2025-3-21-AI-Agent?
AI Agent
比较正规的解释:AI Agent(人工智能体)是一种能够感知环境、进行决策和执行动作的智能实体。它们具备记忆、逻辑分析能力和任务拆解能力,旨在通过自然语言与用户交互,自动化处理复杂工作任务。
这个词倒不是今年才火的。实际上,在Chat GPT未提出之前、就已经有paper提出此思想。BIG-Bench看看下面这个图,是这篇论文中设计了下国际象棋的实验:
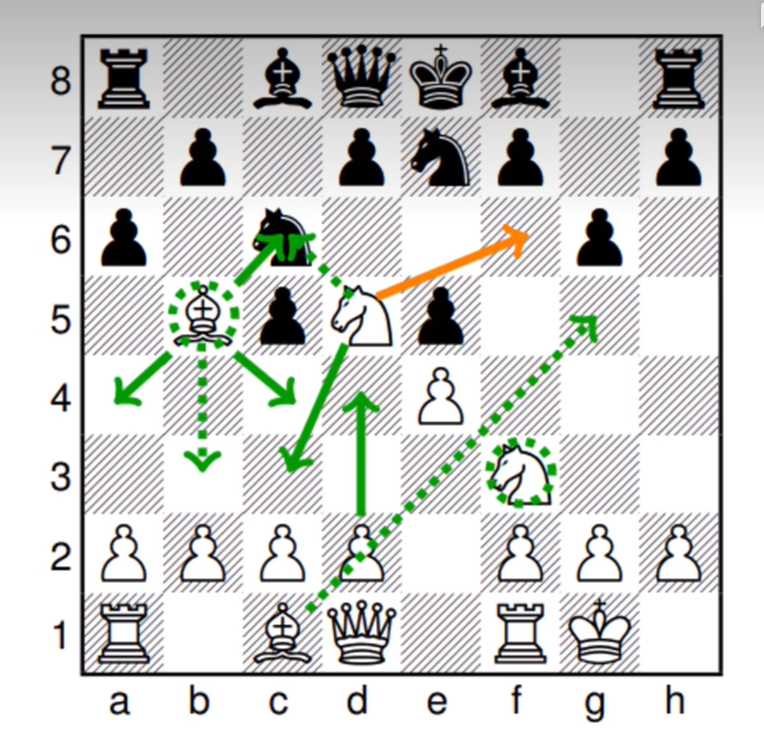
橙色的线是正确的答案,绿实线是当时比较强的模型,而虚线是比较弱的模型。可以看到完全就是乱走了。总的来说,22年还没法做到这个事情。2022年年底ChatGPT出世,2023年春的时候,AI Agent也爆火,但是后面渐渐默默无闻,原因是人们发现这个效果并没有想象中的那么厉害。
例子: AutoGPT,AgentGPT、BabyAGI、Godmode…..
