2025-4-29
昨天跑了几个实验,得到了如下的结果:


detectron2可以做语义分割,但是对于食物(food)是整体的,不会细分成“鸡腿”“土豆”“米饭”等细分类。
至于想分割出不同的菜品,据GPT所说有下面的三种方法:
| 方法 | 说明 | 难度 |
| ———————————————————————- | ———————————————————————— | —————————————————- |
| 1. 微调(Fine-tune)detectron2 | 用自己标注的“不同菜”的数据,在 mask r-cnn 上微调 | ⭐⭐⭐(中等,几小时可以搞定) |
| 2. 自己训练新的分割模型 | 从零训练分割网络(比如 DeepLab、U-Net) | ⭐⭐⭐⭐(较难,需要数据+经验) |
| 3. 使用大模型(如 SAM, Segment Anything Model) | 直接用 SAM,给一个提示,就能自动分出不同菜块 | ⭐(超简单,但需要多点推理和预处理) |建议方法:
- SAM+分类器:先使用SAM分块、再用分类器识别每一块是什么菜;
- 微调Detectron2的Mask-RCNN(使用餐盘已标注照片)
已有方法调研
1. 菜品浪费度检测
普京, 祝诗平, 苗宇杰, 等. 基于图像语义分割的菜品浪费度检测[J]. 西南大学学报 (自然科学版), 2023, 45(4): 189-200.

“本实验训练集的数据进行了增强(图5),对训练集的图片以及标签图片同时旋转任意角度,来模拟不同角度下的拍摄效果[24];改变图像的亮度信息,对图像进行色彩抖动,来模拟不同光照条件下的拍摄效果.最终,训练集的数据扩大为原来的3倍,共为7320张,包含24489个菜品样本.”
这就很扯。好了,说回这个论文:主要是通过吃完前后的mIoU来检测浪费度。至于细节上、会更偏向于应用?(因为图片都是俯拍的,因此会涉及到一个物理建模,得到实际的食物残留多少的问题),然后神经网络这块就是用的FFN/Swin Transformer,没啥特别的。
我不想多介绍此论文的原因是:我觉得和我想做的并不是很相关,因为这都是小碗菜,所以对于分割来说,并没有什么难度。完全可以根据(碗的边缘/目标检测bbox)划分出子图,然后再进行分割就行。
然后在模型框架上也并没有什么创新的改进(不然也不会只发到大学学报上了),个人感觉重点在物理建模,去评估实际的菜品浪费上。倒是一个很好的应用点。但是和我想干的实在是不相干。
2. FoodSAM(23)
Lan, Xing, et al. “Foodsam: Any food segmentation.” IEEE Transactions on Multimedia (2023).
据作者自己说,他们的研究是首个在食品图像上实现实例分割、全局分割以及可提示分割的研究。
Q: 为什么要做多粒度的食品图像分割?
A:在食品相关研究与应用中,多粒度的食品图像分割意义重大,FoodSAM从多个角度阐述了其必要性:
- 提升饮食评估准确性:食品成分多样,传统语义分割仅提供类别预测,难以区分单个食品。实例分割可精确识别和计数不同食品对象,在营养和卡路里估算方面更精准。如在分析一顿饭的营养成分时,能明确每种食材的具体含量,使饮食评估更科学,帮助人们合理规划饮食。
- 全面理解食品属性:食品图像中的非食品对象,如餐具、容器等,反映了食品的属性。全景分割可对这些元素进行分类和区分,获取更全面的场景信息。通过识别食品的容器和餐具,能了解食品的食用方式、场合等,为食品研究和应用提供丰富的上下文线索。
- 适应多样化应用需求:在实际场景中,不同应用对食品图像信息的需求粒度不同。可提示分割支持多种提示变体,满足多样化需求。在智能餐饮系统中,用户可通过点击或框选等提示方式,快速获取特定食品的详细信息,实现个性化的食品识别和分析。
- 应对食品图像的复杂性:食品图像具有外观多样、成分类别分布不均衡、存在遮挡和相似外观等特点。多粒度分割可从不同层次处理这些复杂情况,提高分割精度和适应性。在处理多种食材混合的图像时,实例分割可区分重叠或相似的食材,全景分割可整合背景信息,增强对整个场景的理解。
panoptic,promptable,instance,senmanticsegmentation:全景分割/可提示分割/示例分割/语义分割。

进行实例分割的理由:食物中的食材被随意切割和摆放时、食材成为(相对)独立的个体,每个食材个体都可以被视为一个需要单独识别和分割的实例。
胡萝卜被切成了不同的块状、片状。虽然都是胡萝卜这种食材,但是在菜品图像中呈现出各自独立的形态和位置,所以进行实例分割。
FoodSAM框架:
- 增强语义分割
- 获取基础掩码:输入食品图像$I$,通过语义分割模块$M_{s}$得到语义掩码$m_{s}$,同时通过SAM模型$M_{a}$得到二进制候选掩码$m_{a}$。
- 掩码 - 类别匹配:以$m_{a}$中的每个二进制掩码$m_{a}^{i}$为索引,从$m_{s}$中获取对应的局部语义值集合$D_{i}$ ,采用投票机制在$D_{i}$中选择出现频率最高的语义值$s_{i}$作为$m_{a}^{i}$的语义标签。同时,计算掩码的混淆度$d_{i}$,用于评估语义标签的稳定性,过滤掉混淆度低于阈值$T$的掩码。
- 合并策略:依据掩码的面积大小$Len (D_{i})$对掩码进行排序,从大到小依次合并到原始语义掩码上,得到增强语义掩码$m_{s}^{e}$。这样能充分利用SAM高质量掩码和语义分割器的语义标签,解决掩码重叠区域的冲突问题,保留精细目标的分割结果。
- 语义到实例分割:在增强语义分割过程中,每个二进制掩码都被赋予了语义标签。考虑到食品成分在烹饪时是随机切割和摆放的,可看作独立个体。将小掩码合并到附近具有相同类别标签的掩码中,并过滤掉位置孤立的小掩码。对过滤后的前景掩码,将带有投票语义标签的$t$ 个二进制掩码$m_{a}^{t}$作为第$t$个实例的掩码$m_{i}^{t}$ ,最后合并这些实例掩码得到完整的实例掩码$m_{i}$ ,并为每个实例分配唯一的实例ID。
