2025-1-11-Object_Detection
1.11的任务:
- [x] 看综述*2:od,然后写相关的阅读报告,规划一下怎么做那个事儿。
- [x] 规划一下SE大作业的提交
- [x] 日语课*5:先复习一下初日上的课开始吧
- [x] 入党材料整理归档:主要还剩下什么材料需要弄?—弄完了1.14花了一个下午555,5h左右
就是在不停的写、写错、用刚擦擦、按红手印、写、打印、打错、重新打印…
Object Detection
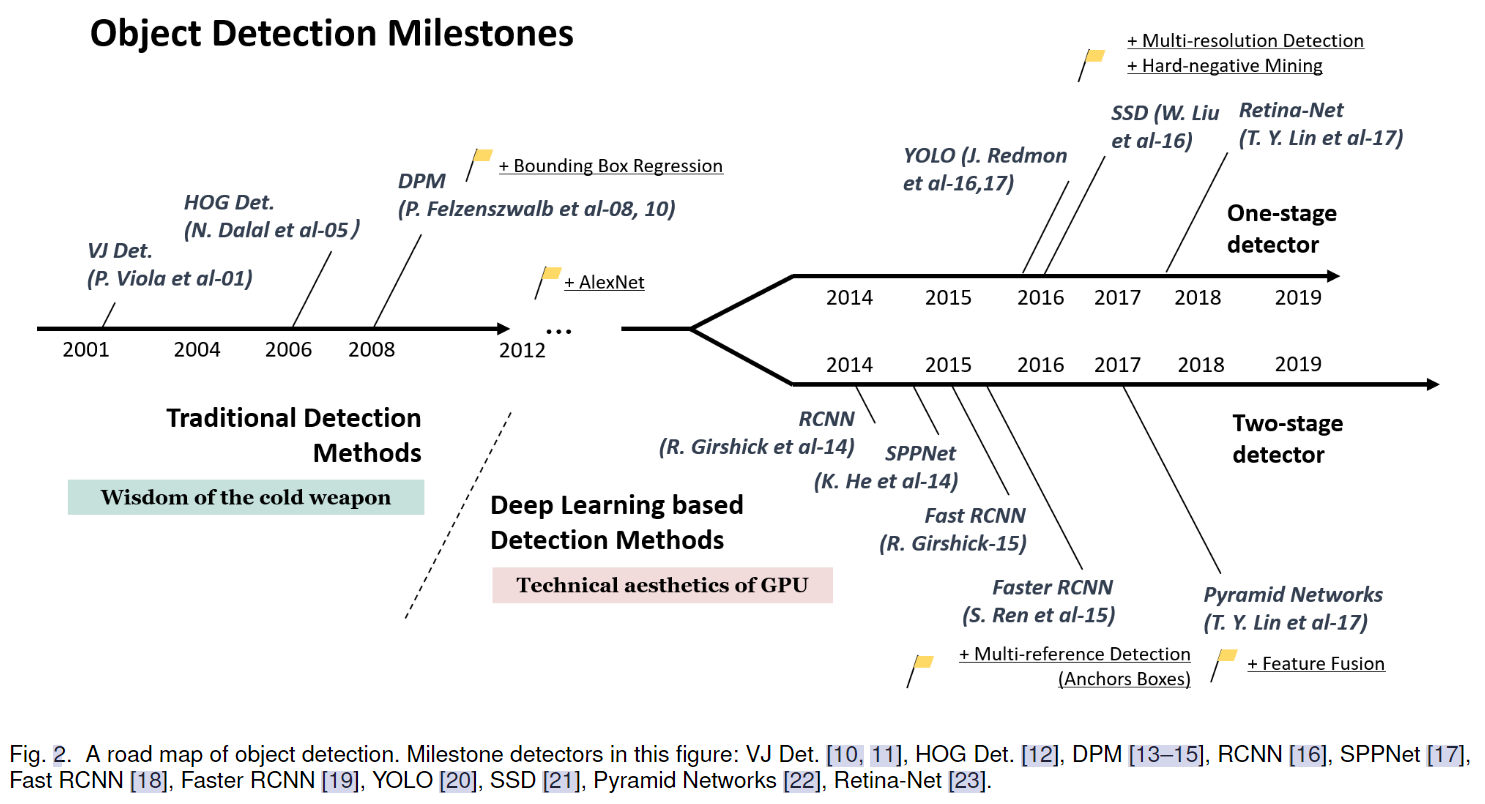
- one-stage: CNN网络进行回归,YOLO系列
- two-stage:Faster-RCNN等(两阶段多了预选步骤)
Two-Stage
第一阶段:生成候选区域(Region Proposals),即识别可能包含目标的位置。
第二阶段:对这些候选区域进行分类和边界框回归。
RCNN[1]-2014
方法:选择性搜索(Select Serach,SS) obj candidate boxes中的一些可能的对象候选框、然后对这些框resize成同样的大小、然后使用pre-train CNN(on ImageNet)上提取特征、最后使用Linear SVM来预测每个候选框内的对象是否存在、并进行识别。
选择性搜索算法:为了提升区域选择效率而使用的算法,该算法相较于穷举法有较大提升,其本质是图像分割算法。首先初始化区域集,计算相邻区域相似度,具有高相似度区域合并到一起。具体的相似度计算分为四个子模块(颜色、纹理、尺度、填充)。颜色和纹理是判断区域相似度的基本要素;尺度相似度则是为了避免合并后的区域不断吞并周围区域,造成无效的区域划分;填充相似度则是为了解决物体间的包含关系(如:车轮在汽车上、眼睛在动物身上)。最终将四个模块归一化求和计算。