但今年的火,还要从这个视频说起——
B站搬运:ChatGPT大战DeepSeek西洋棋/Youtube:ChatGPT大战DeepSeek西洋棋
没错,让GPT和DS双方下棋,惊天动地的对决!但是结果也是不尽如人意。因为没有遵守规则。
之前,我们提到Agent,都是与RL有关的。RL中绕不开的Agent:通过观测环境、给出行动、行动会影响环境,并给出这个行动的奖励,根据奖励我们调整Agent。目标是总奖励最大。
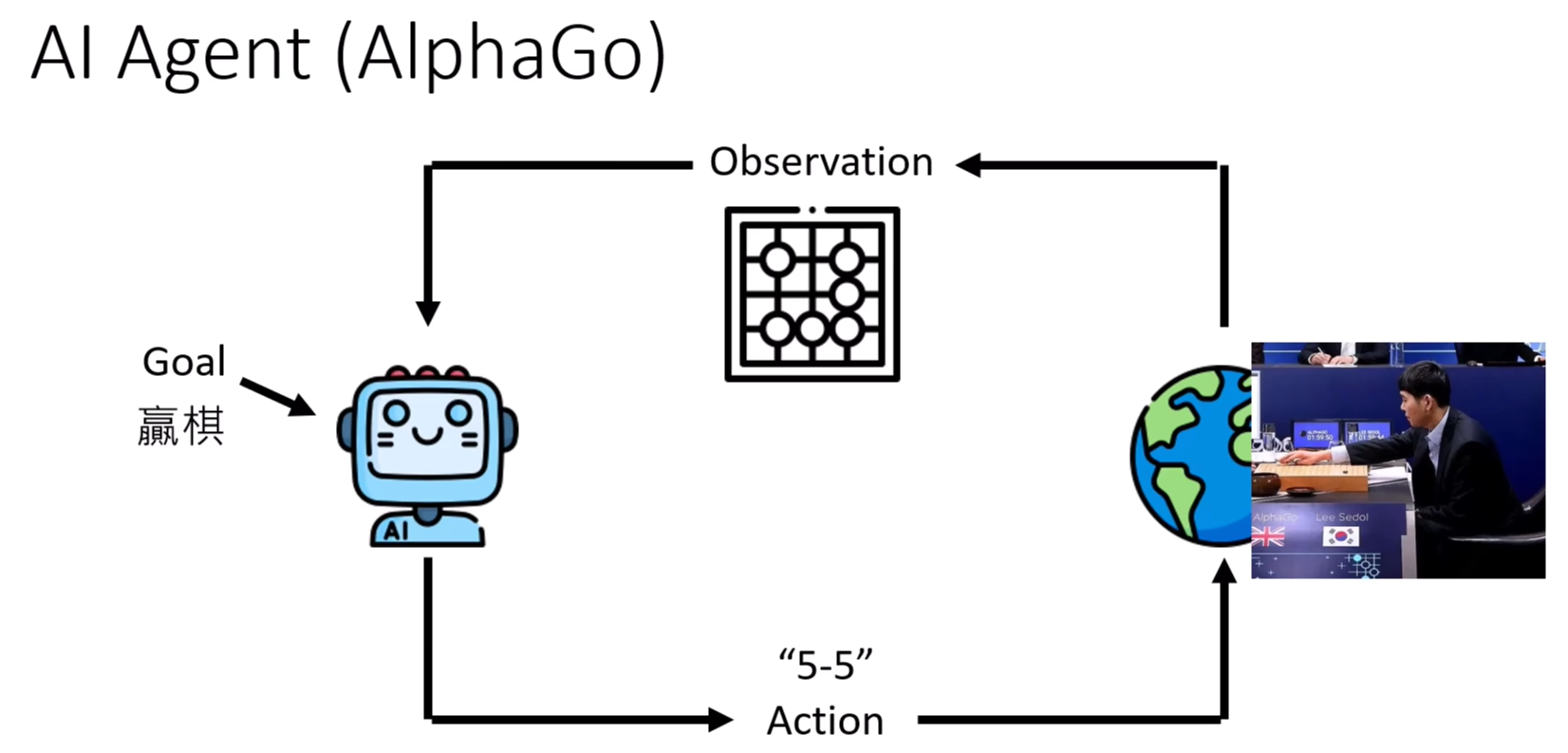
话说,老师开会的时候,冷不丁问我,你知道AI Agent吗?我一下子愣住了,因为平常刷手机肯定会刷到。但是确实不了解这个到底时候,当我在想怎么圆的时候……
果然还是承认自己不会吧。
结果会开完了然后自己去查资料,发现,好嘛,这完全就是一样的。Agent在2022年的时候,我还叫它代理,人家今年改头换面,叫高大上的“智能体”了。
但是这样会存在什么问题呢?
那就是这是面对任务的,针对不同的任务,需要用RL分别训练不同的Agent。
现在提出的AI Agent,并不训练任何模型,而是拿现在已经训练好的LLM(Large Language Model)作为Agent直接使用。Agent的目标、环境、以及行为都是文字叙述。
主要来自人们的想法:既然现在的LLM已经这么强了,那能不能直接作为Agent使用呢?