- 实例到全景分割:食品图像中的非食品对象对理解食品属性很重要。引入目标检测器$M_{d}$ ,其对输入图像$I$进行处理,输出非食品对象的边界框$B_{d}$和对应的类别标签$C_{d}$ 。对于SAM生成的掩码,以每个点为基础,判断其是否位于目标检测器输出的边界框$B_{d}$内,以此选择非食品对象候选。收集语义标签为背景的二进制掩码,计算其与非食品候选边界框的IoU值。当最高IoU大于设定阈值时,将对应的类别作为该掩码的类别;否则,保留其背景标签。最后,按照语义到实例分割的方法合并非食品掩码,与实例掩码$m_{i}$合并得到全景掩码$m_{p}$ 。
- 可提示分割:受SAM可提示分割任务的启发,FoodSAM也引入了这一功能。利用原始语义分割,先通过SAM对感兴趣的食品对象进行分割,实现语义和实例级别的交互式提示分割。在目标检测器$M_{d}$中,将SAM的提示学习方式转换为提示 - 先验选择,支持点提示、框提示和掩码提示等多种提示变体。对于背景中的非食品对象,通过不同的提示方式选择感兴趣的对象,并为其分配目标检测器的类别标签,从而实现对食品和非食品对象的多粒度可提示分割。
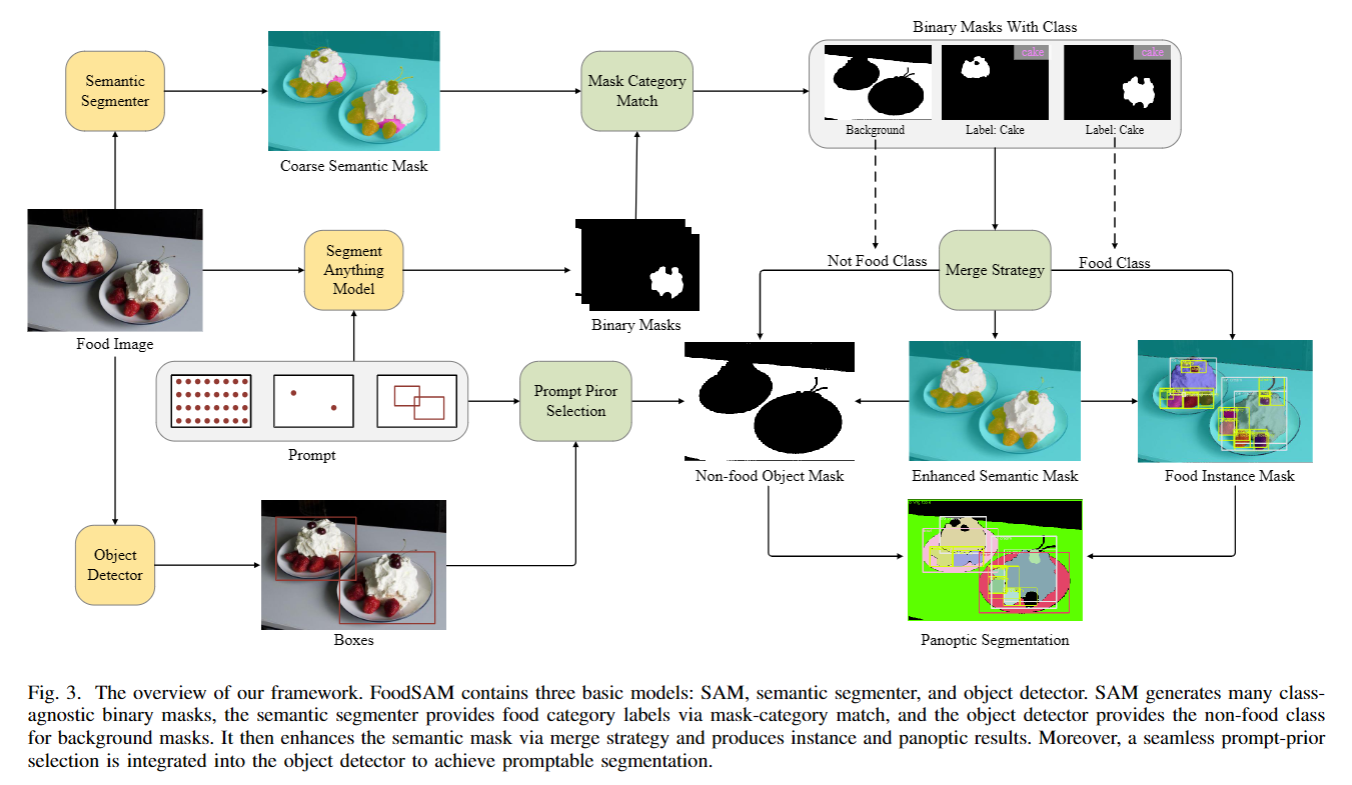
- SAM:生成愈多与类别无关的二进制编码。
- 语义分割器:通过Mask-Category匹配提供食品类别label
- 目标检测器:为背景Mask提供非食品类别
- Merge Strategy:增强语义Mask,生成实例分割和全景分割的结果。
- Prompt-Prior Selection:集成到目标检测器中,以实现可提示分割。
3. SAM in Food Img(24 )
Alahmari, Saeed S., Michael Gardner, and Tawfiq Salem. “Segment Anything in Food Images.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
4. Food Image Segmentation(25)
Xiao, Zhiyong, Yang Li, and Zhaohong Deng. “Food image segmentation based on deep and shallow dual-branch network.” Multimedia Systems 31.1 (2025): 1-14. FoodSeg103-mIoU47.34%,UEC-FoodPixComplete mIoU75.89%
本文介绍了一种新颖的双分支食品分割网络(FDSNet),该网络旨在应对高分辨率食品图像的分割难题。随着经济和技术的发展,人们的饮食习惯变得日益多样化,这也导致了健康问题的增多。非专业人士往往难以有效地管理自己的饮食和健康状况。本文所提出的网络旨在通过精确地分割和识别不同的食品成分,来助力实现更好的饮食管理。
文献:
[13] Xiao, Z., Su, Y., Deng, Z., Zhang, W.: Efficient combination of cnn and transformer for dual-teacher uncertainty-guided semi-supervised medical image segmentation. Com puter Methods and Programs in Biomedicine 226, 107099 (2022)
[14] Xiao, Z., Zhang, Y., Deng, Z., Liu, F.: Light3dhs: A lightweight 3d hippocampus segmentation method using multiscale convolution attention and vision transformer. NeuroImage 292, 120608 (2024)
[15] Gao, X., Xiao, Z., Deng, Z.: High accuracy food image classification via vision trans former with data augmentation and feature augmentation. Journal of Food Engineering 365, 111833 (2024)
[16] Wu, X., Fu, X., Liu, Y., Lim, E.-P., Hoi, S.C., Sun, Q.: A large-scale benchmark for food image segmentation. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 506–515 (2021) :基于ViT-B的分割方法FoodSeg103-mIoU45.2%
[17] Lan, X., Lyu, J., Jiang, H., Dong, K., Niu, Z., Zhang, Y., Xue, J.: Foodsam: Any food segmentation. IEEE Transactions on Multimedia (2023): FoodSeg103-mIoU46.4%,UEC-FoodPixComplete mIoU66.14%
数据集:
- FoodSeg103 [16] 数据集由源自Recipe1M食谱数据集的图像组成。通过精心挑选高质量的食品图像并提供掩码标注,创建了一个新的高质量食品分割图像数据集。该数据集总共包含104个细粒度的食品类别,包括背景,所有掩码标注都精细地标示出菜肴中的每种食材。FoodSeg103数据集共有7118张图像,其中训练集有4983张图像,测试集有2135张图像。