CNN:用于提取候选区域的图像特征,这一步中可以采用的卷积神经网络可以有很多种(Resnet、Inception、VGG等),最初的RCNN仅提取网络的高层特征,即被多次下采样后的高级抽象特征。因此无法很好的提取小目标。
SVM:用于对特征进行类别分类,使用n个svm组成的权值矩阵(n为分类数)与特征矩阵相乘,得到最终的概率矩阵。使用非极大抑制对每类样本的进行处理剔除重叠建议框,保留高分框。SVM本质上是二分类分类器,通过核技巧将特征映射到高维空间来处理线性不可分样本,通过叠加多个SVM分类器可以处理这样的多分类问题(也称为One-vs-All (OvA) 或 One-vs-Rest 方法)。
线性回归模型:用于微调非极大抑制筛选后的边界框。在训练期间,通过比较预测的边界框和真实目标边界框之间的差异来计算回归损失。回归损失用于调整回归器的权重,以使其能够更准确地预测边界框的位置。
效果:VOC07-mAP:33.7%->58.5%
缺点:速度超慢。原因是overlap的候选框太多了、每个都要计算。一张图会产生近2,000个候选框,一张图片运行在GPU上需要14s;此外,需要分开训练CNN\SVM\线性回归模型,因此无法做到端到端训练;因此推理速度极慢且占用内存大。
SPPNet解决了此问题。
SPPNet[2]-2014
方法:引入空间金字塔池化层(Spatial Pyramid Pooling Layer,SPP),让CNN不用固定输入的大小,都能输出一致长度。特征图只会被计算一次、然后生成的固定长度的任意区域的表征来训练CNN,避免重复计算卷积。
效果:比RCNN快20倍以上、VOC07-mAP:59.2%
缺点:SPPNet只是微调(fine-tune)了卷积层,忽略了前面的层;是多阶段训练(multi-stage training)