然后换一个视角来看:从LLM的角度来看Agent要解的问题,Agent要解的问题有什么不同?
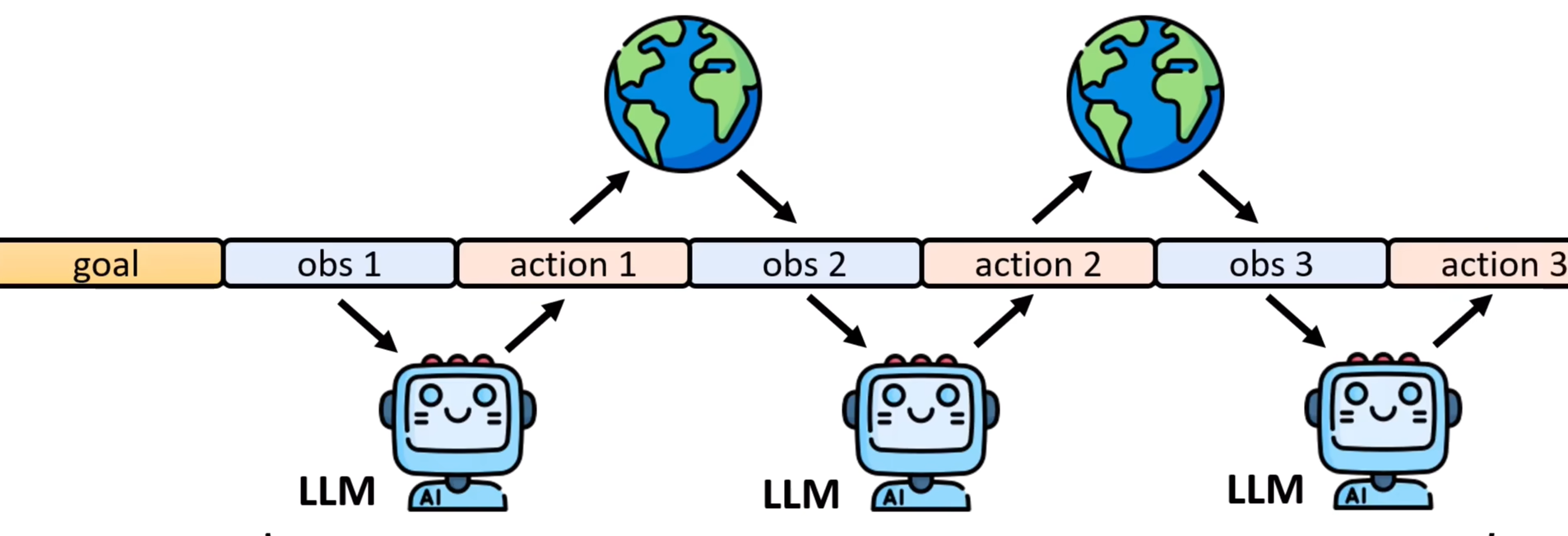
可以看到,LLM还是在做文字接龙,毕竟goal,obs,action都是文字叙述。那么AI Agent,就是依靠现有模型(已经具有一定程度的通用能力),看看能不能直接当成Agent使用。
