2025-4-22-数据集收集工作推进
wow! A good question is How to collect data to build a dataset.
现在要完成下面的一些问题:
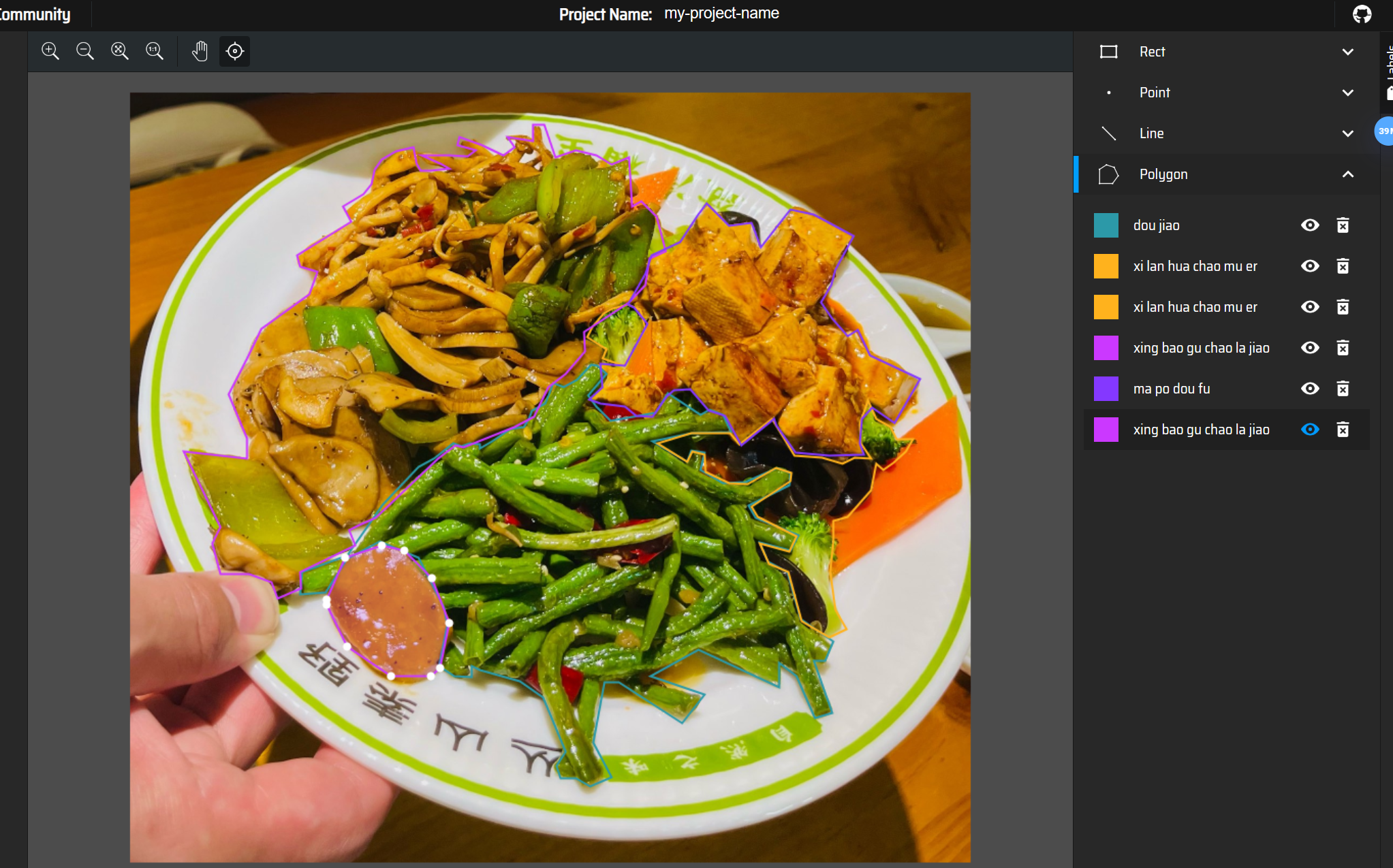
- 分割数据集-标注工具,怎么标注
- 上界做到??最好的分割方法
- 方法构建-当前的最新的方法
- 如何评估
- 分期推进数据 数据集的标注进展
数据收集:每天拍照三餐收集
数据标注:

数据标注工具:MakeSense,LabelMe,
LabelMe 最早是由麻省理工学院 (MIT) 的计算机科学与人工智能实验室 (CSAIL) 于 2008 年发布的,类型覆盖了实例分割、语义分割、bbox标注、图片分类等,是标注领域中不得不提的元老。github链接
工具特性:
- 支持 Windows、macOS 和 Linux 系统本地安装
- 入门版支持多边形、矩形、圆形、直线、点、线带等不同标注类型
- Pro 版本提供 Python API ,可通过编程的方式自动化标注流程、批量处理标注数据、或将标注结果转换为其他格式
价格:基础功能免费,Pro 版(包含AI标注、数据管理等功能)27美元
使用教程:
MakeSense工具特性:
- 无需部署或进行环境配置,浏览器打开即可标注
- 支持矩形、线条、点和多边形等标签类型
- 输出文件格式包括YOLO、VOCXML、VGG、JSON、CSV
- 接入 AI 模型(内置了 YOLOv5、COCO SSD 和 Pose-Net )可进行自动标注
价格:免费
数据收集安排
实际上每个类别有2000张图片差不多。目前针对于目标检测的数据集多以单类别、2k-10k左右.