Fast RCNN[3]-2015
基本框架:选择性搜索算法(SS)+CNN+ROI pooling+softmax+线性回归模型
方法:在同一个网络框架下,同时训练检测器和边界框回归器。RCNN中将每个感兴趣区域转换成相同尺寸再使用CNN提取特征,每个感兴趣区域分别提取特征消耗计算资源极大。fast-RCNN将整张图片输入CNN获得整体特征,再将选择性搜索算法的感兴趣区域投影到图像中,获得相应的特征矩阵。然后将每个特征矩阵经ROI pooling缩放到7*7大小特征图,特征图再输入进softmax分类器与线性回归模型中对类别和边界框位置进行预测。在训练和预测速度上相较于RCNN有较大提升。
ROI pooling:实际上是将图像每个维度划分为7*7的区域,对每个区域执行最大池化。
损失计算:不同RCNN训练时分开计算边界框和分类损失,fast-RCNN将特征图并联输入到softmax分类器与线性回归模型中,因此将分类损失与边界框损失的和作为最终损失值。
效果:比RCNN快200倍以上、VOC07-mAP:58.8%->70.0%
缺点:选择性搜索仍然较为耗时,对小目标的检测性能仍然较差。训练速度被proposal detection限制、Faster RCNN解决。
Faster RCNN[4]-2015
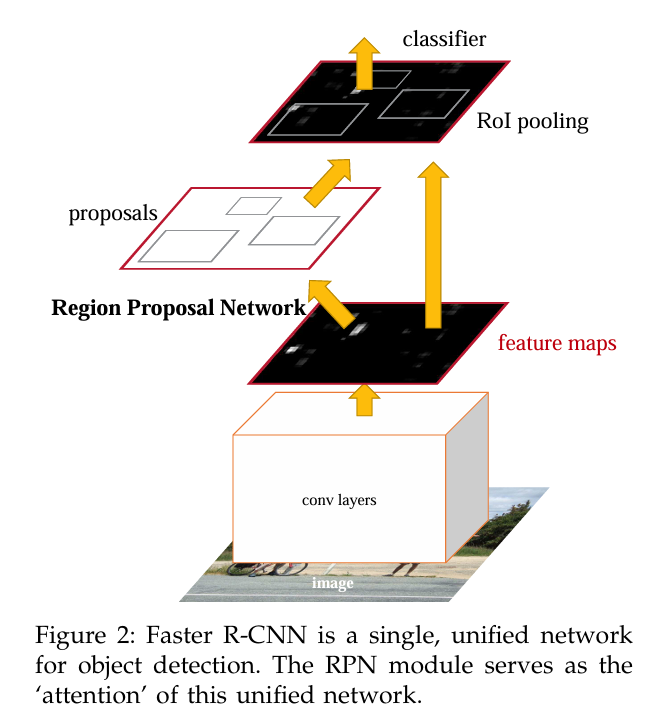
基本框架:CNN+RPN+ROI pooling+softmax+线性回归模型
改进:使用RPN替换选择性搜索(并不是指在原作用位置直接替换),其他结构与fast-RCNN无异。因为使用RPN输出边界框,无论是算法速度还是生成边界框的数量,都极大缩减了预测时间。
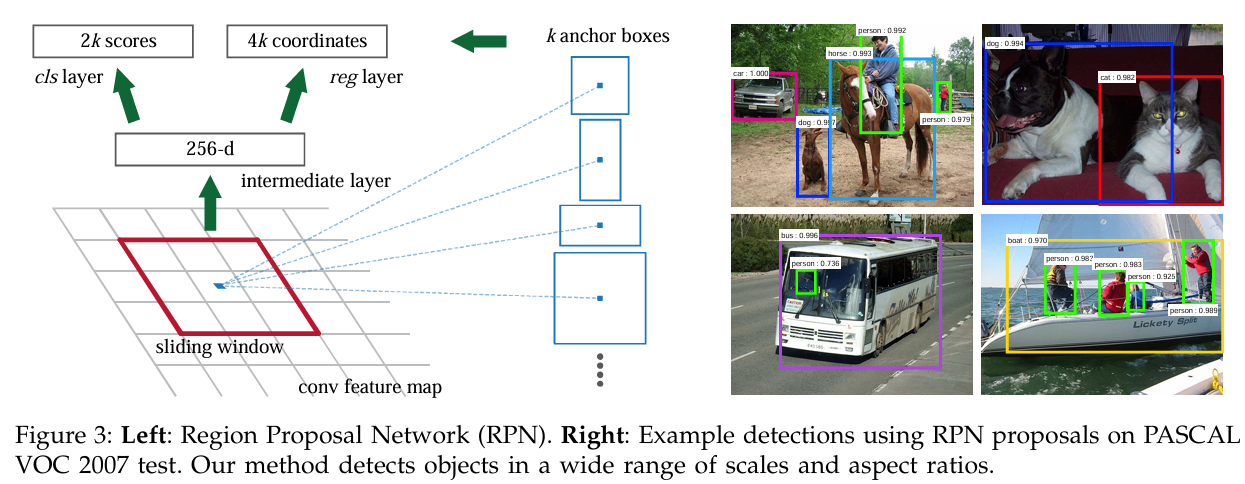
