2025-4-18-实例分割调研
参考资料:
一开始面对其的疑惑:
- 实例分割?和语义分割、以及其他分割任务有何区别?
- 为什么近年来的相关论文很少了?基本上集中在2020-2022年?目前还有在做实例分割的,多是3D开放世界实例分割。难道是因为SAM的出现导致的吗?
实例分割的定义
Q: 实例分割与目标检测的区别?
A:实例分割相较于目标检测会更细致。
- 实例分割预测每个对象的像素级边界(每个实例的精确形状和面积的逐像素“分割掩码”)
- 目标检测预测对象的大致位置(矩形边界框)
Q: 实例分割与语义分割区别?
A: 语义分割相较于实例分割会更简单。
语义分割不涉及不同实例的计数或区分,语义分割的目标是:维图像中的每个像素标注语义类别标签。
如果同一类 thing 的多个对象实例紧密相邻或相互重叠,语义分割模型就会简单地将它们归并到一个图像片段中。

实例分割模型只专注于检测和生成各个实例的分割掩码。实例分割模型必须能够描绘每个不同的对象实例,即使是同一类对象的被遮挡实例。
Q: 实例分割是否可以被理解为语义分割+图像分类?
A: (此处来源于DeepSeek-V3)
实例分割= 目标检测(定位实例) + 语义分割(生成掩码) + 实例区分(解决重叠/遮挡),“语义分割+分类”缺少实例分割的核心能力——区分个体,因此不能等同。两者的差异本质在于是否处理实例级别的分离与标识。
任务目标不同,语义分割不区分实例
语义分割:仅对像素分类(如“人”“车”),但不区分同一类别的不同个体(所有“人”像素属于同一标签)。
实例分割:必须区分同一类别中的不同实例(如“人A”“人B”独立掩码),这是语义分割无法直接实现的。
语义分割的输出无法直接用于实例区分
语义分割的输出是一张类别掩码图,同类物体在掩码中会合并(例如两辆汽车的像素都是“汽车”标签)。
实例分割需要为每个物体生成独立掩码,即使类别相同(如多只猫),也需明确分开。
- 实例分割依赖目标检测逻辑,而非单纯分类 。实例分割通常需要先定位实例(类似目标检测的边界框),再生成掩码。
Q: 全景分割?
A: 对图像中的每一个像素进行语义分类,也需要对每个不同的对象实例进行划分。
最初的全景分割尝试只是实例分割+语义分割,再后处理的步骤中合并它们的输出(难以解决语义模型的数据输出与实例模型的数据输出之间的差异 )。
最近的方法将语义分割“头”和实例分割“头”连接到一个共享的“骨干”,通常是一个特征金字塔网络 (FPN),以进行特征提取:分离出相关的视觉数据。这提高了效率并消除了差异。

总结
实例分割区别于目标检测和语义分割:
- 对比目标检测,实例分割会使用更精细的mask进行定位,而不是bbox;
- 对比语义分割,实例分割需要再语义分割的基础上区分出不同的实例mask。
Q: 得到物体轮廓?
A: 第一,我不知道得到轮廓有什么用处;第二,在进行了语义分割(逐像素点分类)之后,可以调用库函数得到轮廓。
实例分割方法
实例分割的算法发展有如下两条路线:
- 基于目标分割的自上而下的方案:首先通过目标检测定位出每个实例所在的bbox,然后对box内部进行语义分割得到每个实例的mask;
- 基于语义分割的自下而上的方案:首先通过语义分割进行逐像素分类,进而通过聚类或是其他度量、学习手段区分开同类的不同实例。
似乎第一种方式成为了主流:自下而上的方法,后处理的步骤比较繁琐、效果较差。
基于目标检测的自上而下的方法
- two-stage: 首先执行目标检测,然后生成对象分割掩模。两阶段 pipeline(区域建议→实例分割),精度高但速度较慢。e.g. Mask R-CNN
- one-stage: 并行执行目标检测+生成对象分割掩模。单阶段直接预测实例掩码,无需显式区域建议,速度更快。e.g. YOLO系列
