2025-2-24-Deepseek解析
我勒个豆,我写了好几天,令人感叹的效率()
感觉似乎V3的内容会多一点,然后R1和R1-Zero会比较偏向于阐述(?)
或者说是因为细节的东西没给出来,所以全是大段地阐述文字,基本框架组件和v3应该一致.
具体到奖励函数的设计,$r_i$等等,就没有详细的解释了.
[TOC]
Deepseek解析
LLM基于Transformer有三条路线:
| BERT | GPT | T5 |
|---|---|---|
| encoder | decoder | encoder&decoder |
| OpenAI | Google,清华,GLM |
早期囿于“预训练+微调”的范式(pre-training+fine-tune)
pre-training缺点:在非常大的数据集上从头训练模型需要大量计算资源和时间。
- 对数据集的要求高
- 模型参数规模要求高
- 算力要求高
post-training机制:
- SFT(Supervised Fine-Tune) :小修小改,对下游任务加训,受制于数据质量
- RLHF(GPT):引入RL,受制于打分数据
- R1:RL方法,更强
- KD(Knowledge Distillation):知识蒸馏
Fine-tune KD 数据来源是额外标注的数据集 用大模型提供的知识,让小模型拟合大模型
技术演进
- V2: MLA+MoE
- V3: DL, pre-training
- R1-Zero: RL,post-training
- R1: SFT+RL
训练发布的路径似GPT-4O/o1。R1-Zero是纯RL自我演化模型,但是表现并不好。主要原因在于RL难以训练(训练优化不可控)。
R1在R1-Zero的基础上加入SFT。二次使用SFT+RL进行训练。R1使用的预训练模型是V3,而R1的结果也反向促进了预训练V3。
Deepseek-V3
无辅助损失的负载均衡策略,多token预测训练目标,FP8混合精度技术,DualPipe流水线并行
基本架构:MLA+MoE
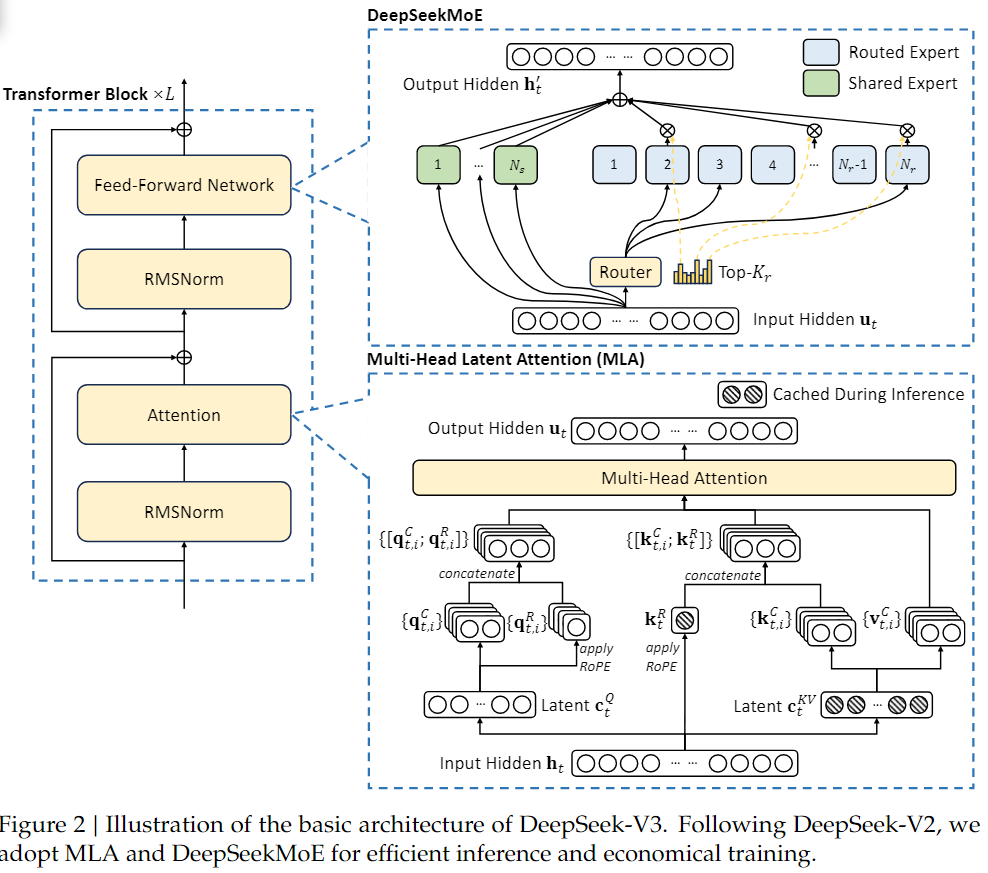
MLA和MoE都已被DeepSeek-V2验证过,相较于V2,V3的提升在于引入了无辅助损失负载均衡策略,有效降低了负载均衡过程对模型性能的影响。
MLA
Multi-head Latent Attention (MLA)(多头潜在注意力机制)
核心:对注意力键值进行低秩联合压缩,以降低推理过程中的键值(KV)缓存开销.