RPN:不同于SS作用于原图,RPN作用在特征图,因此RPN中一个滑块中对应的原图作用面积会是anchor面积的数倍,这个倍数取决于CNN的卷积以及池化层的分布情况。具体来说每个滑块中的anchor对应到原图上的尺度有三种(128^2,256^2,512^2)比例也有三种(1:1,1:2,2:1)。RPN会在特征图中历遍所有像素,但不是所有anchor都会被保留,对于VGG作为backbone的情况只保留256个anchor,只保留IOU大于0.7(或IOU最大)与IOU小于0.3的anchor。
损失计算:论文中采用分部式计算,也可以直接采用联合训练方法。分部式计算主要是将RPN的训练与fast-RCNN训练分开,先训练RPN参数,再用RPN生成边界框训练fast-RCNN,然后使用fast-RCNN的训练参数微调RPN参数以微调边界框,最后再微调fast-RCNN全连接层参数。
FPN[5]-2017
Feature Pyramid Networks
Pyramid Networks:使用图像金字塔构建特征金字塔,每个尺度单独计算特征。虽然可以获得不同尺度的特征,但是计算资源占用大,且推理时间长。
RCNN系列:对图像进行卷积池化操作后只提取最后一层的高级语义特征,因此无法很好的提取小目标,但它的推理速度快且计算资源占用少。
下图中(c)是使用金字塔特征分级,是将a和b两种方法的长处结合,将图像卷积池化后的特征分别计算,得到不同尺度的特征。兼具速度与特征量。但是特征的鲁棒性不强,浅层特征较弱,割裂计算无法发挥这些浅层特征的作用。
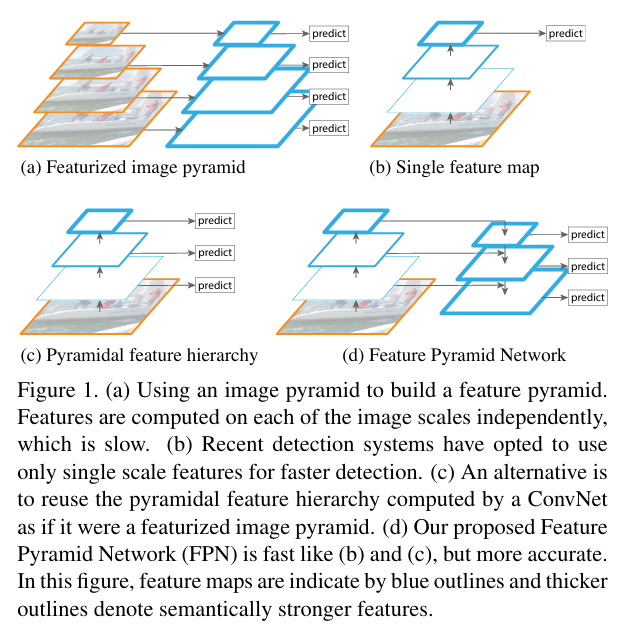
(d)FPN方法本尊,使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
