2025-3-15-Deformable—DETR
Zhu, Xizhou, et al. “Deformable DETR: Deformable Transformers for End-to-End Object Detection.” arXiv: Computer Vision and Pattern Recognition,arXiv: Computer Vision and Pattern Recognition, Oct. 2020.
Zhou-CVPR-2020
Deformable DETR 的关键改进点
- 多尺度特征学习(Multi-scale Feature Maps)
- 传统 DETR 只能在单尺度特征上进行注意力计算,而 Deformable DETR 引入多尺度信息,提升检测小目标的能力。
- 可变形注意力(Deformable Attention)
- 普通 Transformer 是全局注意力(计算量大),Deformable Attention 只在关键点上计算注意力,降低计算量,提高收敛速度。
- 计算更高效,收敛更快
- 传统 DETR 需要 500+ 轮训练才能收敛,而 Deformable DETR 仅需 50 轮训练,大大提升了训练效率。
Deformable convolution:可变性卷积

- 通过学习形变的偏移量(offsets),可以自适应地调整感受野,从而增强特征提取能力。
- 这种方式避免了固定感受野的问题,使得卷积更加灵活。
DETR依靠元素关系建模(Transformer)、

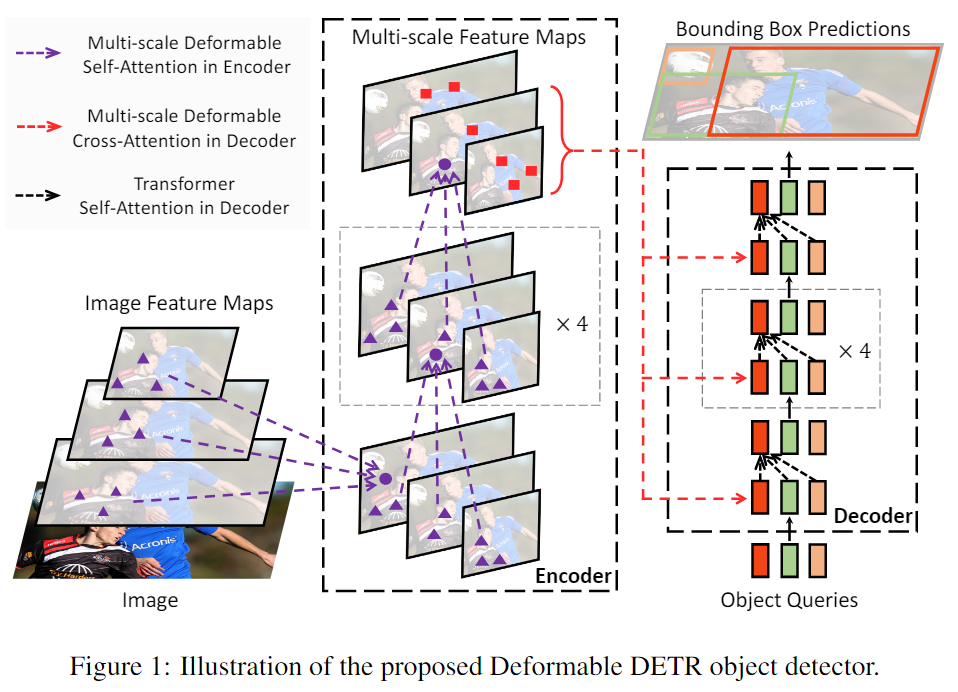
Image Feature Maps(图像特征图)
- 输入图像 经过 CNN(卷积神经网络)提取特征,得到多尺度的特征图(左侧的金字塔)。
- 这些特征图作为 Transformer 编码器(Encoder)的输入。
Multi-scale Feature Maps(多尺度特征图 & Encoder)
- 引入可变形注意力(Deformable Attention)
- 紫色箭头(Multi-scale Deformable Self-Attention in Encoder)
- 说明编码器内部采用了可变形的 自注意力机制(Self-Attention),可以在多尺度特征图之间灵活地学习信息。
- 为什么这么做?
- 传统 DETR 采用标准 Transformer,全局注意力计算量大,收敛慢。
- Deformable DETR 只在少量关键点上计算注意力,使得计算量降低、训练更快。
- 紫色箭头(Multi-scale Deformable Self-Attention in Encoder)
Bounding Box Predictions(边界框预测 & Decoder)
- 解码器(Decoder)部分使用 Object Queries 进行目标检测
- 红色箭头(Multi-scale Deformable Cross-Attention in Decoder)
- 说明解码器采用 可变形的交叉注意力(Cross-Attention),结合多尺度特征图进行目标识别。
- 黑色箭头(Transformer Self-Attention in Decoder)
- 说明解码器内部仍然使用标准 Transformer 进行 自注意力计算,确保目标特征的全局建模能力。
- 最终输出目标框(Bounding Box Predictions),即检测结果。