2025-3-17-Uzkent-WACV-2020
Uzkent, Burak, Christopher Yeh, and Stefano Ermon. “Efficient object detection in large images using deep reinforcement learning.” Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2020.
又找到一篇是做RL for OD的,其引用约120+。
等会看看,但是这个是2019放在arxiv上的,所以是没有添加detr/ViT的,所以是two-stage+RL。
好的,我今天上课无聊看完了。非常想吐槽,首先,这个公式这块、依托;
然后,这个实验,对比实验选用的、神奇的滑动窗口、等方法;为什么不用Faster RCNN之类的二阶段或者YOLO的来对比、我知道RL会有一些其他比较突出的参数、但是你做的是目标检测任务,难道不是应该以mAP、FPs等指标为先吗?
最后,奇妙的显卡配置,一度以为我看错了——

Uzkent-WACV-2020
奇妙实验部分
5.1. 基线方法与当前最先进模型
该部分介绍了几种用于目标检测的策略:
- Sliding Window(滑动窗口)
这是一种传统的目标检测方法,通过在大图像上使用固定策略的滑动窗口来运行检测器。- 采用两种检测器:
- 粗粒度检测器($f_d^c$),用于低分辨率图像 $x_L^j$。
- 精细粒度检测器($f_d^f$),用于高分辨率图像 $x_H^j$。
- 该方法遍历所有可能的窗口,检测所有区域。
- 采用两种检测器:
- Random Policy(随机策略)
- 该策略通过均匀分布的方式,为每个图像块随机采样概率,并进行目标检测。
- Entropy Based Policy Sampling(基于熵的策略采样)
- 先使用粗粒度检测器计算每个图像块的置信度$s_i^c$,该置信度基于检测到的目标数量计算: $s_i^c = \frac{1}{M} \sum_{m=1}^{M} c_m$ 其中,M 是检测到的目标数量,$c_m$ 表示检测到的目标得分。
- 若$s_i^c$ 超过阈值,则进一步使用精细粒度检测器$s_j^f$ 进行高分辨率检测。
- Dynamic Zoom-in Network(动态缩放网络)
- 参考了一种 state-of-the-art 方法,用于在大图像中高效检测目标。
- 该方法原本用于 640×480 图像,但不适用于 3000px 以上的大图像。因此,在实验中,对该方法进行了适配,使其能在更大尺寸的图像上运行。
- Variants of the Proposed Approach(提出方法的变体)
- 仅粗粒度检测(Coarse Level Only):只使用粗粒度策略,检测 $x_L^i$。
- 仅精细粒度检测(Fine Level Only):只使用精细粒度策略,检测$x_H^i$。
5.2. 实现细节
- Policy Networks(策略网络)
- 使用 ResNet-34 作为策略网络,并在 ImageNet 上进行预训练。
- 训练使用 4 块 NVIDIA 1080Ti GPU。
- Object Detectors(目标检测器)
- 采用 YOLOv3 进行目标检测,骨干网络为 DarkNet-53。
- 使用 单个 NVIDIA 1080Ti GPU 训练目标检测器。
5.3. 评估指标
使用以下指标评估不同方法的性能:
- AP(Average Precision,平均精度)
- AR(Average Recall,平均召回率)
- 运行时间(Run-time per image,单位 ms)
- 高分辨率图像的采样比例(Ratio of sampled HR image)
- 计算不同 IoU 阈值(0.50、0.55、0.60、…、0.95)下的 AP 和 AR。
5.4. 在 xView 数据集上的实验
数据集介绍
使用 xView 数据集进行实验,该数据集包含 60 类物体,其中:
- 训练集:846,221 张图像
- 验证集和测试集:281,228 张图像
这些图像的分辨率较大(3,000px 以上)。
目标检测器的训练
- 粗粒度检测器在 64×64 的低分辨率图像块$x_L^i$ 上运行。
- 精细粒度检测器在 320×320 的高分辨率图像块 $x_H^i$ 上运行。
- 粗粒度检测器和精细粒度检测器分别训练 65 轮和 87 轮。
策略网络的训练
- 目标检测器权重 保持固定,仅训练策略网络。
- 初始大图像被裁剪成 2,400×2,400 的块,并再划分为 16 个 600×600 的子块。
- CPNet 采用 448×448 的下采样图像进行训练,而 FPNet 采用 112×112 的子块进行训练。
- 在最终阶段,CPNet 和 FPNet 均采用 512 batch size 训练,训练轮数分别为 459 轮和 643 轮。
5.5. 定量与定性分析
效率对比:级联方法 CPNet+FPNet提供了最佳的运行时间和信息获取效率:
- AP 和 AR 分别提高 0.9%-1.2%。
- 相比滑动窗口方法,HR 采样率减少 31.5%。
- 运行时间比基线方法快 2.2 倍。
策略学习可视化:Figure 3显示了 CPNet 和 FPNet学习到的策略:

- CPNet 在 目标较小的区域 选择 HR 采样。
- FPNet 在 包含较多目标的区域 选择 HR 采样。
缩放行为分析:Figure 4显示了 CPNet 和 FPNet 缩放概率与目标数目/大小的关系:
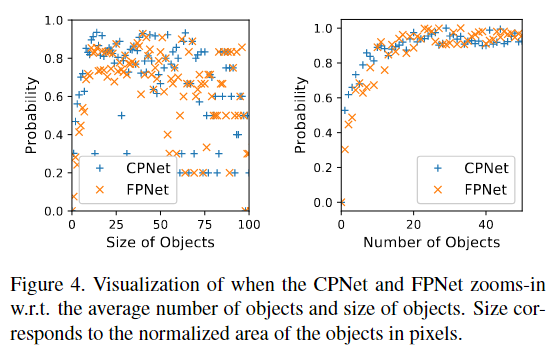
- 目标越多,缩放概率越高。
- FPNet 主要在 目标尺寸较大的区域 进行缩放。
消融实验:移除粗粒度检测器后、
- 运行时间下降,效率提高约 13%。
- HR 采样增加。
总结
滑动窗口、随机策略和熵策略是基础方法。
动态缩放网络 进行高效检测,但需要适配大图像。
提出的 CPNet+FPNet 级联方法通过策略网络学习,显著提升了运行效率和目标检测精度:
- 减少 HR 采样,提高运行速度。
- 在小目标区域使用 HR,大目标区域使用 LR,优化资源利用。
这项实验表明,通过策略网络的学习,可以在高分辨率图像检测任务中 平衡计算开销与检测精度,为高效目标检测提供了一种有效的方法。