注意力键值-低秩联合压缩
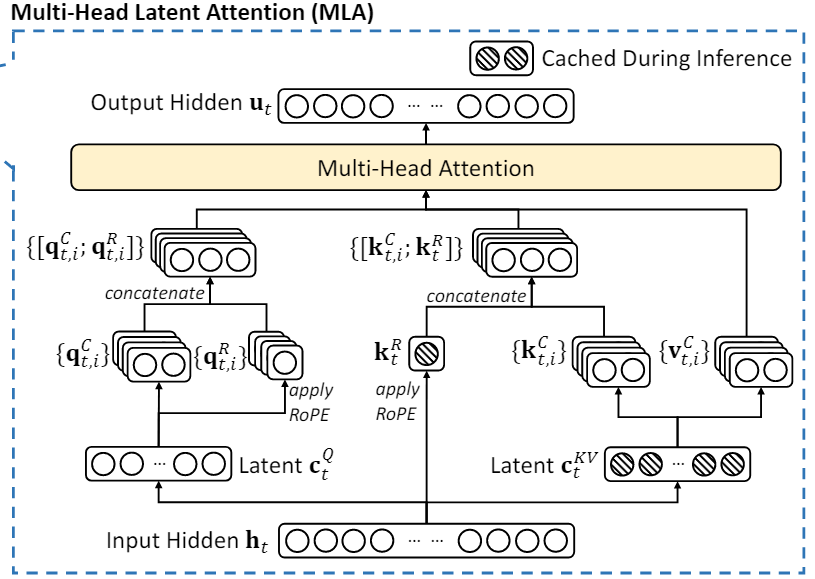
设向量维度为$d$,注意力头数为$n_h$,每个头的维度为$d_h$:
$c_t^{KV}\in \mathbb{R}^{d_c}$表示键值(Key-Value,KV)的压缩潜在向量, $d_c(\ll d_hn_h)$表示KV压缩维度.
$W^{DKV}\in \mathbb{R}^{d_c\times d}$投影变换矩阵,$h_t\in\mathbb{R}^d$是在特定注意力层中第$t$个token的注意力输入表示.
式(1)将$h_t$压缩到$\mathbb{R}^{d_c}$的维度.
式(2),(5)是分别在键值的维度下变换,$W^{UK},W^{UV}\in\mathbb{R}^{d_hn_h\times d_c}$是对应的投影变换矩阵.
式(3)用于生成携带旋转位置编码(Rotary Positional Embedding, RoPE)的解耦键$k^R_t$,作用是在注意力计算过程中引入位置信息.
式(4)是将$k_{t,i}^C,k_t^R$连接起来.
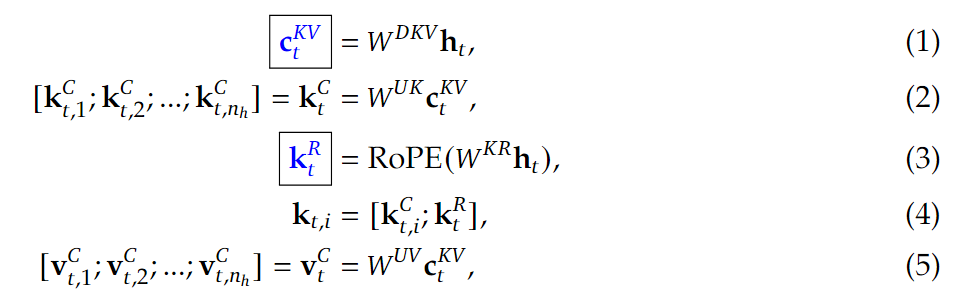
注意力查询-低秩压缩
For the attention queries, we also perform a low-rank compression, which can reduce the activation memory during training.