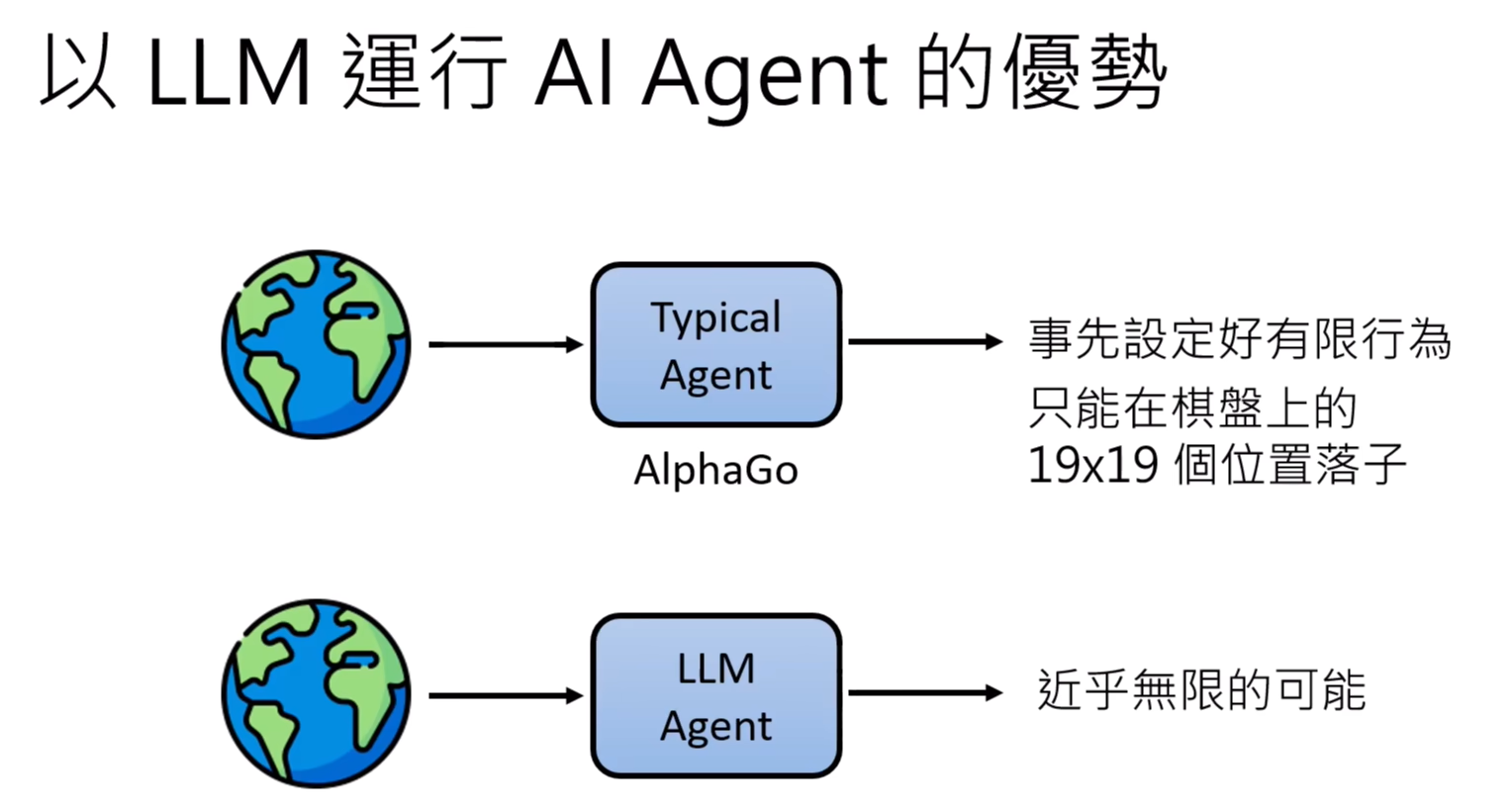
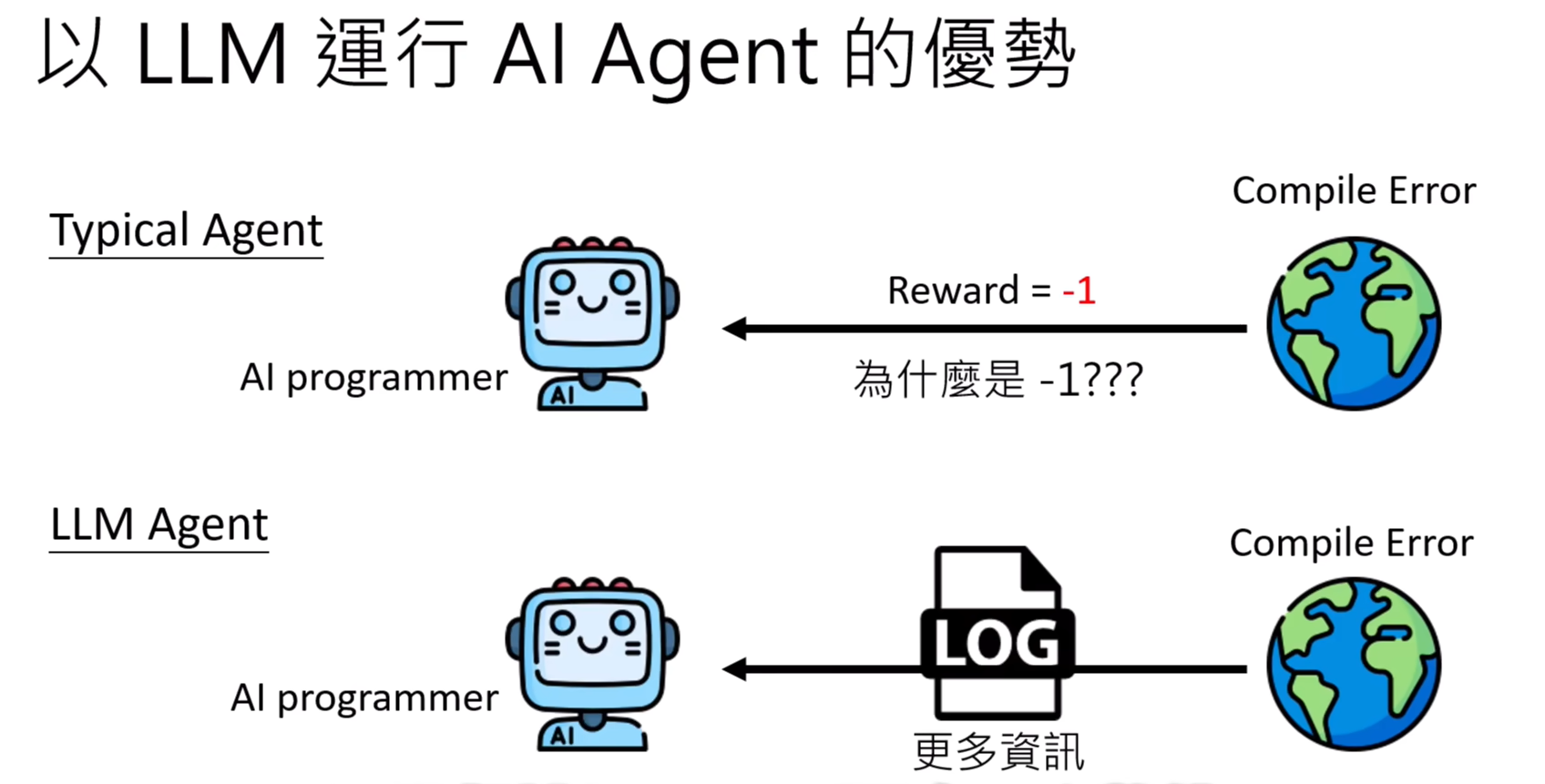
AI Agent能不能根据过去的经验或是与环境的互动中获得的经验来调整自己的行为?
需要注意的是,在这个过程中不会重新调整模型/参数。
因此,直接把错误的信息回馈给LLM,但是后续LLM的输出就不会是错误的了。LLM可以根据回馈改变自己的行为。
Q:过去的所有的错误信息全部回馈给LLM??有1w+条信息怎么办?
A:显然,不能把所有看过的所有的错误信息全部都看一遍。这并不好,所以设定一个memory,根据read模组(retrieval推荐系统),选择memory中间筛选出相关的信息来看。read模组可以套用RAG的方法。
RAG是什么?