- query-base: 引入transformer查询机制,端到端预测。 encoder+decoder. e.g. Swin Transformer
- encoder: 用于从输入图像中提取相关数据
- decoder: 则使用提取的特征数据通过分割图重建图像。
Two-Stage
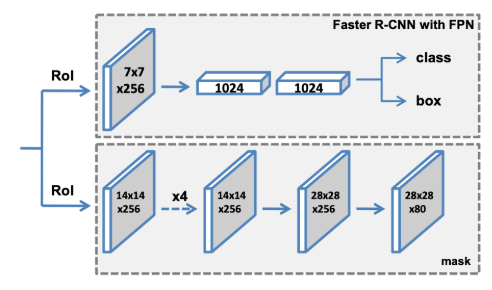
Mask-RCNN
扩展自Faster-RCNN,在其基础上增加了mask预测分支。
Faster RCNN包含两个阶段, 第一个阶段, 是RPN结构, 用于生成RoI集合。第二个阶段利用
RoI pooling从RoI中提出固定尺寸的特征, 然后进行class分类任务和box offset回归任务。Mask RCNN使用了相同的two-stage结构, 第一阶段使用了相同的RPN网络。第二阶段, 利用
RoI Align从RoI中提出固定尺寸的特征, 在执行class分类和box offset 回归任务的同时,MaskRCNN还会给每个RoI生成对应的二值mask;
| RoI Pooling | RoI Align | |
|---|---|---|
| 理由 | RPN阶段得到的proposals box大小不一,为了后续进网络,先将不同尺寸的box的feature map归一化到相同的尺寸,以方便进行batch运算。 | RoI Pooling这种粗糙的量化方式对于Mask R-CNN新增的mask分支会产生很大的量化误差,因此RoI Align方法取消RoI Pooling中涉及的两次量化操作, 使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值。 |
| 具体过程1 | 将box量化为整数坐标值 | 遍历每一个候选区域, 保持浮点数边界不做量化; 将候选区域区域分割成k×k个bins,每个bins的边界也不做量化; |
| 具体过程2 | 将量化后的box区域分割成k×k个bins, 并对每一个bins的边界量化为整数。 | 在每个bins中sample四个point,使用双线性插值的方法计算出这四个位置的值, 然后取最大值; |
bins 就是特征图上的规则子区域,用于将不同尺寸的输入转换为固定尺寸的特征表示,是计算机视觉中实现特征标准化和空间特征聚合的关键操作。
由于mask分支需要对目标进行精细的mask预测,因此,mask分支采用比分类和回归分支更高特征分辨率。
Mask: 经 RPN 筛选的 RoI 通过RoI Align统一为 14×14 尺寸,再经4 层全卷积 + 1 层反卷积,最终输出 28×28 的掩码预测结果,确保分割精度优于分类 / 回归分支。
Cascade Mask R-CNN
动机:探讨如何在检测器Cascade R-CNN基础上设计mask分支。
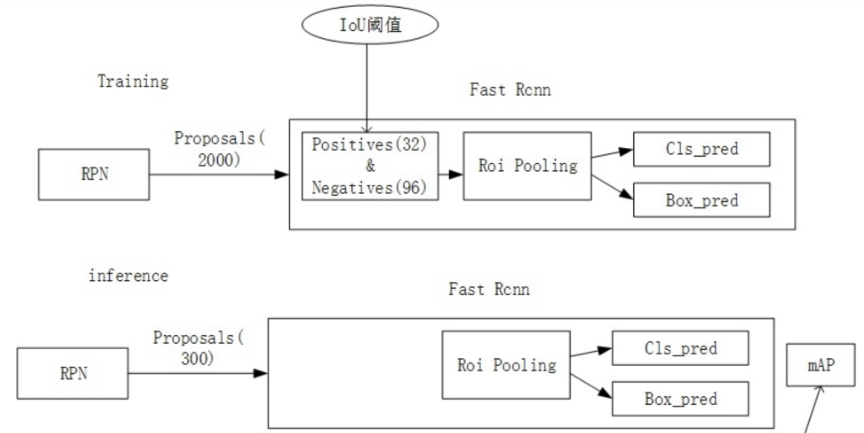
针对Faster-RCNN中RCNN部分采用单一的IoU阈值进行政府样本选取会产生测试过程中的不匹配的问题。
- 训练阶段:RPN网络提出了2000左右的proposals,这些proposals在送入R-CNN结构前,需要首先计算每个Proposals和GT(Ground Truth, 真实目标的bbox)之间的IoU,并通过一个IoU阈值(如0.5)把这些Proposals分为正样本和负样本,并对这些正负样本按一定比例采样,进而送入R-CNN进行class分类和box回归。
- 推理阶段:RPN网络提出了300左右的proposals,这些proposals被送直接入到R-CNN结构中,因为没有GT用于采样。
Q: 测试过程中不匹配?
