2025-4-22-字节面试准备
知识点
Transformer
- [ ] 介绍transformer架构
- [ ] 详细说一下Decoder的因果注意力 (也叫掩码自注意力)QKV分别来自哪
- [ ] self-attention: Attention为什么要做scaled 不做会怎么样 为什么用根号$\sqrt{d_k}$
- [ ] Transformer怎么做加速训练(KV缓存) 训练和推理有什么区别(并行化)
- [ ] Attention的复杂度是多少?
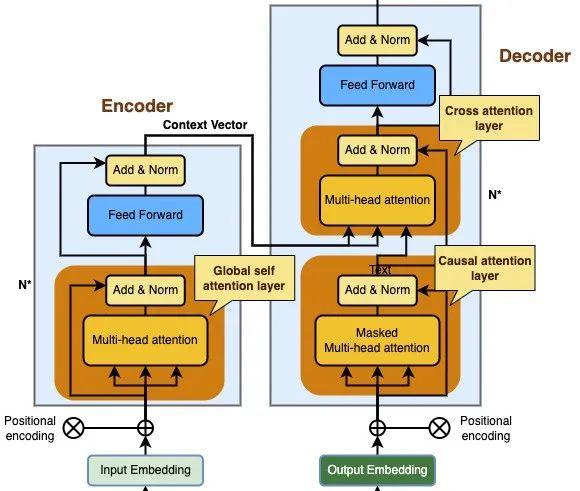
Q K V 交叉注意力层 解码器中因果注意力层的输出向量 编码器输出的注意力向量 编码器输出的注意力向量 因果注意力层 输出序列中的当前位置词向量 输出序列中的所有位置词向量 输出序列中的所有位置词向量 全局自注意力层 输入序列中的当前位置词向量 输入序列中的当前位置词向量 输入序列中的当前位置词向量
LoRA
- [ ] LoRA是什么?有什么好处
- [ ] 知道PEFT吗 讲一下LoRA/微调用的LoRA介绍一下LoRA
- [ ] LoRA初始化怎么做的,用的秩是多少,为什么不选其他的数
其他
[ ] 知道RLHF吗?讲一下训练流程
[ ] bn/ln(batch norm,layer norm,RMS norm)
[ ] bn训练阶段和测试阶段区别,详细讲讲原理
[ ] dropout原理,训练阶段和测试阶段区别,为什么
[ ] 优化器的原理
[ ] PPO的原理,损失函数
[ ] 残差链接的概念
[x] 介绍一下LSTM,为什么LSTM能解决梯度消失或者梯度爆炸,LSTM全称叫长短时记忆神经网络,为什么叫“长短时”
[x] 梯度消失或者梯度爆炸
[ ] 知识蒸馏损失函数
[ ] 交叉熵损失、符号以及含义、梯度下降方向是?代码
[ ] 二分类任务损失函数是?最后一层的激活函数是?
[ ] 回归任务的损失函数可以用哪些?为什么回归使用MSE而不用交叉熵?
[ ] 对比学习?增量学习?
[ ] 神经网络权重可以全部初始化为0吗、为什么?
[ ] 长尾问题的解决方案?为什么长尾侧用MSE、短尾侧用MAE?
[ ] CTR问题用的什么loss?可以用MSE吗、为什么?
搜广推
- [ ] 推荐链路是怎么运作的 有哪些模块
- [ ] 如何做排序模型的迭代
- [ ] MAP(最大后验概率)和似然函数有什么关系?
- [ ] 什么情况下,MAP的损失函数可以用NMSE来计算?(高斯噪声)
- [ ] 推荐算法了解哪些?
- [ ] 冷启动:指在推荐 / 搜索 / 广告系统中,系统在缺乏历史行为数据的情况下,仍然需要做出合理决策的问题。分为:用户冷启动、物品冷启动、系统冷启动。
冷启动与长尾分布的区别:冷启动无数据,长尾数据极少。
数据结构
- [ ] 跳表和二叉树的区别是什么?
- [ ] b+ 树 和 b树的区别, 为什么innodb索引用b+ 不用b
程序设计语言
- [ ] cpp五种内存类型:如堆、栈
- [ ] python中可变/不可变类型
- [ ] 深拷贝/浅拷贝
- [ ] python中的decorator
- [ ] 智能指针?其作用?与auto区别?
- [ ] 野指针?
- [ ] 面向对象三要素:继承、多态、封装
- [ ] 面向对象概念
软工
- [ ] 设计模式:工厂模式等等
手撕算法
- [ ] 单调递增数组nums,判断target是否在里面,要求复杂度为log(n)
- [ ] 最大连续子数列
- [ ] TOP K大的数
- [ ] 全排列(口述全排列 II)
- [ ] 合并 K 个升序链表
- [ ] 有序列表是否有数占了数组的一半以上
- [ ] 二叉树最近祖先

手撕ML/DL
- numpy实现全连接层
- 讲一下multi-head attention 用pytorch手撕一下 要可以实现cross attention的
- 手撕attention
- 手撕交叉熵
- sigmoid梯度下降
numpy实现全连接层
1 | class LinearLayer: |
梯度下降
1 | import numpy as np |