$c_t^Q\in \mathbb{R}^{d_c’}$表示查询(Query)的压缩潜在向量($d_c’\ll d_hn_h$,查询压缩维度),步骤与KV一致.
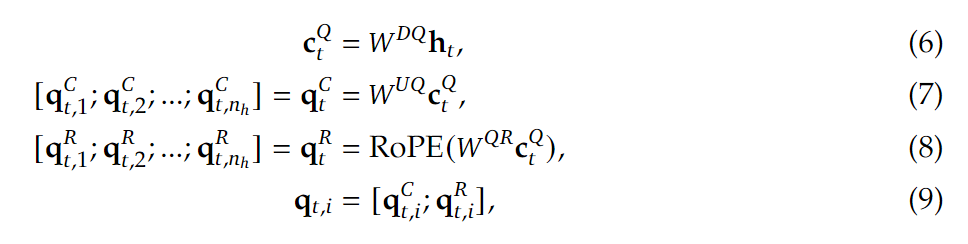
组合QKV,得到注意力机制的最终输出$u_t$:
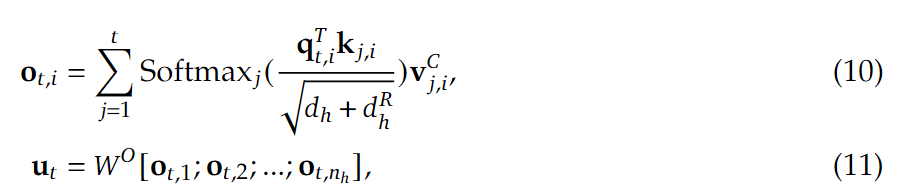
DeepSeekMoE+无辅助损失负载均衡机制
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
Deepseek用DeepSeekMoE替换FFN(Feed-Forward Networks,FFN),DeepSeekMoE相较于传统的MoE架构,采用了更细粒度的专家分配机制(Router)+将部分专家设置为共享专家(Shared Expert).
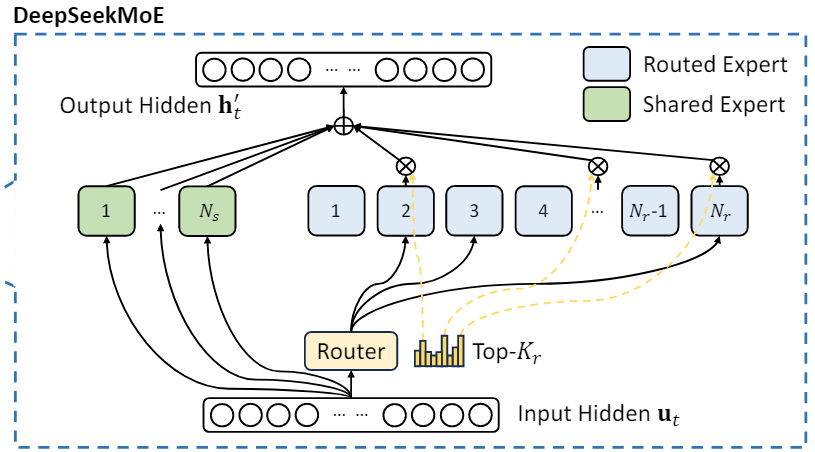
设第$t$个token的FFN输入为$u_t$,其输出为$h_t’$(这又将成为下一个的输入)
式(12)中$N_s,N_r$是共享专家(Shared)和路由专家(Routed)的数量. $FFN_i^{(s)}$ 和 $FFN_i^{(r)}(\cdot)$ 分别代表第 $i$ 个共享专家和路由专家的处理函数.$g_{i,t}$代表第 $i$ 个专家的权重系数.
