2025-3-14-继续实验
python ./test.py —dataset food101 —model Conv4 —method baseline —num_classes 101
Test Acc = 47.95% +- 0.69%
python test.py —dataset food172 —model Conv4 —method baseline
Test Acc = 67.41% +- 0.71%
昨天的话稍微处理了一下数据,然后发现了存在一些问题:
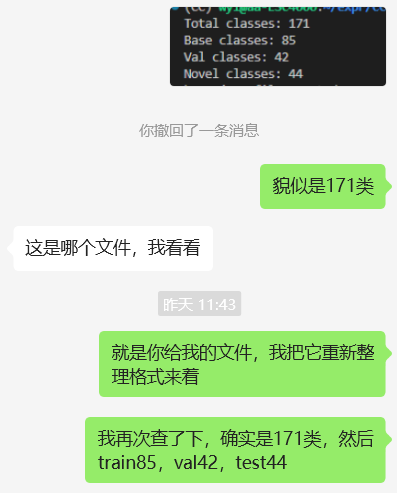
事实证明,是我数据处理有一点问题:我给数据分类成了85:42:44,但是主要原因是因为类别只有171类。
原因是类别中第47和100类的名称重复。于是修改了下名称,然后把给的json文件处理成我需要的形式,然后在CC上继续跑。
当时稍微有点疑惑,然后发现大事不妙(?)
就是有关于数据集的划分问题,师姐主要做的是开放词汇学习、需要我辅助做小样本方法来进行对比。
然后我检索数据集划分的时候,发现真是众说纷纭。
有的说是base,val,novel三类中的类别是互不相交的
但是这是不是和迁移有点像了??
然后我又看了下某few-shot方法的代码,发现真的是base,val,novel中的类别是一致,但是数据占比不同。相当于是在同类别的图片上学习,然后后续给出一张全新的图片,也要能识别出来这是同类别的。
这么说的话,感觉和普通的深度学习也好像没什么区别。
然后去开发词汇方法(OMVR)上看了下它数据集划分的代码
虽然是开放词汇,但是数据集的划分还是与上面一致(每种类别都有、只是占比不同),于是我就有点疑惑:不是说开放世界,需要能识别出之前根本就没见过的类别吗?
于是去问了GPT,下面是它的回复:
开放词汇方法(Open Vocabulary)划分特点
- 所有类别都出现在 train, val, test 中
- 也就是说,每个数据集划分都覆盖了数据集中所有的类别。
- 只是每个类别的数据在不同的划分中是不同的图片。
- 基于比例划分数据
- 一般按照
train:val:test = 50%:20%:30%(或者其他比例)来划分。- 例如,如果一个类别有 100 张图片:
- 50 张图片进入训练集
- 20 张图片进入验证集
- 30 张图片进入测试集
- 但这 不会影响类别的完整性,即训练、验证、测试集都会包含所有的类别。
疑问是:few-shot 训练集 (
train) 和测试集 (test) 是否包含不同的类别,即它们是否是不相交的类别集?答案:No,few-shot 数据集中的
train和test仍然是从相同的类别集中采样的,并没有明确执行 open-set 或 zero-shot 分割,即:
- 训练集 (
train) 和测试集 (test) 仍然共享相同的类别集,只是数据样本不完全相同。generate_fewshot_dataset()只是在已有的训练集 (train) 和验证集 (val) 上 进行 few-shot 采样,并不会影响test的类别。1. Few-shot learning 的目标
Few-shot learning 主要是希望 模型能在少量样本上进行有效学习,并在测试集上 泛化到相同类别的新样本。
- 训练集 (
train) 和测试集 (test) 通常 共享相同的类别集,只是 测试集包含不同的样本(同类别但不同图片)。- 重点在于如何从少量数据中学到类别的有效表示,并推广到新样本。
📌 例子(Few-shot 设置)
训练集 (train):
- 🍕 Pizza:3 张
- 🍔 Burger:3 张
- 🍣 Sushi:3 张
测试集 (test):
- 🍕 Pizza:新图片
- 🍔 Burger:新图片
- 🍣 Sushi:新图片
👉 目标是让模型在仅见过 3 张Pizza的情况下,学会分类新的Pizza图片。2. 为什么 few-shot 任务不需要类别不相交?
❌ 如果
train和test使用完全 不相交的类别集,few-shot 任务就会变成 zero-shot learning 或 open-set learning,这与 few-shot 任务的初衷不同:
- Few-shot 任务是 小样本情况下的学习问题,即模型在训练时见过的类别,在测试时仍然需要分类。
- Zero-shot 任务是 模型需要识别训练时完全没见过的类别,依赖 类别的语义信息(如文本描述) 或 迁移学习。
📌 例子(Zero-shot 设置)
- 训练集
- 🍕 Pizza:3 张
- 🍔 Burger:3 张
- 🍣 Sushi:3 张
- 测试集
- 🍎 Apple:新类别
- 🍇 Grapes:新类别
- 🍉 Watermelon:新类别
👉 目标是让模型在完全没见过Apple的情况下,能识别Apple,这就属于 zero-shot learning。✅ Few-shot learning 只是在相同类别上用少量样本训练,而不要求
test里必须是没见过的类别。3. Few-shot 训练集如何划分?
在 few-shot 任务中,常见的数据划分方式有:
- 标准划分(相同类别,少样本):
train、val、test共享相同的类别,但train只有少量样本。generate_fewshot_dataset()只是在train里采样少量数据,不影响test的类别。- N-way K-shot 任务(Meta-learning):
- 训练阶段,每次 随机采样
N个类别,每个类别K张图片进行训练。- 测试阶段,使用相同的
N个类别,但不同的样本进行测试。- 这种方法也不需要
train和test具有不相交的类别。4. 什么时候需要不相交类别?
如果你的任务是:
- Zero-shot learning(零样本学习):模型在
test里看到的是完全没见过的类别,需要基于语义信息推理。- Open-vocabulary learning(开放词汇学习):
test包含一些train没见过的类别,模型需要有能力推理新的类别。👉 这时候,你需要确保
train和test类别完全不重叠。5. 结论
✅ Few-shot learning 任务不需要
train和test的类别不相交,因为 few-shot 目标是在相同类别上学习如何泛化到新的样本。
✅ Zero-shot learning 或 开放词汇学习 才需要train和test具有不相交的类别。
✅generate_fewshot_dataset()只是减少train的样本数,并不会改变test的类别分布。
错误:实际上开放词汇学习+Few-Shot都不要类别不相交,据GPT说Zero-Shot方法才需要类别不相交,这一点值得商榷。