2025-4-11-Yang-arxiv-2025
Yang, Chuanguang, et al. “Multi-Teacher Knowledge Distillation with Reinforcement Learning for Visual Recognition.” arXiv preprint arXiv:2502.18510 (2025).
也是用了RL,但是不是很fit我的想法捏。
此处使用到的是知识蒸馏为主、关于奖励函数设计、以及优化上也是最普通的那一种。
但是可以回扣一下之前的想法:2025-3-10-不打算使用KD这篇。
Multi-Teacher Knowledge Distillation with Reinforcement Learning (MTKD-RL)
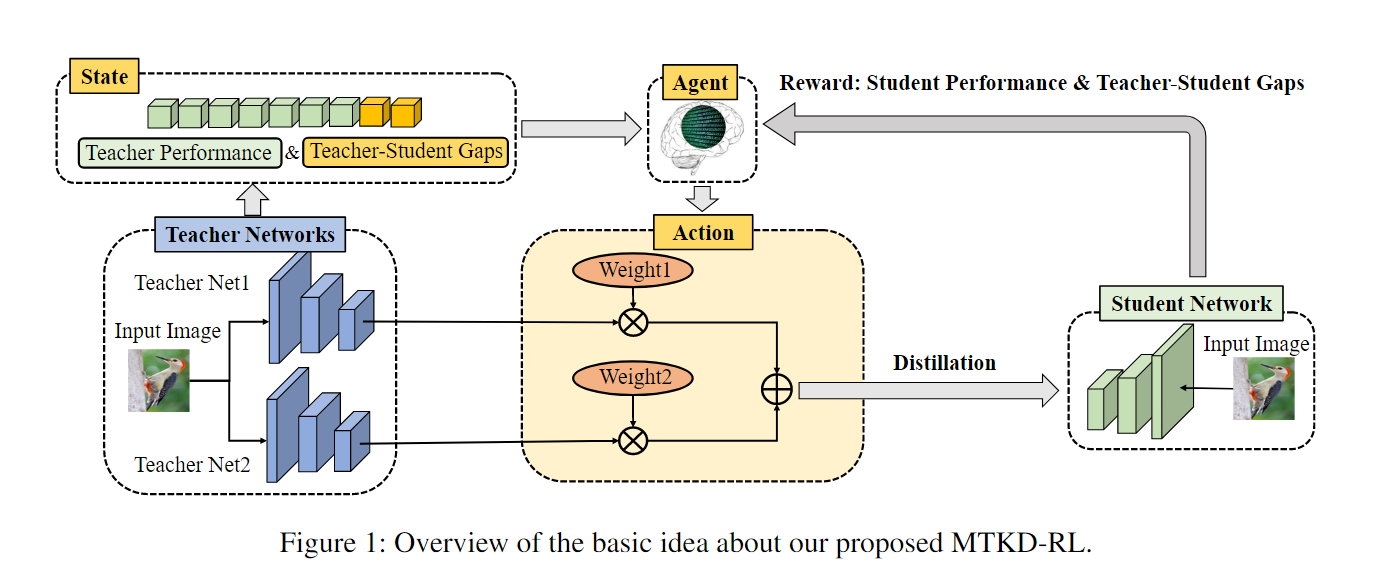
框架Overview
该框架旨在通过强化学习动态优化多教师网络中每个教师的权重,从而提升学生模型的性能。整体流程包括两个主要阶段:
预训练阶段
- 使用固定的平均权重(如 $w_t^m = \frac{1}{M}$)进行一次完整的多教师知识蒸馏(MTKD)训练,得到初步的学生模型 $S$。
- 同时记录每个训练样本对应的 (state, action, reward) 三元组信息。
强化学习优化阶段
- 将记录下的状态(state)作为输入,训练一个 RL agent $\pi_{\theta_m}$ 来输出教师权重 $w_t^m$。
- 使用这些权重重新进行知识蒸馏,训练学生模型。
- 使用更新后的学生模型重新评估 reward,并用这些数据训练 RL agent。
- 两个过程交替进行直到收敛。
诶,这个感觉能对应上首先SFT,然后再RFT。
可以看到的是对于$\{s,a\}$序列只进行了一次收集,所以是off-policy,比较适合使用PRO的方法。
公式推导
总损失
- $\mathcal{H}$:交叉熵损失
- $\mathcal{D}_{KL}$:KL散度(logit知识蒸馏)
- $\mathcal{D}_{\text{fea}}$:特征层距离
- $w_t^m$:教师 $T_m$ 的权重
状态定义(State)
每个样本的状态向量 $s_i^m$ 包含以下五种特征:
- 教师特征表示 $f_{i}^{T_m} \in \mathbb{R}^{d_m}$
- 教师 logit 表示 $z_i^{T_m} \in \mathbb{R}^C$
- 教师 cross-entropy loss: $\mathcal{L}_{CE}^{T_m} = \mathcal{H}(y_i, y_i^{T_m})$
- 学生-教师特征相似度:
- 学生-教师 logit KL 散度:
拼接成整体状态向量:
动作定义(Action)
- 动作 $w_t^m = \pi_{\theta_m}(s_i^m) \in (0, 1)$
- 每个教师都有自己的 agent 网络 $\pi_{\theta_m}$,用于给出该教师的权重
奖励函数(Reward)
奖励函数(Reward Function)是整个 MTKD-RL 框架的核心部分之一,用于评估某一教师在指导学生模型学习过程中的“贡献”大小。该奖励用于训练强化学习 agent,让它学会为每个教师动态分配合适的权重。奖励越高表示教师贡献越大。此处使用负值表示损失,越小越好。
每一轮 RL 迭代中,学生模型训练后会计算新的 reward:
- $ y_i $:第 $ i $ 个样本的 ground-truth 标签
- $ y_i^S $:学生网络的输出(logits 或 softmax 概率)
- $ y_i^{T_m} $:教师 $ T_m $ 的输出
- $ F_i^S $:学生网络的特征表示(通常来自某一中间层)
- $ F_i^{T_m} $:教师 $ T_m $ 的特征表示
| 项 | 含义 | 作用 |
|---|---|---|
| $ \mathcal{H}(y_i^S, y_i) $ | 学生与真实标签之间的交叉熵损失 | 衡量学生模型的基本分类性能 |
| $ \mathcal{D}_{KL}(y_i^S, y_i^{T_m}) $ | 学生与教师 $ T_m $ 输出之间的 KL 散度 | 衡量学生是否学到了教师的分布 |
| $ \mathcal{D}_{\text{fea}}(F_i^S, F_i^{T_m}) $ | 学生与教师在特征空间的距离(如 MSE) | 衡量学生与教师在中间特征上的相似度 |
奖励归一化(Reward Normalization)
为确保 RL 优化稳定,使用 min-max 归一化:
Agent 参数优化
使用策略梯度(Policy Gradient, PG)更新 RL agent 参数:
整体算法流程
- 用平均权重做一轮 MTKD,得到初始学生模型
- 记录训练过程中的状态-动作-奖励数据
- 用这些数据训练 agent 网络
- 用 agent 输出的权重做新一轮 MTKD,得到新的学生模型
- 重复步骤 2–4,直到收敛