- UEC-FoodPixComplete:该数据集包含 10,000 张图像和 102 种菜品类别,标注为菜品级别。在 UEC - FoodPix 数据集的基础上构建的。UEC - FoodPix 包含 10,000 张带有分割掩码的食品图像,但其中一些掩码图像不完整,因为大多数分割掩码是基于边界框自动生成的。为了实现准确的食品分割,训练需要完整的分割掩码,因此研究人员通过手工细化了 UEC - FoodPix 中自动生成的 9,000 个分割掩码,创建了 UECFoodPixComplete。
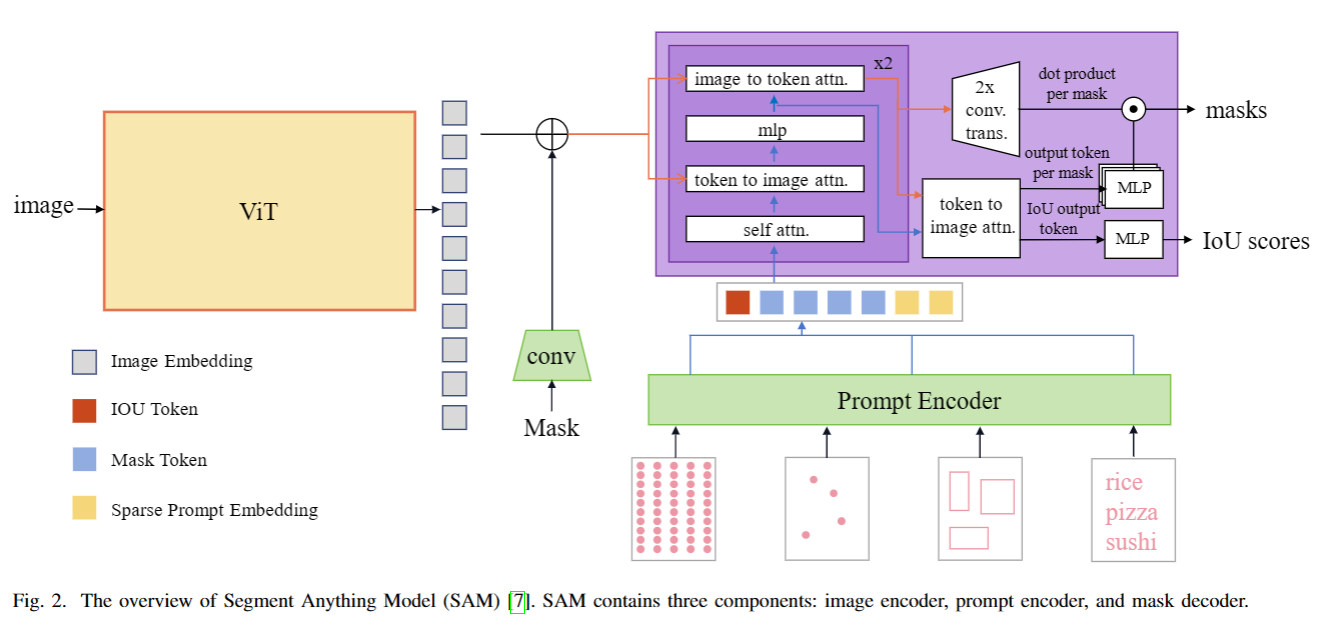
SAM框架:
SAM的三个关键组件:
- 图像编码器:采用计算量较大的视觉Transformer架构,有三种特定尺度的预训练配置(ViT - B、ViT - L、ViT - H ),用于提取输入图像的显著视觉特征。
- 提示编码器:支持点、框、自由格式文本和现有掩码这四种文本或空间输入,不同类型输入有不同的编码方式,其提示嵌入会与图像特征按元素相加。
- 掩码解码器模块:基于Transformer架构,运用自注意力和交叉注意力机制,通过动态掩码预测头输出像素级掩码概率和IoU指标,还能通过转置卷积上采样特征,默认每个提示输入可预测3个掩码以处理提示的模糊性 。

图 1 显示了两者之间的差异。食物图像的特点是不同食物的出现祖先相似、食物位置随机、形状不规则,使得食物图像分割的任务非常具有挑战性。
现有的语义分割网络大多基于编码器-解码器结构,其中编码器提取和压缩图像特征,解码器通过上采样、拼接和加法恢复大小,实现像素级分类。
对于菜品级(dish-level)食物图像分割,网络模型只需要区分背景和食物。然而,对于更详细的成分级(ingredient-level)图像分割,网络模型需要获得更多的精确差分信息。在以前的研究中,已经提出了许多有效的食品图像分割方法,实现了极具竞争力的分割精度。例如,融合 CNN 和 Transformer 的双教师模型 [13],利用多尺度卷积注意力机制和 Vision Transformer 的轻量级 3D 网络 [14],以及数据增强和特征增强技术的应用 [15]。现有的基于 Transformer 模型的食物图像分割方法已经证明了其卓越的特征提取能力。

论文提出的FDSNet模型用于食品图像分割,主要包含拉普拉斯金字塔、双分支骨干网络、多尺度关系感知特征融合模块和渐进式上采样模块四个部分,通过这些组件协同工作,有效提升了食品图像分割的精度和效率。
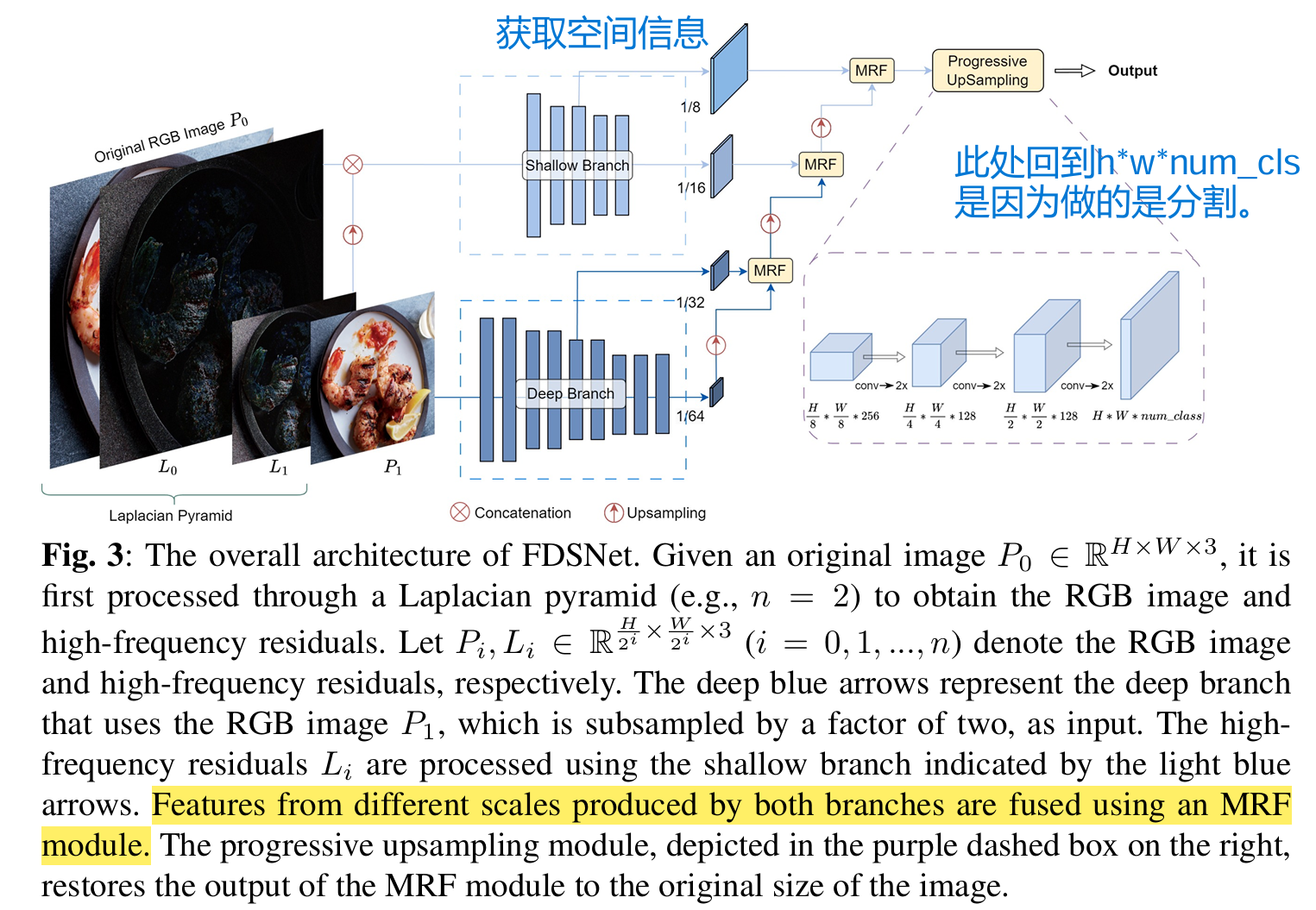
- 整体架构:FDSNet模型由拉普拉斯金字塔、双分支骨干网络、多尺度关系感知特征融合(MRF)模块和渐进式上采样模块构成。原始图像先经拉普拉斯金字塔处理,得到RGB图像和高频残差。双分支网络中,深层网络以降采样后的RGB图像为输入,浅层网络以全尺寸高频残差为输入,二者分别提取高层语义信息和增强空间细节。MRF模块融合两个网络不同尺度的特征图,最后通过渐进式上采样将融合后的特征图恢复到原始空间分辨率,完成像素级分割。
- 双分支网络架构
- 浅层网络:结构相对简单,为减少计算成本且更好地提取空间信息,使用拉普拉斯金字塔计算得到的高频残差图像作为输入,其输出包含分辨率分别为原始图像$\frac{1}{8}$和$\frac{1}{16}$的两个特征图。