那就是100个类别,每个类别1000张左右的照片。数据收集中易存在如下的问题:
- 采集的数据集尽量保证你要做的目标检测不同类之间样本平衡,就是各个目标检测的类在你的数据中出现的次数差不多;
- 保证采集数据的质量,过于模糊、遮挡严重或者目标太小、太大的话你肯定不想要吧?其实采集目标的大小还是根据你使用的场景,尽量接近应用场景的尺寸最佳;
- 以及场景下采集数据的多样性,尽量采集场景自然状态下的各种各样的照片,而不是人为地制造变化不大、容易过拟合的图像数据。
- 注意避免正负样本不平衡:图片少但物体多的数据集/图片多但物体少的数据集
分阶段推进数据收集
每人每天采集 30 张(如每餐拍摄 10 张),则每日 300 张,100 万张需 333 天(约 11 个月)。或总人数为 100 人,每日 300 张,333 天完成。
| 分期 | 目标 | 持续时间 | 累计采集量 | 标注跟进安排 |
|————|———————-|—————|——————|———————————————-|
| 第1期 | 采集20k张 | 67天 | 20k | 同步启动标注,完成5k张标注 |
| 第2期 | 采集30k张 | 100天 | 50k | 累计标注20k张,开始验证集标注 |
| 第3期 | 采集30k张 | 100天 | 80k | 累计标注50k张,模型训练1次 |
| 第4期 | 采集20k张 | 67天 | 100k | 完成全部标注,最终测试 |
执行要点
- 并行流程:采集与标注同步进行,避免数据积压。例如第1期采集到5k张时,立即安排标注人员开始工作。
- 质量控制:
- 每日抽检10%图片,检查清晰度、角度、标注准确性(如标签是否正确、框选是否完整)。
- 定期培训标注人员,统一标注标准(如目标边缘是否包含背景)。
- 工具辅助:
- 用Labelme批量标注时,可复用相似图片的标注结果(如同一类食物的不同角度),通过「Edit」→「Copy/Paste」快速复制标注。
- 引入半自动标注工具(如Supervisely、CVAT),利用预训练模型生成初始标注,再人工修正,提升效率。
手动标注数据
标注一张图片的时间在5分钟左右。100k=8333h
1.假设每个人每天标注5小时(60张图片),5个人需要333天。
2.假设每个人每天标注8小时(96张图片),5个人需要208天。
3.假设每个人每天标注10小时(120张图片),5个人需要166天。
但是引入AI辅助标注/半自动工具标注之后,速度应加快不少。假设半自动工具将单张标注时间从5分钟缩短至1.5-2分钟,效率提升2.5-3倍:
| 场景 | 手动标注效率 | AI辅助后效率 | 5人团队日标注量 |
|---|---|---|---|
| 单张时间 | 5分钟/张 | 2分钟/张(提升60%) | 300张/天(5人×8小时) |
| 1.5分钟/张(提升70%) | 400张/天(5人×8小时) |
1.分期标注计划
第1期:数据采集20k张(同步启动标注)
- 采集时间:67天(假设每日采集300张)
- 标注任务:
- 目标:完成20k张标注(含训练集16k张+验证集4k张)。
- 时间安排:
- 第1-10天:采集到3k张后,启动标注(每日标注300张,10天完成3k张)。
- 第11-67天:每日同步采集300张、标注300张,累计完成20k张标注。
- 工具应用:
- 对常见类别(如高频食物)使用预训练模型自动生成初始标注,人工修正(约节省50%时间)。
- 利用Labelme的「复制标注」功能,对相似角度图片复用标注结果。
第2期:数据采集30k张(累计50k张)
- 采集时间:100天(累计采集至50k张)
- 标注任务:
- 目标:累计标注至50k张(新增30k张)。
- 时间安排:
- 每日采集300张,标注300张,100天完成30k张标注。
- 工具升级:
- 引入CVAT或Supervisely等专业工具,支持批量导入AI生成的预标注结果(如YOLO检测框),人工仅需调整边缘。
- 对复杂类别(如多物体重叠)采用「多边形+画笔」组合标注,优先保证训练集精度。
第3期:数据采集30k张(累计80k张)
- 采集时间:100天(累计采集至80k张)
- 标注任务:
- 目标:累计标注至80k张(新增30k张),并完成首次模型训练。
- 时间安排:
- 前50天:每日标注300张,完成15k张,预留50天用于模型训练数据校验(如修正误标样本)。
- 后50天:根据模型训练反馈,优化标注规则(如调整类别阈值),补标或修正2k-5k张易错样本。
- 质量控制:
- 随机抽检10%标注结果,重点检查小目标(如调料)和边缘模糊区域。
- 建立标注错误台账,每周组织标注人员复盘典型问题。
第4期:数据采集20k张(累计100k张)
- 采集时间:67天(累计采集至100k张)
- 标注任务:
- 目标:完成剩余20k张标注,划分测试集并完成全量校验。
- 时间安排:
- 前30天:标注10k张测试集,采用「双人交叉校验」模式(两人分别标注同一张图片,差异超过10%则重新标注)。
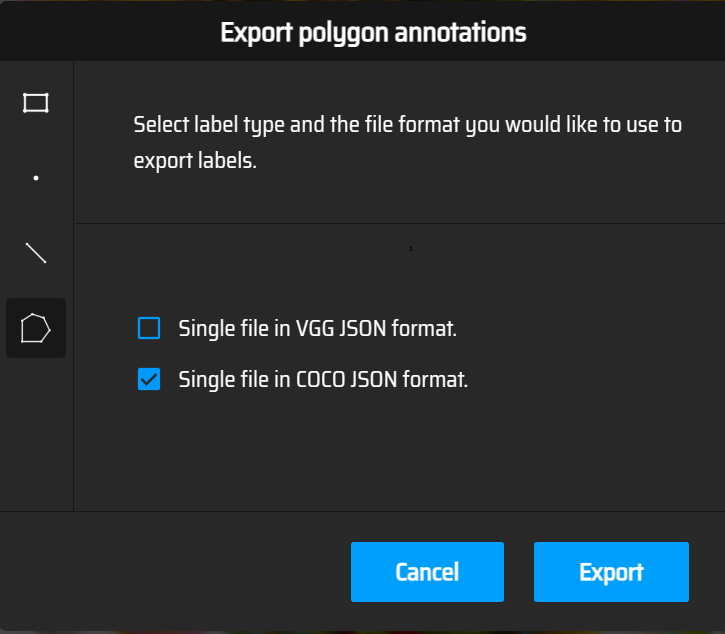
- 后37天:标注剩余10k张训练集,同步完成所有数据集的格式转换(如转为COCO/YOLO格式)。
- 最终验证:
- 使用训练好的模型对测试集进行推理,统计标注漏检率(如未标注的小物体比例),要求漏检率<5%。
关键执行策略
工具链组合:
- 预标注:用YOLOv8或Segment Anything Model(SAM)生成检测框/分割掩码,作为AI初始输出。
- 人工修正:在Labelme中快速调整顶点,或使用「自动填充」功能优化多边形边缘。
- 批量处理:对同一类别的100张相似图片,可先标注1张,其余99张通过「复制-粘贴标注」快速完成,仅修正位置差异。
人员分工:
- 2人负责「复杂类别精标」(如多食材混合菜品),3人负责「简单类别批量修正」(如单一水果)。
- 每周安排1人专门处理标注冲突和历史数据校验。
进度监控:
- 用Google Sheets或飞书多维表格实时更新每日标注量、质检通过率、工具使用效率(如AI预标注占比)。
- 设置预警线:若某周标注完成率<80%,立即启动临时增员或延长每日工作时长(如从8小时增至10小时)。
风险应对
- 工具适配延迟:提前1周在小批量数据(如1k张)上测试AI模型预标注效果,调整模型参数(如置信度阈值)。
- 标注质量波动:每两周开展标注标准考试,不合格者重新培训;对连续3次质检优秀的人员给予奖励。
通过「采集-标注-校验-迭代」的闭环流程,结合AI工具减少重复劳动,可将10万张图片的标注周期压缩至6个月内,同时保证标注精度满足模型训练需求。
数据采集与标注分期计划表(总目标:10万张)