A: 训练阶段的输入proposals质量更高(被采样过,IoU>threshold);对比推理阶段质量差(未采样,可能包括IoU<threshold) 。当threshold设为0.5时,mismatch问题较轻。若为获取更精准box而提高正样本IoU阈值,会加剧mismatch问题,同时满足条件的proposals大幅减少,易引发过拟合。
级联设计
由于采用单一的IoU阈值会产生不匹配的问题,因此,无法通过一味提升IoU阈值来获取更精准的box预测。Cascade R-CNN提出一种级联结构:并在不同层逐渐增大IoU阈值,来缓解不匹配问题并产生更精确的box预测。对小目标、重叠实例分割效果显著提升,但计算量增加。
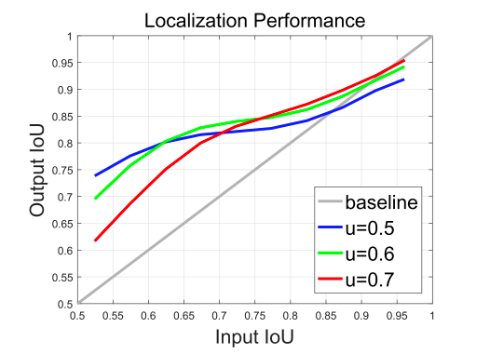
实验说明: 图中横轴为
RPN proposal与gt bbox的Input IoU,纵轴为R-CNN box分支回归后的Output IoU,不同线条代表不同训练阈值的detector。可见:
- Input IoU在0.55-0.6时,阈值0.5的detector性能最佳;
- 0.6-0.75时,阈值0.6的性能最佳;
- 0.75以上时,阈值0.7的性能最佳。
仅当proposal的Input IoU分布与detector训练阈值接近时,detector性能最优。
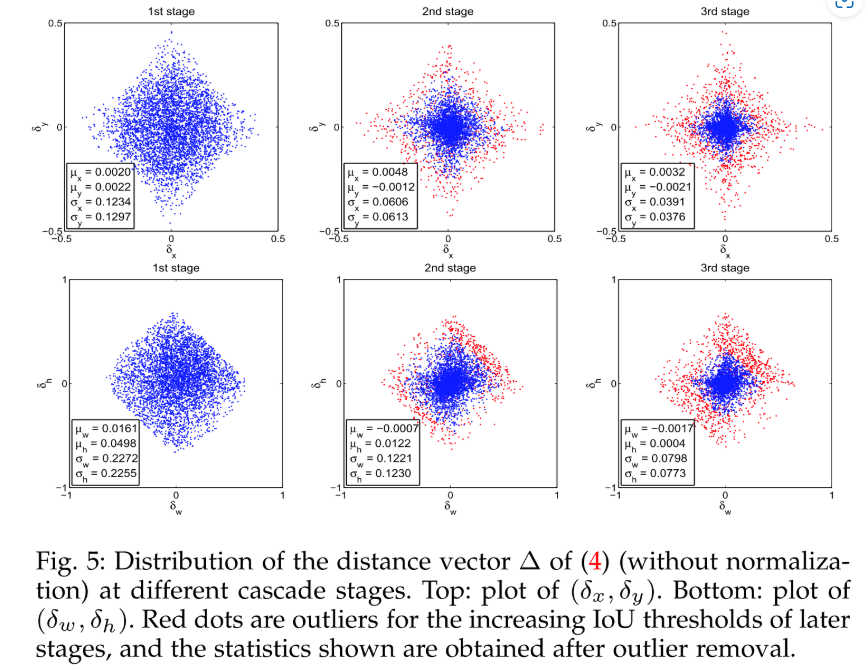
差异化RCNN Head:经过每个stage的R-CNN Head后,输入到R-CNN Head的样本分布会发生变化,因此,采用共享的R-CNN Head无法有效适配变化的样本分布问题。因此,Cascade R-CNN在每个stage都采用独立参数的R-CNN Head。
掩码级联:为将Cascade R-CNN目标检测器推广到实例分割,提出了(b)(c)(d)三种策略来新增Mask分支:

其中C=class,B=bounding box, S=mask.其中又以(d)的性能为最佳
但是多加东西的话,参数也会变多。所以还是要权衡。
总结:
Cascade R-CNN通过级联box head 来进行逐阶段的box refinement;
Cascade Mask R-CNN在其基础上添加级联mask head并在测试阶段对3个阶段的mask预测概率进行均值集成。
- 然而,Cascade Mask R-CNN的3个阶段的mask head之间没有类似box head的逐阶段的refinement的过程,而是各自独立预测,最终进行集成,这也是后续HTC模型改进的关键点。
- 此外,Cascade Mask R-CNN仍然存在类似Mask R-CNN的大目标边缘预测粗糙的问题,这也是二阶段实例分割算法的通病。
