2025-4-20-论文评审
Q: 开放词汇vs开放集vs开放世界??
A: 开放词汇的解释。
Open-Set Object Detection:模型不仅需要识别图像中的已知目标对象(即已知类别),还需要能够识别出图像中不属于已知类别的未知目标对象,并拒绝将它们错误地检测为已知目标对象(reject unknown)。
Open-World Object Detection:识别未知对象并标记为“unknown”(Open-Set);增量学习未知类别(Incrementally learn identified unknown categories),同时,不会忘记之前已经学会的类别。
Open-Vocabulary Object Detection:要求模型超越训练阶段有限的基类(base classes)标签,从而在推理阶段检测由无界(开放)词汇表定义的新类别。
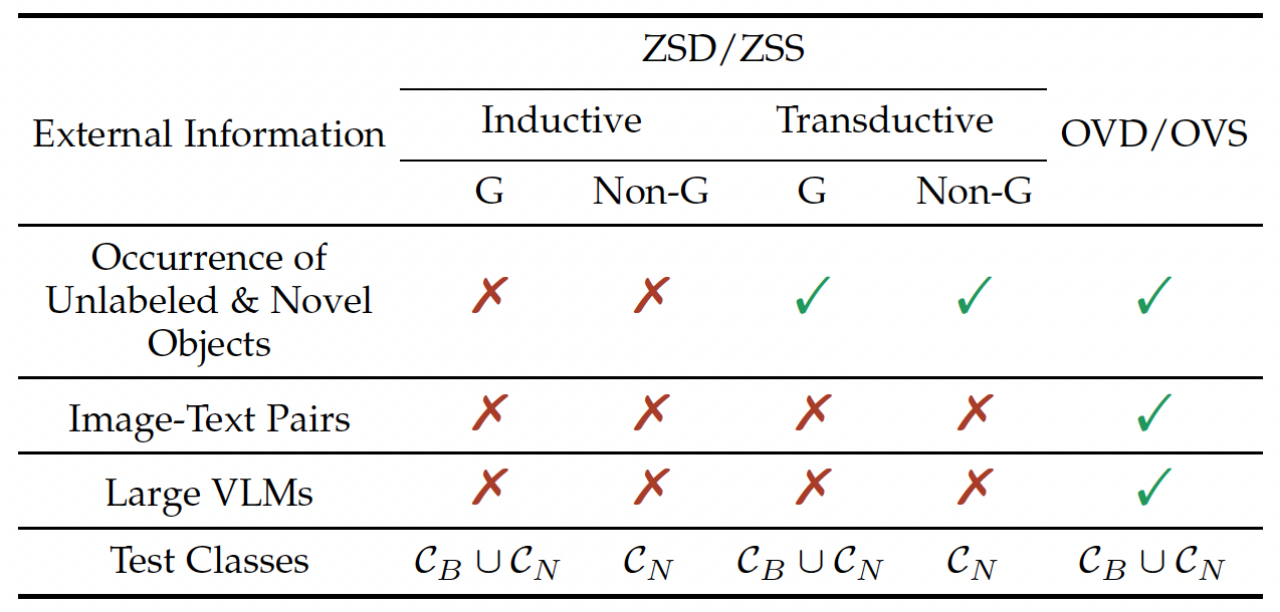
Q: 开放词汇vs零样本?
A:
- 零样本 目标检测/图像分割(ZSD/ZSS, Zero-Shot Detection/Segmentation)
- 开放词汇 目标检测/图像分割(OVD/OVS, Open-Vocabulary Detection/Segmentation)
- 归纳学习(Inductive Learning):训练时不允许出现novel类的数据。
- 演绎学习(Transductive Learning):训练时可以出现novel类数据。
- G/Non-G: G=Generalized,即是否在base+novel上同时测试。
cls: $c_B$=base cls,$c_N$=novel cls
Open-Vocabulary 在 训练时 允许出现 图像-文本对(也就是image-caption、image-level label这些弱监督信号),以及 大的视觉语言模型(如CLIP)。相对zero-shot的设定来说,限制没有那么严格。

本文将现有的开放词汇目标检测方法划分为五大类:知识蒸馏(Knowledge Distillation)、区域文本预训练(Region Text Pre-training)、基于更均衡数据的训 练(Training with More Balanced Data)、提示建模(Prompting Modeling) 和 区 域文本对齐(Region Text Alignment)。
一、研究意义
论文聚焦“面向开放语义的视觉目标检测”这一计算机视觉前沿领域,针对传统目标检测方法在开放场景下对未知类别检测能力不足、跨模态语义对齐困难等核心问题展开研究。
作者针对目标检测下面向开放词汇的目标检测、以及面向视频的指代目标检测进行了研究。这两部分研究以 “开放语义” 为内核,分别从静态图像的词汇扩展与动态视频的时空推理两个维度展开,体现了开放语义检测从 “静态语义-视觉”单项对齐 到 “动态视频-自然语言” 的演进。开放词汇检测的语义建模能力是视频指代检测的底层支撑,而视频检测的动态建模需求反推开放语义理论向时序维度延伸。但是,作者在撰写论文时并未突出两者 “从静态到动态、从图像到视频” 的联系,未在引言开篇中明确阐述两者在 “开放语义” 框架下的互补性与演进逻辑,导致读者难以快速把握研究的整体性。
此外,论文的核心贡献在于方法论创新与性能验证,在实验部分详细展示了研究结果在 LVIS、HC-STVG 等数据集上的性能提升。然而,论文对实际应用意义的论述较为有限,对应用意义的论述更多隐含于研究背景(如 “推动视觉智能系统升级”)和实验结论中,缺乏系统性阐述。
二、相关工作
论文文献综述部分系统梳理了开放词汇目标检测和视频指代目标检测的研究现状,涵盖知识蒸馏、区域文本预训练、时间定位方法等多个技术分支,对ViLD、CLIP、TubeDETR等经典方法及最新进展进行了全面总结。参考的文献覆盖近五年核心期刊和顶级会议论文(如CVPR、NeurIPS),但部分细分方向的文献挖掘可进一步深入,且对2024,2025年最新相关研究的引用稍显不足。
