2025-2-26-Janus-Pro
Janus-Pro
整体架构:与Janus同。
改进点:
- 优化训练策略(Optimized Training Strategy)
- 扩展训练数据(Data Scaling)
- 扩展模型规模(Model Scaling)
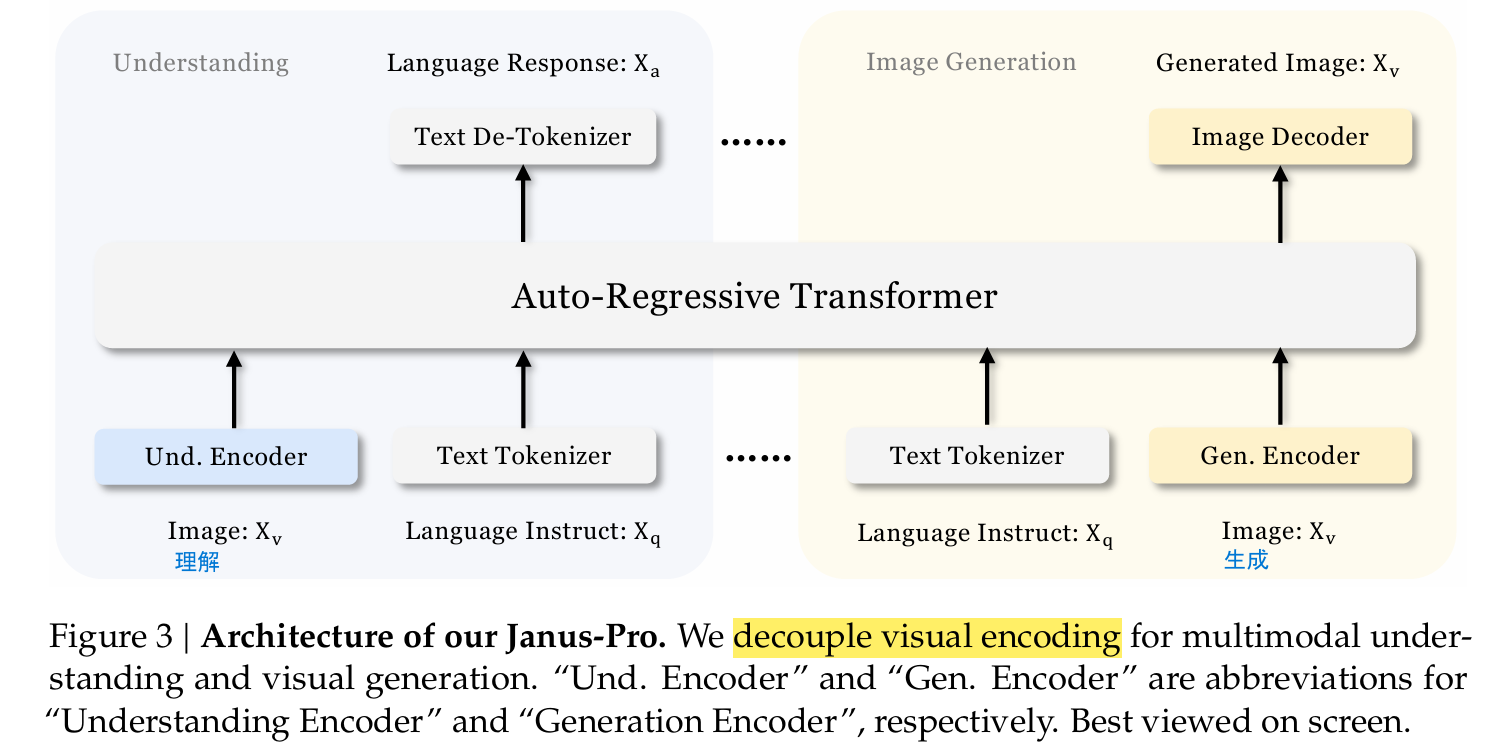
Janus-Proi采用独立的编码方法将原始输入转换为特征,然后由统一的自回归转换器进行处理。
- 多模态理解:我们使用SigLIP编码器从图像中提取高维语义特征。将这些特征从二维网格平展到一维序列,并使用理解适配器将这些图像特征映射到LLM的输入空间中。
- 视觉生成:我们使用[38]中的VQ标记器将图像转换为离散id。在将ID序列平面化为1-D后,我们使用生成适配器将每个ID对应的码本嵌入映射到LLM的输入空间中。
然后将这些特征序列连接起来形成一个多模态特征序列,随后将其输入LLM进行处理。除了LLM中内置的预测头外,Janus-Pro还在视觉生成任务中使用随机初始化的预测头进行图像预测。整个模型遵循一个自回归框架。
最优训练策略
| StageⅠ | Stage Ⅱ | Stage Ⅲ |
|---|---|---|
| 训练适配器和图像头(adaptor,image head) | 统一的预训练 | 监督微调(SFT) |
| — | 更新除理解编码器和生成编码器外的所有组件的参数。 | 建立在第二阶段的基础上,在训练期间进一步解锁理解编码器的参数。 |
| 增加了Stage Ⅰ的训练步骤,允许在ImageNet数据集上进行足够的训练。 | 放弃ImageNet数据,直接利用正常的文本到图像数据来训练模型,以基于密集描述生成图像。 | 调整了Stage Ⅲ监督微调过程中不同类型数据集的数据比例,将多模态数据、纯文本数据和文本到图像数据的比例从7:3:10更改为5:1:4。 |
数据扩展:收集了更多、不同来源的数据用于训练。
模型扩展:模型参数7B。
Janus
两个encoder:
- Unt.encoder:SigLIP 384
- Gen.encoder:llama tokensize=256