stage(阶段):指的是模型中具有特定处理逻辑的串行层级结构,每个阶段以前一阶段的输出(如回归后的候选框、特征信息等)作为输入,通过逐步优化(如调整候选框位置、预测更精细的掩码)提升检测精度。
Hybrid Task Cascade
创新点:融合语义分割监督,增强实例间区分性。
- 设计Mask分支的级联,以便将前一个阶段的mask信息传递到下一个阶段。
- 添加语义分支和语义分割监督来增强特征的上下文语义特征。
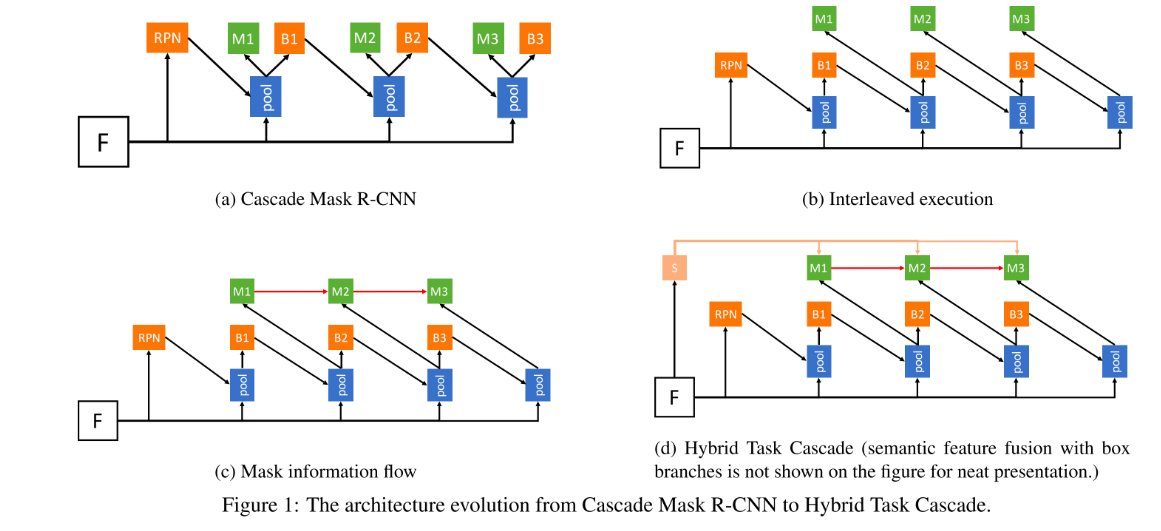
| a. Cascade Mask R-CNN | b. Interleaved execution | c. Mask info flow | d. Hybrid Task Cascade |
|---|---|---|---|
| 当前阶段会接受 RPN 或者 上一个阶段归过的框作为输入,并行预测box和mask.。 | 每个阶段将refine之后的box输入到mask分支。 | 在(b)的基础上,添加了mask分支之间的信息流,每次将前一个阶段的mask特征输入到当前阶段进行”融合“。 | 引入语义分割监督:增强mask分支的特征语义上下文信息。 |
- mask信息流:在不同stage的mask分支间建立联系。
Cascade系列模型通过多个阶段逐步优化检测框(box)和掩码(mask),每个阶段的输入是前一阶段优化后的结果。想让前一个阶段的mask特征(记为 $M_{i-1}$)辅助当前阶段的mask预测,具体做法是:
- 将 $M_{i-1}$ 通过一个 $1\times1$ 卷积(降维或调整通道数)。
- 将处理后的 $M_{i-1}$ 与当前阶段的mask特征($M_i$,来自RoI Align)相加融合($M_{i-1}+M_i$),输入到当前mask分支。
这就要求$M_{i-1},M_i$的尺度要一致。如果两者对应的图像区域不一致,融合后会产生误差(比如把猫的特征和狗的区域叠加)。
解决方法:
- 训练:当处理当前阶段的RoI时,重新运行前一个阶段的mask分支(用当前RoI替代旧RoI),生成新的 $M_{i-1}’$ 特征(基于当前RoI的位置)。 此时 $M_{i-1}’$ 和 $M_i$ 都基于同一RoI,空间位置对齐,可以直接相加融合。
- Stage 1:RPN 生成初始 proposals,输入 Stage 1 处理,输出初步优化的 box 和 mask 特征。
- Stage 2:将 Stage 1 输出的 box 作为输入,进一步优化 box,并融合 Stage 1 的 mask 特征(需重算对齐),输出更精准的结果。
- 推理:直接使用训练好的最后一个 stage模型,输入 RPN 生成的 proposals(或前一 stage 优化后的 box,取决于部署方式),一步输出最终的 box 和 mask。
Q: 为什么推理时不存在空间不对齐的问题?