- 深层网络:结构复杂,处理高分辨率图像计算成本高,因此采用降采样后的RGB图像作为输入。其输出包含分辨率分别为原始图像$\frac{1}{32}$和$\frac{1}{64}$的两个特征图。这四个不同分辨率的特征图,由MRF模块从低到高分辨率逐步融合 ,最后经渐进式上采样恢复到原始分辨率,实现像素级分割。
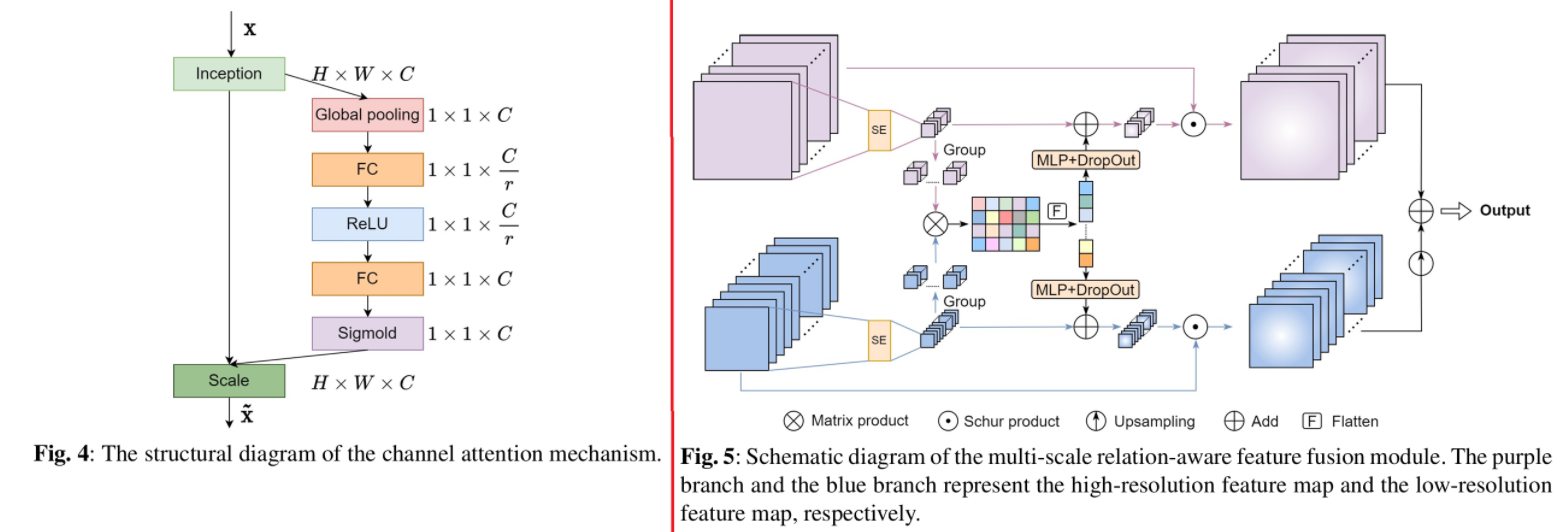
- 多尺度关系感知特征融合(MRF)模块:基于挤压激励网络(通道注意力机制)改进而来。
- 先对两个不同分辨率的特征图通过通道注意力模块分别获取权重,将权重分组后进行元素相乘并展平,再通过全连接层和DropOut得到新的权重向量,与原始权重向量相加后应用到各自的原始输入特征图上。
- 将低分辨率特征图上采样到与高分辨率特征图相同大小后相加,得到最终融合的特征图。
- 该模块能有效整合不同尺度和层次的特征信息,提升分割精度。由于直接对融合后的$\frac1 8$分辨率特征图进行大幅上采样会引入噪声,因此采用渐进式上采样方法,通过卷积层和上采样层交替操作,每次上采样因子设为2,从$\frac{H}{8}×\frac{W}{8}$大小恢复到全分辨率需进行三次渐进式上采样操作,以此减少噪声干扰和对抗效应。
其他收集
来自FoodSAM:
In this paper, we investigate the zero-shot capability of the SAM for the domain of food image segmentation, a pivotal task within the field of food computing [8]–[10]. However, the vanilla mask generated by SAM alone does not produce satisfactory results, primarily due to its inherent deficiency in capturing class-specific information within the generated masks. Moreover, compared to semantic segmentation on general object images, food image segmentation is more challenging due to the large diversity in food appearances and the imbalanced distribution of ingredient categories [11]. Consequently, accurately distinguishing the category and attributes of food items via SAM becomes a challenging task.