再从式(15)开始向上看,$s_{i,t}$ 表示 token 与专家间的相关度,$e_i$ 代表第 $i$ 个路由专家的特征向量
$\mathrm{Top}k(\cdot, K_r)$ 函数返回第 $t$ 个 token 与所有路由专家计算得到的相关度分数中最高的 $K_r$ 个值, $K_r$ 表示被激活的路由专家数量.
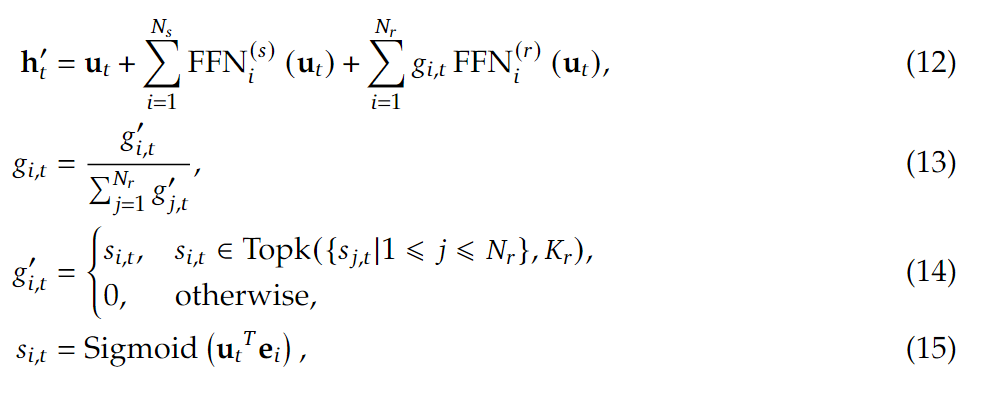
无辅助损失负载均衡:MoE中不平衡的专家负载会导致路由崩溃,在专家并行场景中降低计算效率.
此项与式(14)的区别是引入了偏置项$b_i$,并将其添加到相应的亲和度分数$s_{i,t}$中以确定TopK路由.
在这种设计中,偏置项仅用于路由选择,而门控值(用于与 FFN 输出相乘)仍基于原始相关度分数 $s_{i,t}$ 计算。不改变原本的计算逻辑,保证模型在调整负载时不会因为引入辅助损失而对原本的功能产生干扰,在不添加额外损失函数的情况下,实现专家负载均衡 。
训练过程中,系统会实时监控每个训练步骤中所有批次的专家负载分布。在每个步骤结束时:
- 对于负载过高的专家,其偏置项会减少$\gamma$ ;
- 对于负载不足的专家,其偏置项会增加 $\gamma$;
其中$\gamma$是控制偏置更新速率的超参数。
序列级辅助损失补充机制:虽然 DeepSeek-V3 主要采用无辅助损失策略来实现负载均衡,但为了防止单个序列中出现显著的负载不均衡现象,模型还引入了补充性的序列级平衡损失.
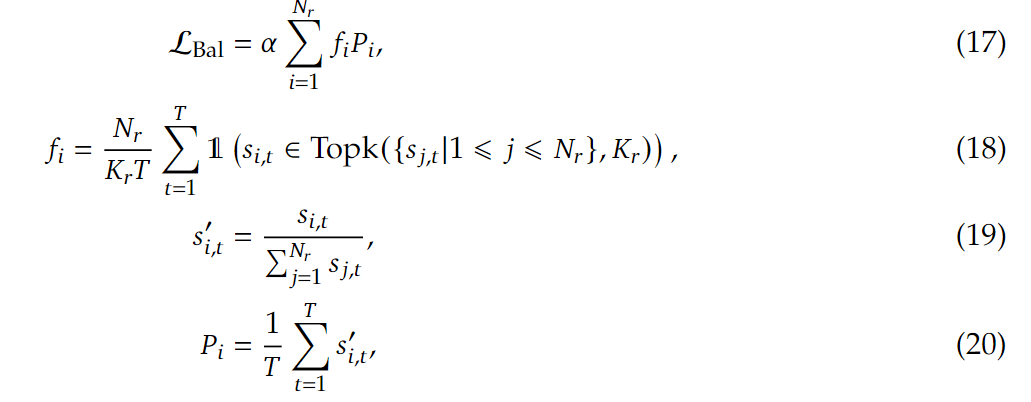
$\alpha$:超参,平衡因子,被设置为极小.通过对$f_i$和$P_i$的加权求和得到平衡损失.