A: 推理时无需跨 stage 特征融合:推理阶段只运行最后一个 stage,没有前一 stage 的 mask 特征需要融合。
假设模型有 3 个 stage,推理时只使用 Stage 3,其输入是 Stage 2 优化后的 box(或直接使用 RPN 的 proposals,取决于模型设计),但 Stage 3 内部不依赖 Stage 2 的 mask 特征,只需根据当前 box 预测 mask 即可。
因此,不存在 “不同 stage 的特征需要对齐” 的问题,自然无需处理空间不对齐。
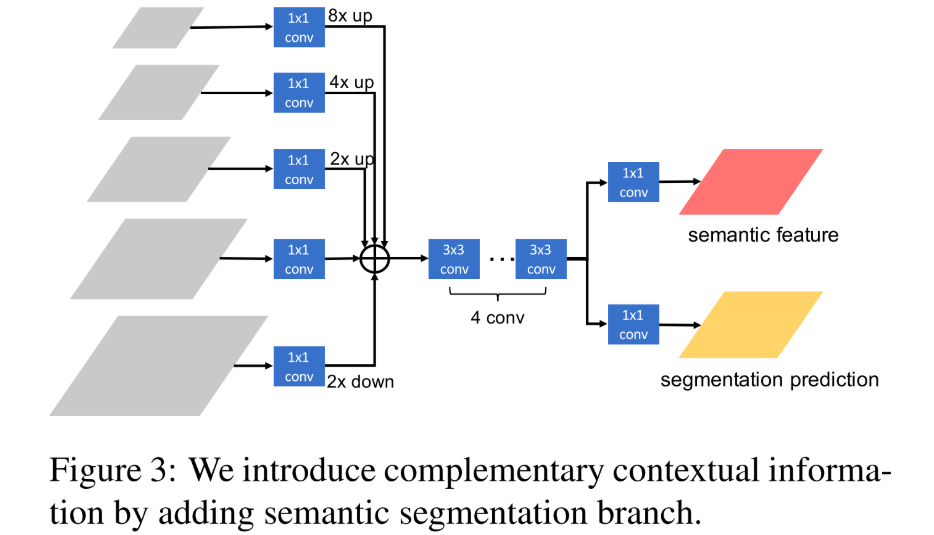
- 语义监督:语义分割能预测每个像素的类别(如 “猫”“草地”“天空”),提供场景的全局语义信息,帮助实例分割更好地区分前景(目标)和背景(非目标)。
具体操作步骤:
输入:FPN(特征金字塔网络)输出的不同层级特征图(如 P2、P3、P4、P5,分辨率从高到低,语义信息从具体到抽象)。
操作:
- 对每个层级的特征图先进行 (1×1) 卷积(降维,通常从 256 通道→256 通道,保持维度不变)。
- 将所有层级的特征图通过插值(如双线性插值)调整到同一分辨率(如原图的 1/4 大小)。
- 将调整后的特征图逐元素相加(sum 融合),通过4层全卷积后,得到融合了多尺度语义信息的特征图,分别预测语义分割特征以及语义分割预测结果。
目的:低层级特征(高分辨率)包含细节,高层级特征(低分辨率)包含语义,融合后兼顾细节与全局语义。
双任务输出
分支 1:预测语义分割特征(用于后续与实例分割特征融合)。
RoI Align 提取实例特征:对于目标检测分支输出的 RoI(候选框),通过 RoI Align 从语义分割特征中提取对应区域的特征(尺寸固定,如 14×14)。
特征融合:将提取的语义特征与实例分割的box 特征和mask 特征进行 逐元素相加(element-wise sum)。
- box 特征:来自目标检测分支的分类 / 回归特征。
- mask 特征:来自掩码预测分支的特征。
目的:将语义信息(如 “该区域属于猫类”)融入实例分割的特征中,增强模型对前景实例的判别能力。
分支 2:预测语义分割结果(像素级类别标签,如 “猫”“狗”“背景”)。
关键:分支 2 需要引入语义分割损失函数(如交叉熵损失),强制模型学习像素级语义分类能力。
总结: HTC作为二阶段实例分割的代表性算法,长期占据COCO榜单前列(直至2022年6月被Mask DINO小幅超越)。其核心通过mask信息流级联与语义监督策略实现性能提升,缺点是:二阶段算法普遍存在的RoI Align局限性。
RoI Align局限性 说明 空间量化误差 早期 RoI Pooling对候选框坐标取整量化,造成与真实目标区域偏移。如 (100.2, 200.5) 被量化为 (100, 200)。这对实例分割影响大,会导致掩码边界错位,小目标或密集目标场景更严重,还会使提取的特征包含错误背景信息。采样点缺乏灵活性 通常在 RoI 内均匀选固定数量采样点(如 4×4 网格,每格 1 个),用双线性插值计算像素值。这种方式无法适应目标结构,不能捕捉不规则形状,小目标易被背景稀释特征。 多尺度特征适应性差 实例分割需处理不同尺度目标, RoI Align采样策略对此不敏感。大目标采样点稀疏,小目标易引入背景噪声,低分辨率特征图上小目标难提取特征。计算效率与内存问题 每个采样点需双线性插值计算邻近像素加权和,RoI 或采样点多,计算量剧增。且采样点坐标为浮点数,内存地址不连续,影响 GPU 推理速度。 对旋转或变形目标鲁棒性差 RoI Align假设目标为轴对齐矩形,实际目标可能旋转或不规则。旋转目标的 RoI 区域易含大量背景,特征无法表征目标姿态。与端到端框架兼容性受限 依赖人工设计的 RoI 机制,属两阶段框架,需先检测生成候选框,难以嵌入端到端模型,推理链条长,部署成本高。