在本文中,我们探究了分割一切模型(SAM)在食品图像分割领域的零样本能力,食品图像分割是食品计算领域内的一项关键任务[8]–[10]。然而,仅靠分割一切模型(SAM)生成的原始掩码无法产生令人满意的结果,这主要是因为它在生成的掩码中存在固有的不足,无法捕捉特定类别的信息。此外,与一般物体图像的语义分割相比,食品图像分割更具挑战性,原因在于食品外观的多样性极为丰富,且食材类别的分布不均衡[11]。因此,通过分割一切模型(SAM)来准确区分食品的类别和属性就成了一项颇具难度的任务。
PS: 还有就是,你想从哪个细粒度下去分割:是菜品级别、还是食材级别?(dish-level/ingredient level)
其中常用的两个数据集FoodSeg103/UECFoodPixComplete都是白人饭(不生火的那种),所以感觉识别到一块块的食材是比较简单的。那么我们想做的是炒菜的菜品分割。
食品分割relate work
Q: 为什么要做食品分割?
A: 对于包含多种食品的图像:分割是评估饮食的必要步骤。助力猜食谱(做法)、营养分析、计算热量。
Q: 有何挑战?
A: ①食品外观多样性极大;②食材分布往往不均衡(长尾分布?)③低对比度(相互重叠、没有固定形状、缺乏明显颜色纹理);④光照影响(阴影+反射);⑤不同的摆放方式等等。
总结:
to the best of our knowledge(据我们所知),
- 没有数据集支持对食品图像的实例分割&全景分割
- 没有研究 研究过食品图像的可提示分割或实例分割
全景分割:了解食品周围的环境(上下文信息),帮助了解食品特性以及消费习惯等等。
作者认为:对于下游的食品计算应用(downstream food computing applications),这些任务模式比单纯的语义分割能够提供更多的有用信息。
Wu et al. [11] proposed ReLeM to reduce the high intraclass variance of ingredients stemming from diverse cooking methods by integrating it into semantic segmentation models [37], [52].
ReLeM整合到语义分割模型—>减少不同烹饪方法导致的食材类的高差异性。
Wang et al. [53] combined a Swin Transformer and PPM module in their STPPN model to achieve state-of-the-art food segmentation performance.
STPPN:Swin Transformer+PPM(金字塔池化模块)
Honbu et al. [54] explored zero-shot and few-shot segmentation techniques in USFoodSeg for unseen food categories.
