于只有食材信息之间的距离。也就是表示:食谱的存在能够有效缩小同一食材之间的距离。
其中,$v$是同一图片的视觉表示、$t$是同一图片的文本表示。
$L_{\text{cosine}}((v, t), y)$ 余弦损失函数:$y$ 是一个标签,用于指示 $v$ 和 $t$ 是否来自同一个食谱, $y = 1$ 表示来自同一个食谱,$y=-1$ 表示来自不同食谱。
- 当 $y = 1$ 时,$L_{\text{cosine}}((v, t), y)=1 - \text{cosine}(v, t)$。这里 $\text{cosine}(v, t)$ 是计算向量 $v$ 和 $t$ 的余弦相似度,其值范围在 $- 1$ 到 $1$ 之间,值越接近 $1$ 表示两个向量越相似。那么 $1 - \text{cosine}(v, t)$ 就是希望当 $v$ 和 $t$ 来自同一食谱时,它们的余弦相似度尽可能大(接近 $1$ ),这样损失 $L_{\text{cosine}}$ 就尽可能小(接近 $0$ )。
- 当 $y = - 1$ 时,$L_{\text{cosine}}((v, t), y)=\max(0, \text{cosine}(v, t) - \alpha)$ ,其中 $\alpha = 0.1$ 是一个设定的边界参数。这意味着当 $v$ 和 $t$ 来自不同食谱时,希望它们的余弦相似度小于 $\alpha$ ,如果 $\text{cosine}(v, t) \leq \alpha$ ,则损失为 $0$ ;如果 $\text{cosine}(v, t)>\alpha$ ,损失就等于 $\text{cosine}(v, t) - \alpha$ ,即希望不匹配的图片视觉和文本表示的余弦相似度不要过高,超过界限就会产生损失。
$L_{\text{semantic}}((v, t), u_v, u_t)$ 语义损失函数$u_v$ 和 $u_t$ 分别表示 $v$ 和 $t$ 对应的语义类别。
- $L_{\text{semantic}}((v, t), u_v, u_t)=\text{CE}(v, u_v)+\text{CE}(t, u_t)$ ,这里 $\text{CE}$ 通常表示交叉熵(Cross - Entropy)。衡量向量 $v$ 与其语义类别 $u_v$ 以及向量 $t$ 与其语义类别 $u_t$ 之间的差异,通过将这两部分交叉熵相加得到总的语义损失,目的是让同一图片的视觉和文本表示都能与各自对应的语义类别很好地匹配,从而降低语义损失。
由于Recipe1M不包含特定的语义标签(即,菜名),他们通过选择其菜谱标题中出现频率最高的菜名为其定义了2000个语义标签。
预处理:每个食谱都包含食材和烹饪说明。在输入到文本编码器之前,预处理步骤一般都需要将原始文本中的成分和指令编码到固定长度的向量中。此论文的方法是通过去除冗余的单词从原始食谱数据中提取有用的成分和指令文本。对于每个成分,使用双向LSTM学习一个word2vec表示。由于指令序列可能很长,LSTM很难对其进行编码,这是由于梯度消失问题。 根据先前的工作,我们用跳跃指令对指令进行编码,以生成具有固定长度的特征向量。
文本编码器(Text Encoder):文本编码器是一个从配料标签和烹饪说明中提取文本知识的通用模块。我们使用了两种类型的文本编码器:基于LSTM的编码器和基于Transformer的编码器。对于基于LSTM的方法,我们使用双向LSTM编码成分特征,使用LSTM编码指令特征。对于基于Transformer的模型,我们使用了两个轻量级Transformer,每个轻量级Transformer包含2个具有4头自注意力模块的Transformer层。
视觉编码器(Vision Encoder):ReLeM中使用的视觉编码器旨在从输入图像中提取视觉知识,权重将初始化分割器中的视觉编码器。此文使用了两种视觉编码器:基于CNN的ResNet-50和基于ViT的ViT-16/B。