One-Stage
背景:局部mask v.s. 全局mask
| 局部Mask | 全局MAsk | |
|---|---|---|
| 说明 | ||
| 优点 | ||
| 缺点 |
Query-based
Query-based方法均是起源于DETR:通过初始化一组(如100个)可学习的query,并采用Transformer结构对query特征进行迭代更新,进而对每个query进行回归和分类,这样就可以对每张图输出固定数目的检测结果。 再使用二分图匹配GT得到loss梯度下降优化模型。
Facebook Research 本身就基于 DETR 提出了它的实例分割版本 —— [DETR + Mask Head,即:Conditional DETR、Mask2Former、DETR with Segmentation Head 等]。
方法名 描述 是否支持分割 框架 DETR (2020) 原始目标检测版本 ❌ 不支持分割 PyTorch DETR + Mask Head 原始论文中附加了 mask 分支,可用于 instance segmentation ✅ 支持 官方 repo 分支 Conditional DETR 改进收敛速度,适配 segmentation ✅ 支持 detectron2 / torch Mask2Former (2022) 最新统一分割框架(semantic + instance + panoptic) ✅ 强力推荐 detectron2 Deformable DETR 引入可变形注意力,提升速度和精度 ✅ 搭配 segmentation head 可做分割 MMDetection / 官方
QueryInst(2021):Sparse RCNN+RoI Align
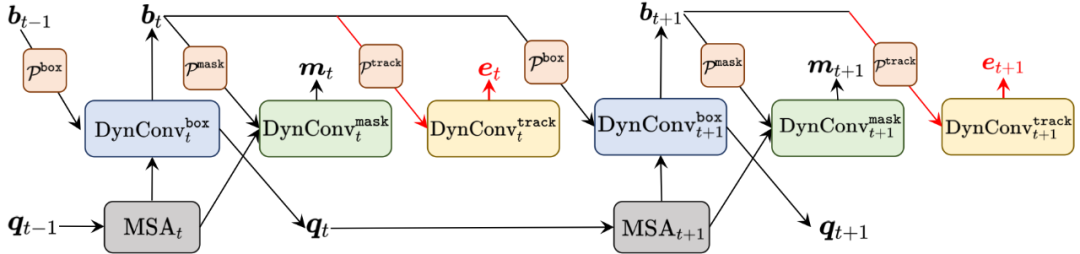
Backbone:ResNet50+FPN输出P2-P5四个分辨率的特征;(表示下采样的次数,分别是特征图分辨率数输入图像的$\frac 1 4,\frac 18,\frac 1{32},\frac 1{64}$)Query Embedding Init:采用nn.Embedding初始化N个object Proposal 的queries bbox和queries features;box head: 更新Query 并进行 bbox和cls预测。mask head:正样本实例mask预测multi-stage:QueryInst采用类似Cascade Mask R-CNN 的多阶段box head和mask head 的结构,每一阶段更新后的query features和重新预测的box会作为下一个阶段的Proposal feature和Proposal box的初始化。
 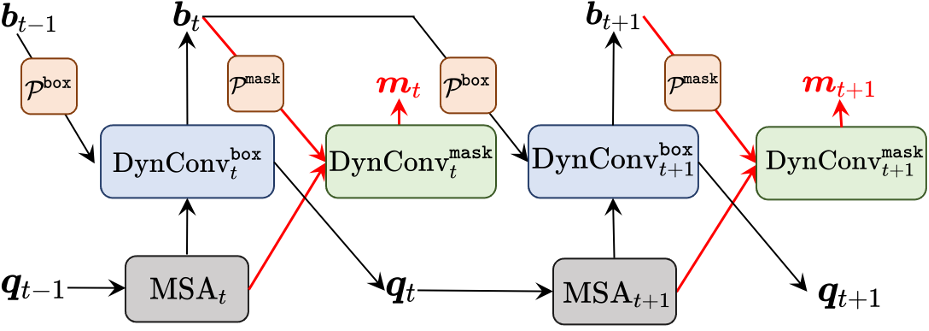  |
 |
|---|---|
关键点是提出了Dynconvtmask模块,将query和mask信息建立了联系,同时利用不同阶段的query中固有的一对一对应关系提升了检查精度,即每个单独的的query在每个阶段均用来预测同样的目标;