| 分期 | 时间范围 | 采集目标 | 标注时间安排 | 工具与效率优化 | 质量控制措施 |
|---|---|---|---|---|---|
| 1 | 第1-67天 | 采集20k张 | - 第1-10天:采集3k张后启动标注,每日标注300张,10天完成3k张 - 第11-67天:每日同步采集/标注300张,完成剩余17k张 |
Labelme「复制标注」复用相似图片结果 | 每日抽检5%标注结果,重点检查高频类别边缘精度 |
| 2 | 第68-167天 | 累计采集至50k张(新增30k张) | 每日采集/标注300张,100天完成30k张标注 | 引入CVAT/Supervisely批量导入AI预标注(如YOLO检测框) | 每周组织标注规则培训,统一多物体重叠标注标准 |
| 3 | 第168-267天 | 累计采集至80k张(新增30k张) | - 前50天:每日标注300张,完成15k张 - 后50天:校验数据并修正2k-5k张易错样本 |
用Labelme插件自动检测重叠标注 | 建立错误台账,每周复盘典型问题(如小目标漏标) 抽检10%样本,重点检查调料等小目标 |
| 4 | 第268-334天 | 累计采集至100k张(完成剩余20k张标注) | - 前30天:标注10k张测试集,双人交叉校验(差异>10%重标) - 后37天:标注剩余10k张训练集,转换数据格式 |
批量转换为COCO/YOLO格式,校验文件完整性 | 用训练模型推理测试集,统计漏检率(要求<5%) 全量检查标注文件与图片路径对应关系 |
4.23会议纪要
数据收集与标注
数据收集
- 数据集收集:讨论了如何收集100K的数据,初步计划是每天每餐拍摄五张照片,预计需要十个月完成。
- 数据来源:除了保安外,还可以利用学生和其他人员在餐厅用餐时拍摄照片。
- 数据增强:建议在不同角度和光照条件下拍摄,以提高数据的多样性。
数据标注
- 标注工具:介绍了两种标注工具,Label Me(需要下载)和Make Sense(在线使用),并说明了它们的使用方法和优缺点。
- 标注标准:讨论了标注的具体标准,例如是否需要单独标注每个食材,如何处理复杂的菜品组合。
- 标注人员:可以考虑发动合作院校的学生进行标注,以提高效率。
数据采集与标注的具体安排
拍摄安排
- 每人每天拍摄五张照片,预计每天总共拍摄50张照片。
- 拍摄角度和光照:建议在不同角度和光照条件下拍摄,以提高数据的多样性。
标注安排
- 标注工具:详细介绍了Label Me和Make Sense的使用方法。
- 标注标准:讨论了如何标注复杂的菜品组合,是否需要单独标注每个食材。
语义分割与实例分割
语义分割
- 定义:语义分割是将图像中的每个像素分类到预定义的类别中。
- 应用场景:讨论了在菜品识别中的应用,如何处理同一菜品在不同位置的情况。
实例分割
- 定义:实例分割不仅将图像中的每个像素分类,还能区分不同的实例。
- 应用场景:讨论了在菜品识别中的应用,是否需要对每个实例进行单独标注。
会议后续安排
PPT准备
- 数据采集:详细说明数据采集的步骤和最终要求。
- 标注工具:介绍现有的标注工具及其优缺点。
- 语义分割现状:展示当前语义分割的效果和应用案例。
人员安排
- 考虑增加人手:如果一个人不够,可以考虑增加几个人。
- 实习生协助:安排实习生协助数据收集和标注工作。
会议时间
- 下周再约综合处的处长,具体时间待定。