| 式 | 目的 | 说明 |
|---|---|---|
| (17) | 平衡损失$\alpha$ | 平衡因子$\alpha$是一个超参数. |
| (18) | 计算$f_i$ | 其中$\mathbb{1}(\cdot)$是指示函数,如果括号内条件成立,函数值为1,否则为0 . $K_r$是被激活的路由专家数量。$f_i$衡量了专家$i$在序列中被选中处理token的频率。 |
| (19) | 计算$s_{i,t}’$ | $s_{i,t}$是token与专家$i$间的相关度,$s_{i,t}’$是将相关度进行归一化,计算专家$i$的相关度在所有专家相关度总和中的占比。 |
| (20) | 计算$P_i$ | 对归一化后的相关度在序列的所有token上取平均值,得到专家$i$在该序列上的平均相关度占比。 |
$f_i$高,表示负载重.平均相关度占比 $P_i$ 比较大有:
- btoken与专家相关性持续较高:在单个序列的多个时刻 $t$ 中,若token与专家 $i$ 的相关度 $s_{i,t}$ 都相对较高 ,根据公式 $s_{i,t}’ = \frac{s_{i,t}}{\sum_{j=1}^{N_r} s_{j,t}}$ ,归一化后的 $s_{i,t}’$ 也会较大。再经过公式 $P_i = \frac{1}{T} \sum_{t=1}^{T} s_{i,t}’$ 对整个序列上的 $s_{i,t}’$ 取平均,就会使 $P_i$ 较大。这意味着该专家与序列中的多个token匹配程度高,可能被频繁选中处理token。
- 其他专家相关度普遍较低:当其他专家与token的相关度 $s_{j,t}$($j\neq i$ )普遍较低时,即使专家 $i$ 与token的相关度 $s_{i,t}$ 并非极高,根据归一化公式 $s_{i,t}’ = \frac{s_{i,t}}{\sum_{j=1}^{N_r} s_{j,t}}$ ,分母变小,$s_{i,t}’$ 也会变大,最终使平均相关度占比 $P_i$ 较大 。 这种情况下,专家 $i$ 相对其他专家在处理序列中的token时更具优势,负载可能较高。
为什么要用MoE取代FFN(为什么是MoE)
解决MoE中负载不均—>负载均衡
多Token预测机制(MTP)
在语言模型里,token 可以理解成把一句话拆分成的一个个小单元,比如单词或者字。以前的模型通常一次只预测下一个 token ,而 MTP 是让模型一次能预测每个位置后面的多个 token。比如输入 “我喜欢”,普通模型可能只预测下一个词,像 “吃”,但 MTP 能预测出 “吃美食” 这样多个词。
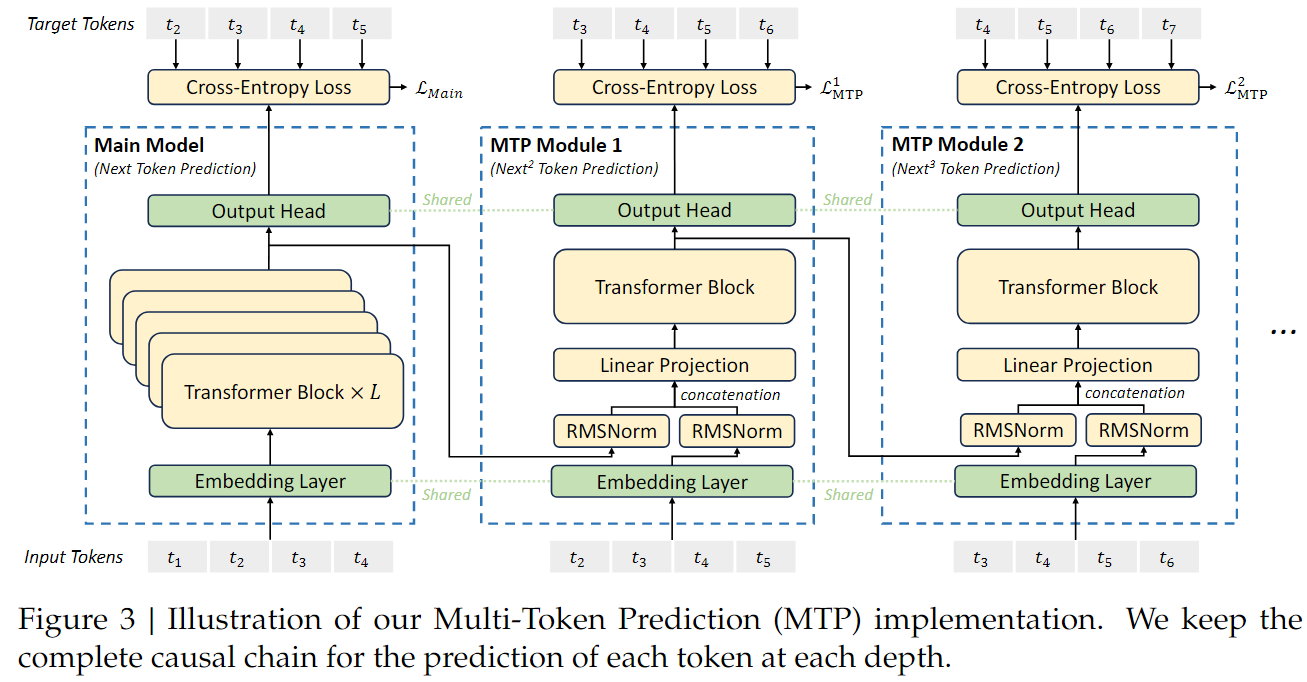
MTP Module
模型采用$D$个串联模块来预测$D$个额外的token.每个MTP模块(第$k$个)包括:共享向量层$Emb(\cdot)$,共享输出头$OutHead(\cdot)$,一个Transformer模块$TRM_k(\cdot)$,一个投影矩阵$M_k\in\mathbb{R}^{d\times 2d}$.