方法:先将除第一层外的各层用1*1*256卷积统一通道数,将统一通道数后的各层从最高层开始,最高层经上采样后维数与下一层一致,将最高层特征直接与下一层相加,以此类推,得到每层的输出特征,具体流程看下图。注意这里还使用了maxpool池化生成了p6特征,p2~p6会输入到rpn中,分别使用不同尺寸的anchor(32^2,64^2,128^2,256^2,512^2)进行训练。分别对应识别最小到最大的目标。
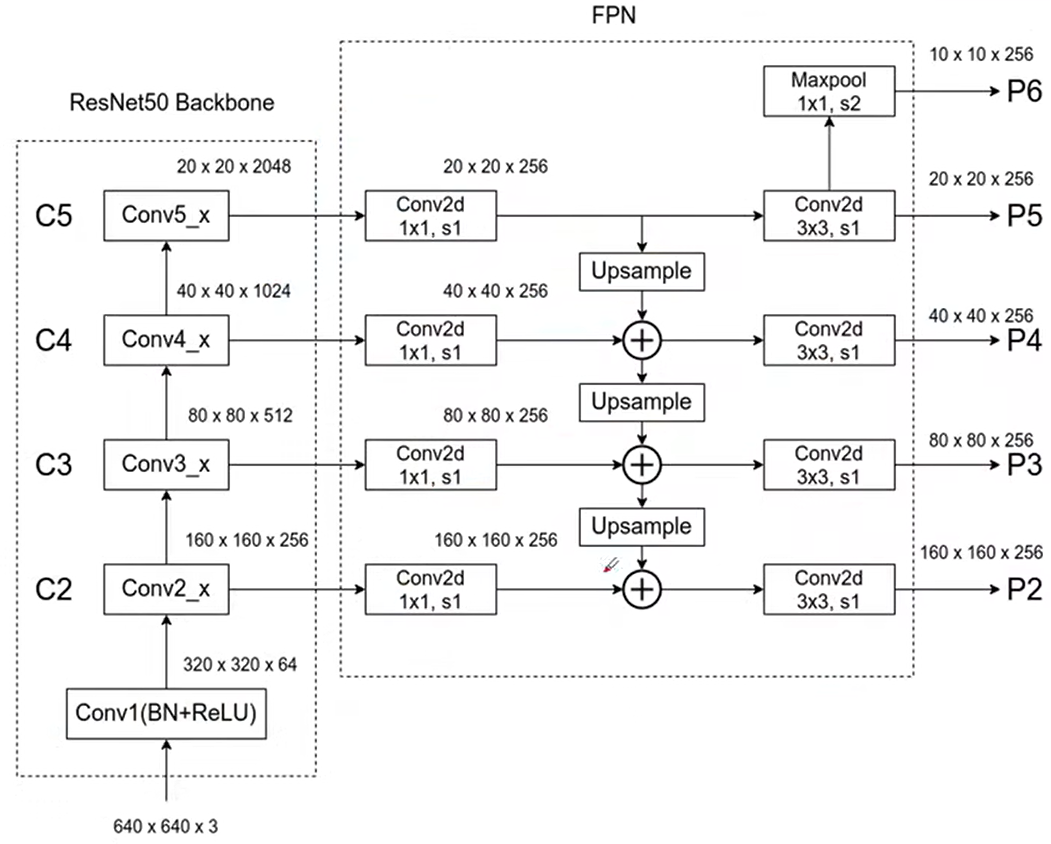
效果:COCO mAP:31.6%->33.9%. 在 ResNet-50 和 ResNet-101 骨干网络上,这个框架加进来的格外计算开销小、训练时间和推理速度相比基础 Faster R-CNN 基本保持一致,但检测性能显著提高。
缺点
- 对小目标的依赖:对极小目标的处理仍然存在局限,依赖更高分辨率的输入。
- 复杂性增加:自顶向下路径和横向连接的引入,增加了一定的实现复杂度。
- 资源需求:在较深的网络(如 ResNet-101)上,内存需求较高。
Mask-RCNN[6]-2017
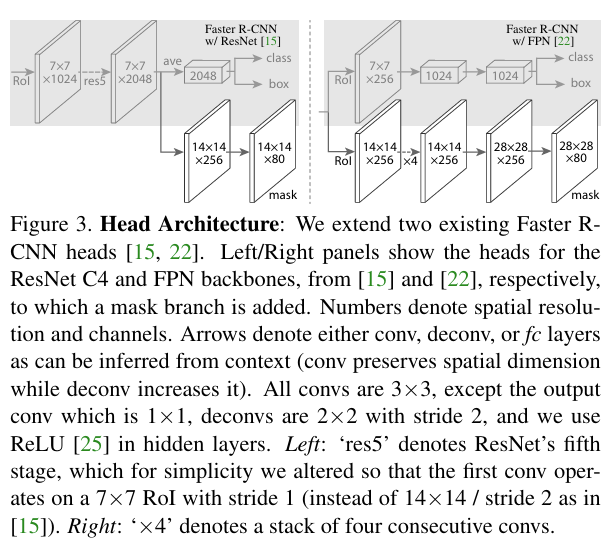
Mask R-CNN 是 Faster R-CNN 的扩展,增加了一个用于实例分割的分支,使模型能够同时预测目标的类别、边界框和精确的像素级分割掩码。
框架:
- 两阶段检测架构:
- 第一阶段:区域建议网络(RPN)生成候选框。
- 第二阶段:对候选框进行分类、边界框回归,并生成对应的分割掩码。
- 新增分割分支:
- 在每个候选区域(RoI)上,Mask R-CNN 使用全卷积网络(FCN)生成固定尺寸的分割掩码(如 28×28)。
- RoIAlign 对齐:
- 引入 RoIAlign 操作,解决了 Faster R-CNN 中 RoIPool 的量化误差问题,实现更精确的像素对齐。
- RoIAlign 使用双线性插值进行特征提取,大幅提高了分割精度。
- 独立的掩码和类别预测:
- Mask R-CNN 为每个类别独立预测掩码,而不是通过多类别分类交叉熵预测掩码,从而避免类别间的竞争。
改进:增加分割分支,实现了目标检测和实例分割的统一框架;掩码预测和类别预测独立进行,避免类别间的冲突,提高了分割精度。
实验结果:ResNet-101-FPN:Mask mAP = 35.7%,AP50 = 58.0%,AP75 = 37.8%
- 使用 ResNet-101-FPN 骨干网络,Mask R-CNN 的推理速度为 5 fps,训练时间约为 1-2 天(8 张 GPU)。
- Mask 分支只增加了约 20% 的计算开销。
缺点:在高分辨率图像和深度网络上,训练和推理的内存需求较大;对于密集目标的分割任务,仍可能存在性能瓶颈。
One-Stage
核心:速度快,适于实时检测,基于视频来做的话,速度要求快。
缺点:比起two-stage来说,效果不会来好。
最快的时候可达200FPS
YOLO[7]-2016
使用单个神经网络应用到完整的图片中。

方法:提出 YOLO,一个端到端的单阶段目标检测框架,将目标检测作为回归问题统一建模。输入图像直接映射到类别概率和边界框,利用全卷积网络(CNN)实现快速推理。YOLO 将图像划分为 S×S 网格,每个网格预测目标类别和边界框。
效果:比两阶段方法(如 Faster R-CNN)快 100 倍以上。
- fast version:VOC07-mAP:52.7%,155fps
- enhanced version:VOC07-mAP:63.4%,45fps