动态卷积头:每个查询生成专属卷积核,用于边界框与掩码预测,增强实例特异性。
Mask2former(2022)
统一框架:兼顾语义分割、实例分割与全景分割,基于 Transformer 实现多任务兼容。
- 关键模块:
- 像素解码器:提取多尺度特征,融合全局上下文。
- Transformer 解码器:
- 掩码注意力(Masked Attention):仅关注当前查询对应的实例区域,降低计算量。
- 查询 - 特征交互:通过交叉注意力(Cross-Attention)生成实例专属掩码。
- 采样点损失:在掩码关键点处计算损失,提升训练效率。
- 突破:无需显式检测框,直接通过查询生成实例,推动端到端分割发展。
训练与评估
反向传播训练模型。
重点在于:对训练数据的标注必须非常准确。
训练数据的标注必须非常准确,这样才能最大限度地实现正确的机器学习,并作为“地面实况”基准,据此对训练模型进行评估和优化。由于人类的能力甚至大大超过了最精确的计算机视觉模型,因此标注工作需要手动完成,这是一个昂贵、劳动密集型的过程。
常见开源数据集
- COCO(上下文中的常见对象):一个包含超过 330,000 张图像的海量数据集,其中包含 80 个 thing 类别和 91 个 stuff 类别的带标注片段
- ADE20K:由麻省理工学院创建的场景分割数据集,包含超过 20,000 张图像和超过 150 个语义类别
- Cityscapes:一个专注于城市街道的大型数据集,包含 50 个城市在不同白天、季节和天气条件下的图像。
评估指标
最常用的实例分割和对象检测性能测量方法是交并比(Intersection over Union,IoU)和平均精度(Average Precision,AP)。
交并比 (IoU)
IoU 衡量地面实况掩码与模型预测之间的像素重叠度,以百分比或 0 至 1 之间的整数表示。对于具有多个实例的图像,使用平均 IoU (mIoU)。
虽然 IoU 很直观,但也有很大的局限性:
- 它奖励过于宽泛的预测。 即使分割掩码过大,但如果其中包含了地面实况掩码,它的 IoU 也会达到完美的 1 分。
- 它不能用作损失函数。 对于没有重叠的糟糕预测,无论是稍有偏差还是根本不接近,IoU=0。这意味着 IoU 不可微分,因此无法帮助算法优化模型。 全局交并比修改了 IoU 以使其可微分。
平均精度 (AP)
AP 的计算方法是精确度-召回曲线下的面积。它平衡了精确度和召回率这两个指标之间的权衡,精确度和召回率使用离散结果值计算,如真阳性 (TP)、真阴性 (TN)、假阳性 (FP) 和假阴性 (FN)。
- 精度(precision) 衡量正确的正面预测次数(在这种情况下,分割实例的像素): TP/(TP+FP)。它的缺点是奖励假阴性。
- 召回率(recall) 可衡量捕获正面预测的频率: TP/(TP+FN)。它的缺点是奖励假阳性。
为了最大限度地提高相关性,通常在特定的 IoU 临界值内计算 AP。例如,“AP50”只计算 IoU 大于 50%的预测的 AP。平均精度 (mAP) 是所有计算阈值的平均 AP 值。
ps:话说,感觉和目标检测还是非常像的。
Q: 我想知道,我原先想在一张图片上,找出不同的物体类别。因此一开始我打算使用目标检测来做,但是物体之间的粘连比较严重,因此考虑使用实例分割来进行。那我之前有关于目标检测的相关框架是否可以迁移到实例分割上使用?此外,对于实例分割存在的数据集的数据要如何标注,与目标检测的数据标注有何区别?