- Embedding Layer
- Output Head
- Transformer Block
- Linear Projection
对于输入序列中第$i$个token$t_i$,在第k层预测时模型先将两个向量进行组合$h_i^{k-1},t_{i+k}$,通过线性投影:
其中$[\cdot; \cdot]$表示连接操作。
特别地,当$k = 1$时,$\mathbf{h}_i^{k - 1}$指的是主模型给出的表示。
对于每个多token预测(MTP)模块,其嵌入层与主模型共享。
组合后的$\mathbf{h}_i^{\prime k}$作为第$k$层深度的Transformer模块的输入,以生成当前深度的输出表示$\mathbf{h}_i^{k}$:
其中$T$表示输入序列的长度,${i:j}$ 表示切片操作(左右边界都包含)。最后,以$\mathbf{h}_i^{k}$作为输入,共享的输出头将计算第$k$个额外预测token $P_{i + 1 + k}^{k} \in \mathbb{R}^V$的概率分布,其中(V)是词表大小:
后训练方法
SFT
对每个训练实例,系统生成两类 SFT 样本:一类是问题与原始答案的直接配对,另一类则引入系统提示词,将其与问题和 R1 答案组合。系统提示经过优化设计,包含了引导模型生成具有自我反思和验证机制响应的指令。
在RL阶段,模型通过高温采样生成响应,即使在没有明确系统提示的情况下,也能有效融合 R1 生成数据和原始数据的特征。经过数百轮RL迭代,中间模型成功整合了 R1 的响应模式,显著提升了整体性能。随后,研究采用拒绝采样方法,利用专家模型作为数据源,为最终模型筛选高质量的 SFT 数据。这种方法既保持了 DeepSeek-R1 的高准确性,又确保了输出的简洁性和有效性。
- 非推理数据处理: 对于创意写作、角色扮演和基础问答等非推理任务,系统利用 DeepSeek-V2.5 生成响应,并通过人工标注确保数据质量。
- SFT 训练配置: 研究对 DeepSeek-V3-Base 进行了两轮 SFT 数据集训练,采用余弦衰减的学习率调度策略,初始学习率为 5×10−6,逐步降低至 1×10−6。训练过程中采用多样本序列打包技术,同时通过样本掩码机制确保各样本间的独立性。
RL
奖励模型设计: 在强化学习过程中,系统同时采用规则型和模型型两种奖励模型(Reward Model, RM)。
在强化学习里,模型会不断尝试给出各种输出。而奖励模型就是用来判断这些输出的质量,然后给模型一个分数。如果输出好,就给高分奖励,模型就知道这样做是对的;如果输出不好,就给低分,模型就会尝试调整,争取下次得到高分。
| 规则型奖励模型 | 模型型奖励模型 | |
|---|---|---|
| 适用场景 | 适用于那些答案可以通过明确规则来判断的任务。比如数学问题,答案是确定的,还有 LeetCode 编程题,运行代码就能知道对不对。 | 一种是有标准答案,但答案形式比较多样灵活的问题;另一种是像创意写作这种没有固定标准答案的任务。 |