缺点:
- 对小目标检测不友好,特别是在密集目标场景中,检测性能有限。
- 难以处理目标之间的重叠区域。
RetinaNet[8]-2017
效果:VOC07-mAP@.5:59.1%, mAP@[.5,.95]:39.1%
方法:提出 Focal Loss,用于解决单阶段检测模型(如 RetinaNet)中正负样本不平衡问题。通过对易分类样本降低权重,使模型更专注于难分类样本,提高小目标的检测性能。
缺点:
- 增加了损失函数的复杂性。
- 在极度不平衡的数据分布中需要仔细调整超参数。
EfficientDet[9]-2020
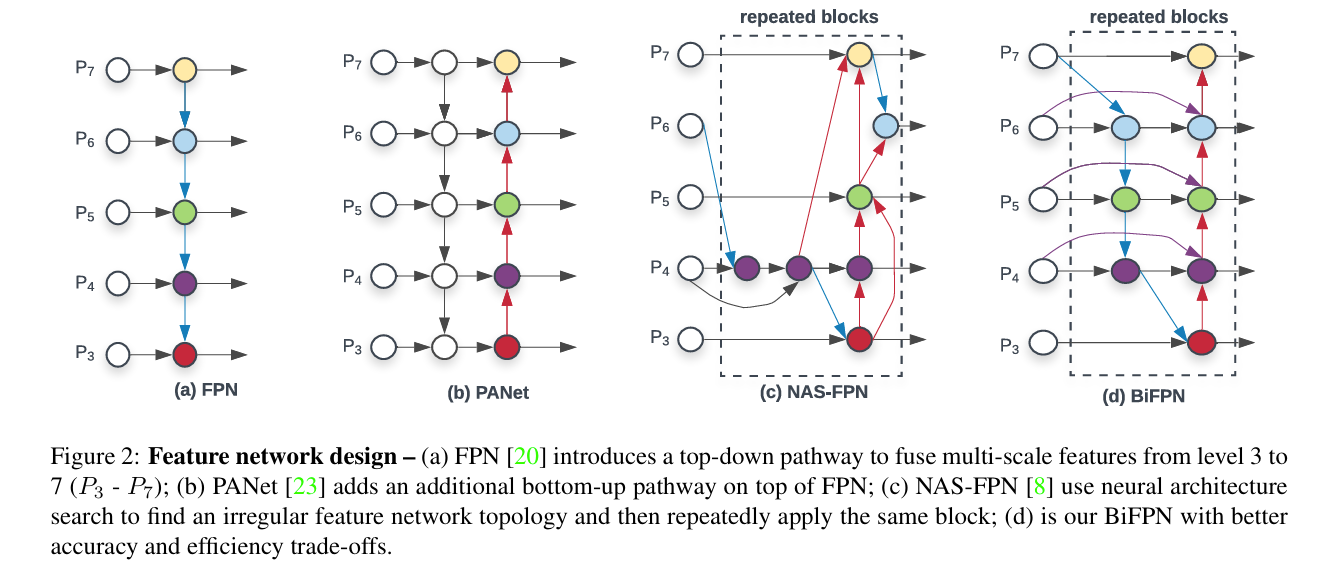
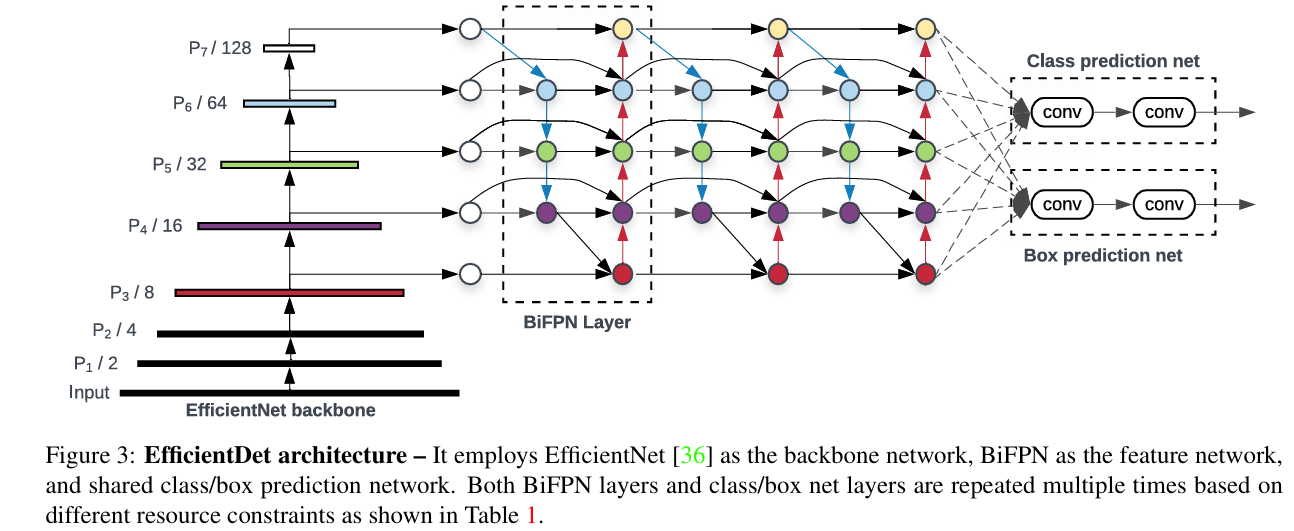
方法:提出 EfficientDet,通过引入 BiFPN(加权双向特征金字塔网络)和复合缩放策略,统一优化网络的分辨率、深度和宽度,从而在多个算力约束下实现最优检测性能。
效果:COCO2017-AP: 52.2%(EfficientDet-D7),比传统方法效率高 4-9 倍,FLOPs 减少 13-42 倍。
缺点:
- 对于非常高分辨率的图像,模型推理时间仍然较高。
- BiFPN 的复杂性使其在小型设备上的应用受到限制。
Swin Transformer[10]-2021
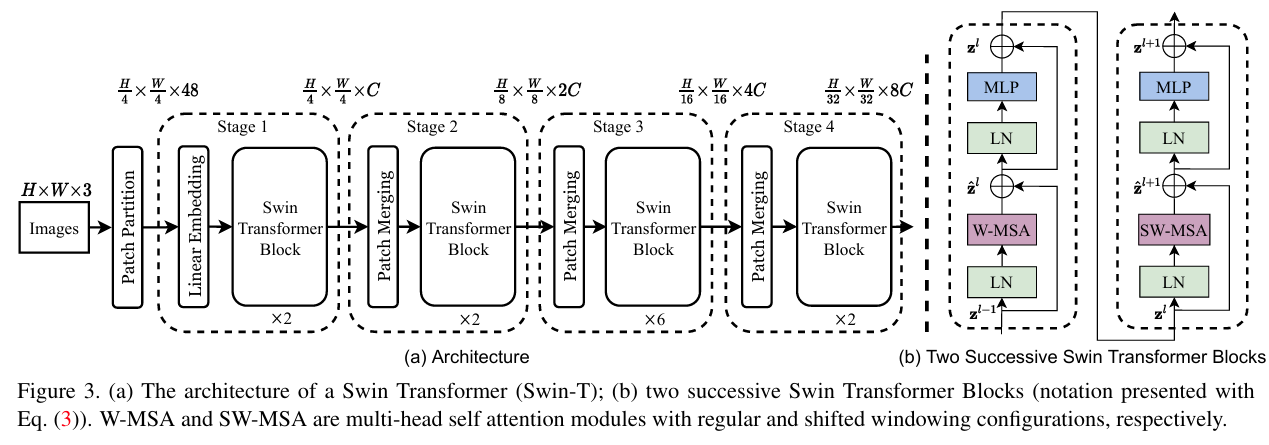
方法:提出 Swin Transformer,将视觉任务中的 Transformer 架构扩展为分层结构,使用滑动窗口机制,局部关注提高效率,分层设计增强全局感受野。
效果:COCO-mAP: 53.5%
缺点:
对硬件的显存要求较高。
训练时间较长,计算复杂度仍高于普通卷积网络。