A: 大多数情况下可以迁移使用,特别是基于 PyTorch 或 TensorFlow 的现代检测框架。比如:
原目标检测框架 可迁移到实例分割的方式 Faster R-CNN Mask R-CNN 是它的扩展,增加了 mask 分支 YOLOv5/YOLOv8 YOLOv8 本身支持 instance segmentation(在其模型设置中切换任务类型) Detectron2 支持 detection 和 segmentation,非常适合迁移 MMDetection 支持多种 detection 和 segmentation 模型,配置灵活 所以如果你原来用的是如 Faster R-CNN、YOLO、RetinaNet 等目标检测模型,那么:
- 你可以直接使用这些框架里的实例分割模型(如 Mask R-CNN)
- 很多代码都可以复用,例如 backbone、数据加载、训练流程等,只需改动部分配置和模型头。
二、目标检测 vs 实例分割:数据标注格式的区别
项目 目标检测(Object Detection) 实例分割(Instance Segmentation) 标注内容 每个物体用一个矩形框(bounding box)包住 每个物体用一个像素级别的掩码(mask)来标注 存储格式 [x_min, y_min, x_max, y_max]+ 类别多边形(polygon)或像素掩码 + 类别 常见格式 COCO bbox / VOC xml COCO Segmentation / Mask png 工具支持 LabelImg、VoTT、Makesense.ai 等 CVAT、LabelMe、Segments.ai、Roboflow 等 COCO 中的实例分割标注例子(json):
2
3
4
5
6
7
8
9
10
11
12
13
"annotations": [
{
"segmentation": [[x1, y1, x2, y2, ..., xn, yn]], // 多边形
"area": 1500,
"iscrowd": 0,
"image_id": 1,
"bbox": [100, 200, 50, 80], // 同时也包含 bbox
"category_id": 2,
"id": 1
}
]
}注意事项:
- segmentation 可以是 多边形点集,也可以是 rle(run-length encoding)掩码(尤其在 COCO dataset 中)
- 如果物体粘连严重,polygon 标注更适合,比简单 bbox 精细得多
- iscrowd = 1 表示该实例较难分割,如密集人群
三、标注建议
- 如果你用 COCO 格式数据:可以直接用于 Mask R-CNN 等模型。
- 推荐标注工具:
四、总结与建议
- ✅ 你原有的目标检测框架 完全可以迁移,只是需要模型结构上增加 mask 分支(如用 Mask R-CNN)。
- ✅ 实例分割的数据格式更细粒度,通常是 多边形或掩码图像,不再只是 bbox。
- ✅ 物体粘连严重,确实实例分割比检测更合适。
- 🛠️ 可用 COCO 格式标注,直接用 Detectron2、MMDetection、YOLOv8 等现成实现进行训练。
终结大恶魔!SAM
SAM2-面向video进阶版
从目标检测扩展到实例分割
路径 1:在你现有代码基础上添加 Mask Head
你可以仿照原始 DETR 的 segmentation 分支做法:
- 添加一个 mask head:输入是 backbone + transformer 输出的特征
- 通常是一个小型卷积解码器或多层上采样模块
- 输出为
[num_queries, H, W]的二值 mask
- 使用 COCO-style segmentation loss:
- 常用是 BCE loss(Binary Cross Entropy),也可加入 Dice loss
- 数据格式:改成 COCO segmentation 格式
segmentation字段提供 mask,bbox仍然保留
- 训练目标:
- 每个 query 同时输出
bbox、class和mask
- 每个 query 同时输出
如果你使用的是 DETR 官方 repo,可以参考其 mask_head.py 和 matcher.py 代码。
路径 2:使用现成支持分割的 DETR 分支或 Mask2Former
- Mask2Former (推荐):Facebook 推出的统一分割模型,支持 instance segmentation,准确率和速度都更好。
- 项目地址:https://github.com/facebookresearch/Mask2Former
- 你只需准备好 segmentation 的 coco-style json 标注文件(和 images)
- Deformable DETR:在原始 DETR 基础上提升了训练效率,官方 repo 也提供了 segmentation 分支。
数据标注格式(COCO-style segmentation)
确保你使用的是 COCO 的 instance segmentation 格式,样例如下:
1 | { |
注意事项:
segmentation是多边形格式(如用 LabelMe 导出)- 如果是掩码(png),则需转换为 RLE 编码(如使用 pycocotools)
iscrowd=0表示每个实例单独可识别,不是粘连群体