此外,对于现有方法的总结上,部分表述上存在英文直译痕迹明显,读感生硬的问题。如,“根据候选框生成方式的不同,基于候选框的方法可进一步分为三类:基于滑动窗口、基于候选框生成、基于锚点。 ”
部分表述存在中英混杂,表述突兀:“根据是否依赖额外的proposal生成步骤,此领域的方法可分为两阶段方案和 单阶段方案。”
三、论文进展
- 开放词汇目标检测方法
提出基于并行预训练的开放词汇检测框架,通过并行概念建模、多源概念词典构建及负类增强策略,显著提升模型对未见类别的泛化能力。首先论文对提出的模型框架的合理性使用了消融实验进行论证。在消融实验确定最优组件的基础上,与 DetCLIP、GLIP 等方法对比,此时的性能提升可明确归因于整体方法设计(如并行预训练 + 负类增强),而非单个组件的偶然效果。然后论文进行了对比实验,在LVIS数据集上,zero-shot AP达46.0,超越GLIP、DetCLIP等主流方法,尤其在长尾类别检测中表现优异。 - 视频时空定位方法
设计双解码器级联结构和多阶段推理策略,解耦空间与时间定位任务,结合模型集成优化时空轨迹预测精度。同样,在确认最优组件的前提下,与 TubeDETR、STVGFormer 等对比,此时的性能优势(m_vIoU 40.22% vs TubeDETR 36.4%)更具说服力,证明解耦建模和多阶段推理的整体有效性。然后论文进行了对比实验,在HC-STVG 2.0数据集上,m_vIoU达40.22%,较TubeDETR提升10.5%,验证了方法在复杂视频场景中的有效性。
总的来说,并行预训练和多阶段推理虽提升性能,但增加了模型复杂度(如双解码器结构)。论文未明确讨论推理耗时与实际部署的适配性,建议补充计算资源消耗对比(如GPU显存占用、推理帧率)。
老师给的参考版本
论文聚焦“面向开放语义的视觉目标检测”这一计算机视觉前沿领域,针对传统目标检测方法在开放场景下对未知类别检测能力不足、跨模态语义对齐困难等核心问题展开研究。作者针对目标检测下,面向开放词汇的目标检测、以及面向视频的指代目标检测的两个研究方向进行了研究。这两部分研究以 “开放语义” 为内核,分别从静态图像的词汇扩展与动态视频的时空推理两个维度展开,体现了开放语义检测从 “静态语义-视觉”单项对齐 到 “动态视频-自然语言” 的演进。
问题如下:
1)开放词汇检测的语义建模能力是视频指代检测的底层支撑,而视频检测的动态建模需求反推开放语义理论向时序维度延伸。但是,作者在撰写论文时并未突出两者 “从静态到动态、从图像到视频” 的联系,未在引言开篇中明确阐述两者在 “开放语义” 框架下的互补性与演进逻辑,导致读者难以快速把握研究的整体性。
2)论文的核心贡献在于方法论创新与性能验证,在实验部分详细展示了研究结果在 LVIS、HC-STVG 等数据集上的性能提升。然而,论文对实际应用意义的论述较为有限,对应用意义的论述更多隐含于研究背景(如 “推动视觉智能系统升级”)和实验结论中,缺乏系统性阐述。
3)论文文献综述部分系统梳理了开放词汇目标检测和视频指代目标检测的研究现状,涵盖知识蒸馏、区域文本预训练、时间定位方法等多个技术分支,对ViLD、CLIP、TubeDETR等经典方法及最新进展进行了全面总结。参考的文献覆盖近五年核心期刊和顶级会议论文(如CVPR、NeurIPS),但部分细分方向的文献挖掘可进一步深入,且对2024,2025年最新相关研究的引用稍显不足。
4)对于现有方法的总结上,部分表述上存在英文直译痕迹明显,读感生硬迷惑的问题。如,“根据候选框生成方式的不同,基于候选框的方法可进一步分为三类:基于滑动窗口、基于候选框生成、基于锚点。 ”部分表述存在中英混杂,表述突兀的问题。如,“根据是否依赖额外的proposal生成步骤,此领域的方法可分为两阶段方案和单阶段方案。”
5)在实验部分,并行预训练和多阶段推理虽提升性能,但增加了模型复杂度(如双解码器结构)。论文未明确讨论推理耗时与实际部署的适配性,建议补充计算资源消耗对比(如GPU显存占用、推理帧率)。