用了新数据集USFoodSeg、zero/few-shot
Sinha et al. [55] benchmarked Transformer and convolutional backbones for transferring visual knowledge to food segmentation. While these approaches have driven progress, semantic segmentation provides only categorical predictions without differentiating individual food items.
对Transformer/CNN进行食品分割的基准测试,以便将视觉知识迁移。
今天也看了下日语,谁叫晚上有日语课捏(>v<)
質問 専門学校 簡単 復習 誤り
乗り換え 途中 浅い お見舞い
倒れた ビル 地震 嬉しそうに あそん 磨き
わからない 失礼します こうへい(公平)
しんぱい
SAM变体
| 对比项 | SAM | RAM | SEEM | SSA |
|---|---|---|---|---|
| 基础功能 | 图像分割,可分割任何概念的对象,包括训练中未见过的 | 图像标注,高效识别常见类别获取图像标签 | 全像素、全语义的图像分割,可进行开放词汇分割和交互式分割 | 专注于语义分割,集成用户已有语义分割器与SAM |
| 训练数据 | 在大规模图像和掩码数据集上训练 | 在大量图像-文本对数据集上训练 | 未提及(推测与图像分割相关数据) | 未提及(推测结合语义分割相关数据) |
| 交互性 | 未明确提及多种交互方式 | —- | 支持点击、框选、多边形绘制、涂鸦、文本输入以及引用其他图像区域等多种提示类型的交互式分割 | —- |
| 模型性质 | 基础模型 | 基于SAM的创新性图像标注基础模型 | 未提及(推测为基于SAM的分割模型) | 开放框架,集成用户已有语义分割器与SAM |
| 参数调整 | 可能需要训练或微调参数 | —- | —- | 避免对SAM参数重新训练或微调 |
| 侧重任务领域 | 通用图像分割 | 图像标注 | 图像分割(强调开放词汇和交互性) | 语义分割 |
| 优势特点 | 强大的零样本迁移能力,可分割几乎任何对象 | 无需人工标注就能获取大量图像标签 | 对不同用户意图展现强大泛化能力,交互方式多样 | 增强语义分割任务中模型泛化能力,精细描绘掩码边界,无需重训SAM参数 |
这些变体相较于SAM的改进:
- RAM:SAM主要是做图像分割的,而RAM就像是在SAM的基础上,专门去做图像标注的工作。它厉害的地方在于,不用人工去给大量图像做标注,自己就能从图像 - 文本对数据集中学习,然后高效地给图像标上常见类别的标签,这样就省了很多人力,在图像标注这个事情上比SAM更有效率。
- SEEM:SAM能分割图像中的对象,SEEM则把这个能力提升了。它可以对图像里的所有像素,按照所有的语义信息进行分割,分割得更全面、更细致。而且它还特别会跟人互动,不管是你点击一下、画个框、画个多边形,还是用文字描述,甚至引用其他图像的区域,它都能明白你的意思,按照你的想法去分割图像,在理解和满足用户的各种分割需求方面比SAM强很多。
- SSA:SAM是个基础的图像分割模型,要是想用在语义分割任务上,可能得重新训练或者微调参数,比较麻烦。SSA就像是一个聪明的框架,它能把你已经有的语义分割器和SAM结合起来,这样就不用重新训练SAM的参数了,不仅省了时间和精力,还能让模型在语义分割任务上表现得更好,把物体的边界分得更清楚,让分割的效果更精细。
SSA对SAM做了以下改进:
能做语义分割:SAM能把图像里的物体分割出来,但不知道这些物体是什么类别。SSA在SAM的基础上,通过一些办法让模型能说出分割出来的物体是什么类别,比如是猫、狗还是汽车等,这就解决了SAM不会给分割结果标语义类别的问题。
SSA 通过构建包含 Mask Branch 和 Semantic Branch 的两分支框架,以及一个投票模块,能够在生成精细掩模的同时,为每个分割出的掩模预测语义类别。
集成很方便:SSA是个开放框架,能让用户把自己已经有的语义分割器和SAM结合起来,而且不用重新训练SAM的参数,这样可以让模型在语义分割任务上表现得更好,分割出的物体边界也更精确。
标注自动化:SSA有个自动标注工具SSA - engine,能给大规模图像分割数据集SA - 1B加初始语义标注,也能给其他数据集标。它结合了好几种方法来生成标签,还能过滤和验证,这样就省了很多人工标注的工作,降低了成本,训练新模型也能更快。