| 评估方式 | 像数学题,要求模型把答案写在特定地方(方框内),这样就可以用设定好的规则自动检查答案对不对。编程题则通过编译器运行测试用例,如果代码能正确处理这些测试用例,就说明写得对,能得到好的反馈。 | 对于有标准答案的,奖励模型会对比模型输出和标准答案,看它们匹配得怎么样;对于创意写作这类,奖励模型会从整体上看问题和回答是不是合适、质量高不高。而且这个奖励模型是在 DeepSeek-V3 的 SFT checkpoint(一种训练后的模型状态)基础上训练出来的。 |
| 优点 | 因为是按照明确规则判断,所以很可靠,模型没办法耍小聪明蒙混过关,比如不能随便写个答案来骗奖励。 | 增强可靠性的方法:为了让奖励模型更可靠,用来训练它的数据不仅有最后的评分,还详细记录了为什么给这个评分的推理过程。这样就能减少在特定任务中,奖励模型给出不合理评分(奖励扭曲)的情况 。 |
GRPO
GPRO(Group Relative Policy Optimization):防止策略更新过大、不稳定导致崩溃;稳定策略优化过程。

损失函数:
其中$\mathbb{E}$的下标表示两个随机变量,$q$是query(输入的固定查询),$o_i$是生成的回答$i$-th,$o_i$组成的回答样本空间是$G$(换句话说,就是所有回答构成的样本空间)。$\pi_{\theta}(o_i|q)$表示在$\theta$这个策略模型下、输入$q$(潜状态)、输出$o$(某回答)的概率。$\theta_{old}$表示是之前的原策略模型(以助于更新迭代)。
$A_i$相当于给$\{o_1,o_2,\dots,o_{t-1},o_t,\dots\}$生成的回答序列打分函数。
weight是重要性采样,$w>1$表示倾向于选择此$A_i$
但此损失函数未体现出“方向感”、也未体现出在各种情景下场景。
奖励函数:
$A_i$完全取决于“方向”$r$,基于规则的设计,但是未披露。
Deepseek-R1-Zero
GRPO同上.
基于推理链CoT设计奖励函数
区分RLHF(?)黑箱深度学习
我的疑问是:这不是也是强化学习吗?怎么会也是“黑箱”?
解题思路模板化:
- 按步骤给分(每步的结果准确性、格式、得到的相应奖励)
- 奖励汇总
- 得到最终得分

存在问题
可读性和语言混合方面存在困难$\rightarrow$为贴近人类数据,使用SFT.
- 生成结果符合人类预期,但是人类看不懂
- 中英混杂\语无伦次
Deepseek-R1
流程:
| 一次SFT | 一次RL | 二次SFT | 二次RL |
|---|---|---|---|
| 冷启动 | 面向推理的RL | 拒绝采样与监督微调 | 全场景RL |
| (可控)用SFT优化强化学习的起始点 | 准确性奖励+语言一致性奖励 | ||
| “人工过滤+后处理”收集一批数据,定义了输出数据格式样例;用SFT训练得到能生成清晰思维链的初始策略. | 针对地给出解题思维链,得到奖励函数 | 用RL训练地策略生成数据,人工筛选,过滤,优化,SFT |
纸笔记
现在我的想法就是:
利用deepseek的思路,或者仿照其模块,迁移到目标检测中。但是迁移是重点,涉及强化学习,奖励函数的设计。
中间必有很多难点呢。