RAG(Retrieval-Augmented Generation)是一种结合检索和生成的技术,通常用于增强大语言模型(LLM)的能力。RAG的核心思想是通过检索相关的外部信息(通常是数据库或文档)来补充生成模型的知识,从而提高其回答问题的准确性和相关性。它让模型在回答问题之前,先去找一些外部的资料或者信息,然后再用这些信息来帮助回答问题。
RAG方法的基本步骤如下:
- 检索(Retrieval):系统首先根据输入查询(例如问题或任务)从一个外部知识库中检索出相关的文档或信息片段。这些文档可以是文本、网页或任何结构化的数据。
- 生成(Generation):然后,这些检索到的文档与输入一起作为上下文传递给生成模型,生成模型(如GPT)使用这些信息来生成回答或进一步的推理。
举个例子:
假设你问模型:“今天的天气怎么样?”而模型并没有实时的天气信息。RAG方法会让模型先去找一下外部的天气数据(比如天气网站或者数据库),然后根据这些信息给出准确的答案。
在你提到的错误信息处理上,RAG可以让系统通过“查找”之前发生的类似错误,来帮助它更好地解决当前的错误,而不是一次性处理所有错误信息。这样可以避免让模型太混乱,确保它只看到有用的、相关的信息。
与AI Agent关系?——经验的来源不同。
- RAG:存储在memory中的东西相当于是整个网络,来自于别人的经验。
- AI Agent:存储在memory中的东西相当于是整个网络,来自于自己的经验。
AI Agent能不能呼叫外援、使用工具?
常用工具:搜索引擎、自己写程序并运行、以及更厉害的LLM(比如平常是4o-mini,遇事不决找4o/o1)
如何使用工具:
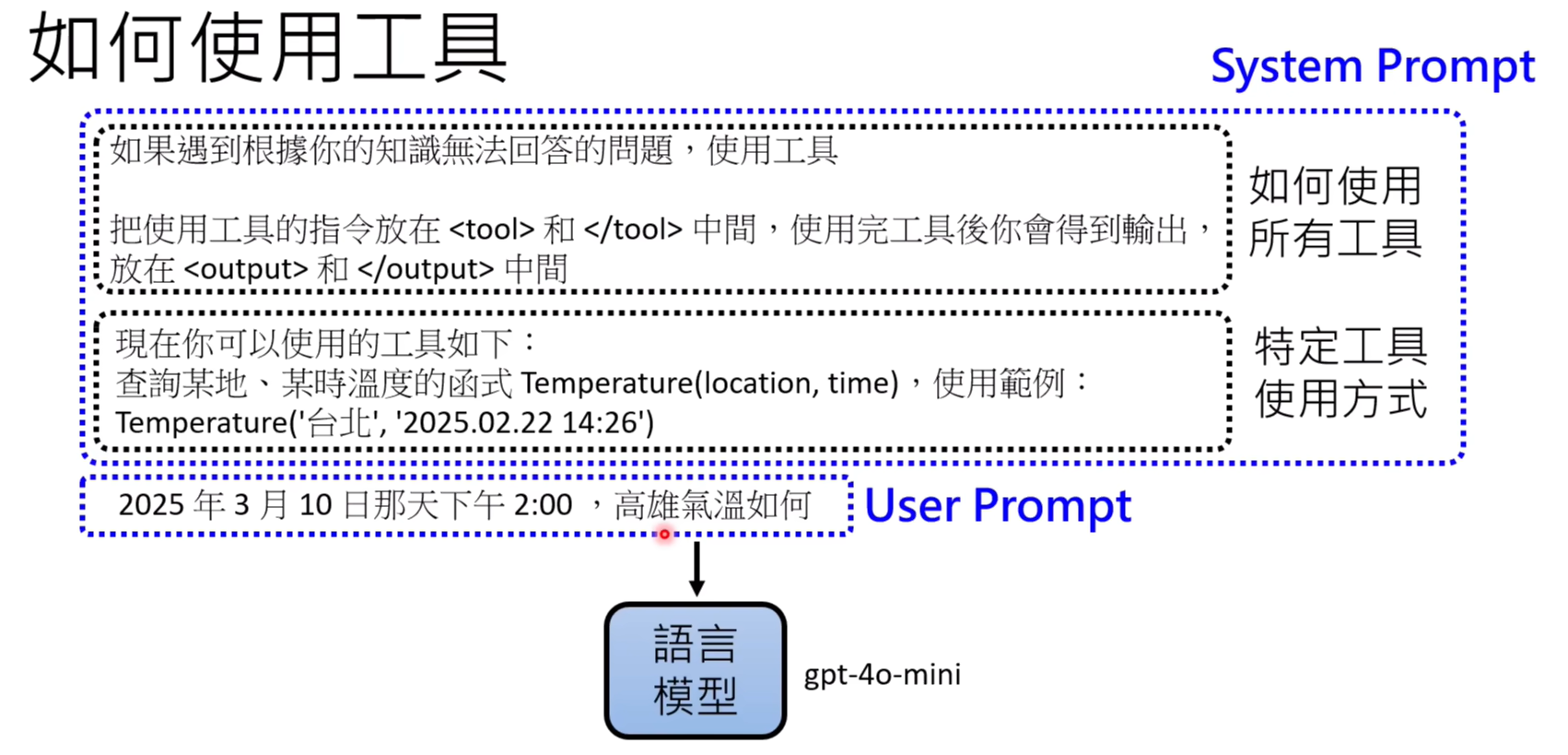
Q: sys prompt/usr prompt的区别?
在大语言模型(LLM)中,sys prompt(系统提示)和usr prompt(用户提示)有不同的角色:
- sys prompt:系统提示是由系统(比如你使用的应用、API或者开发者设置的系统配置)提前定义的,用来告诉模型一些全局性的指导信息或者背景。例如,告诉模型它的角色是什么,应该怎么回答问题,或者有哪些限制。它是给模型设置“基本框架”的部分。
- usr prompt:用户提示是直接来自用户的输入,通常是用户提出的具体问题或者任务。模型根据这个提示来生成具体的答案或者响应。
sys prompt的优先级高于usr prompt。有点类似于全局变量和函数中的传递的参数,为临时变量。
- sys prompt 就像是给模型设定了一个“背景”或“规则”。比如:告诉模型你是一个知识丰富的助手,回答问题时要礼貌、简洁。
- usr prompt 是用户直接提出的需求或问题,模型根据这个提示来生成回答。
所以,sys prompt 的优先级高于 usr prompt 是因为系统先定义了规则和背景,而用户的输入是在这些规则的框架下进行回答的。
一些相关的议题
- LLM使用工具、对于工具得到的结果,在多大程度上相信这个结果?
- 因为我们有时候search也会得到不对的结果,我们会有自己的一个判断。也就是工具得到的结果不一定对。
- LLM有没有自己的判断、对于结果是不是有置信度的判断?
什么样的外部知识比较容易说服LLM?
- 一般来说、与LLM对自己的答案的置信度有关、与工具得到答案差异程度有关(比如现在的天气是10℃/1w℃)
使用工具与模型本身的能力之间的平衡?
- 有时候不一定使用工具:相比于你自己心算5+3;与你拿出计算机,然后按下5+3,再得到结果是7.
AI Agent是否能产生并执行计划?
计划:现在为了得到一个输出,LLM得执行一系列的步骤才能得出正确的输出。
比如:下围棋—一步步下—最终目标:win
- LLM是否具有做计划的能力?
- LLM能否根据每步的行为、改变它当前的计划、为了得到最终的胜利?
- 区分:LLM会不会早就看过类似的题目、实际上不是在做计划、只是在copy已有的东西?
- 能不能强化AI Agent 的规划能力?
- 对于每步行为都广搜、暴力搜索、找到最佳的路径;同时剪枝、简化计算。