ViTAE[11]-2021
方法:提出 VITAE,结合卷积网络的归纳偏置与 Transformer 的强建模能力,通过结构设计实现局部特征提取与全局表示的平衡。
效果:COCO-AP: 55.2%,在检测和分割任务中优于传统方法。
缺点:
- 参数量大,硬件需求高。
- 对稀疏数据分布的适应性有限。
DINO[12]-2022
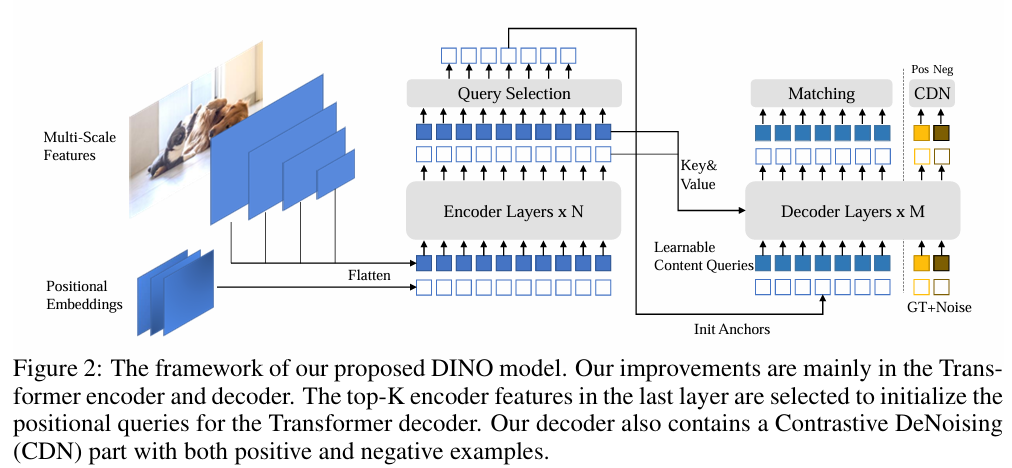
方法:提出 DINO,通过改进 DEtection TRansformer (DETR),引入降噪锚框机制(Denoising Anchor Boxes),加快模型的收敛速度,提高对目标边界框的预测精度。
效果:COCO-AP: 56.0%,显著提升了 DETR 的训练效率。
缺点:
- 对超参数敏感,调整较为困难。
- 对长尾分布的目标检测仍存在一定不足。
BEiT[13,14]-2021/2023
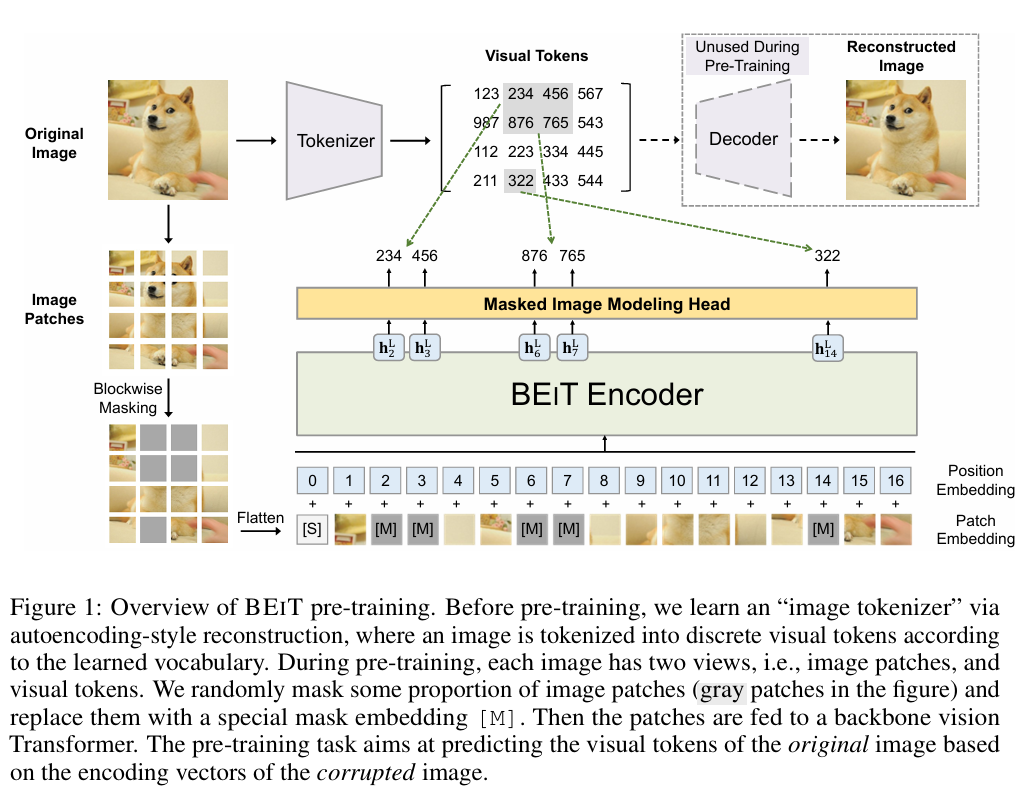
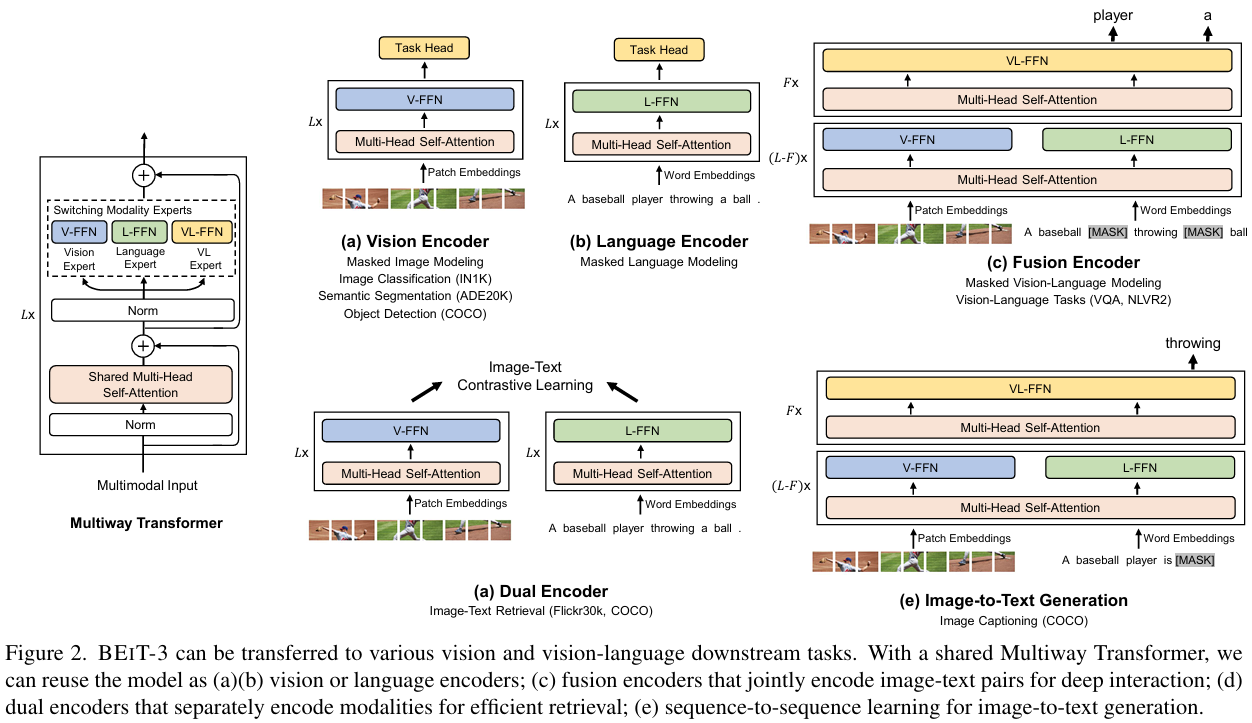
方法:提出 BEiT,将语言模型中的 BERT 预训练思想引入视觉任务,通过 Masked Image Modeling (MIM) 进行自监督预训练,生成通用图像表示。
效果:ImageNet Top-1 Accuracy: 85.2%。
缺点:
- 对于小型数据集,预训练效果不如传统 CNN。
- 模型收敛速度慢。
方法:扩展 BEiT,引入多模态训练框架,通过视觉和文本联合建模,提升图像和语言任务的性能。
效果:COCO Captioning-mAP: 58.4%,在多模态任务上优于同类方法。
缺点:
- 模型复杂度显著增加,训练时间较长。
- 对文本和图像的标注数据需求较大。
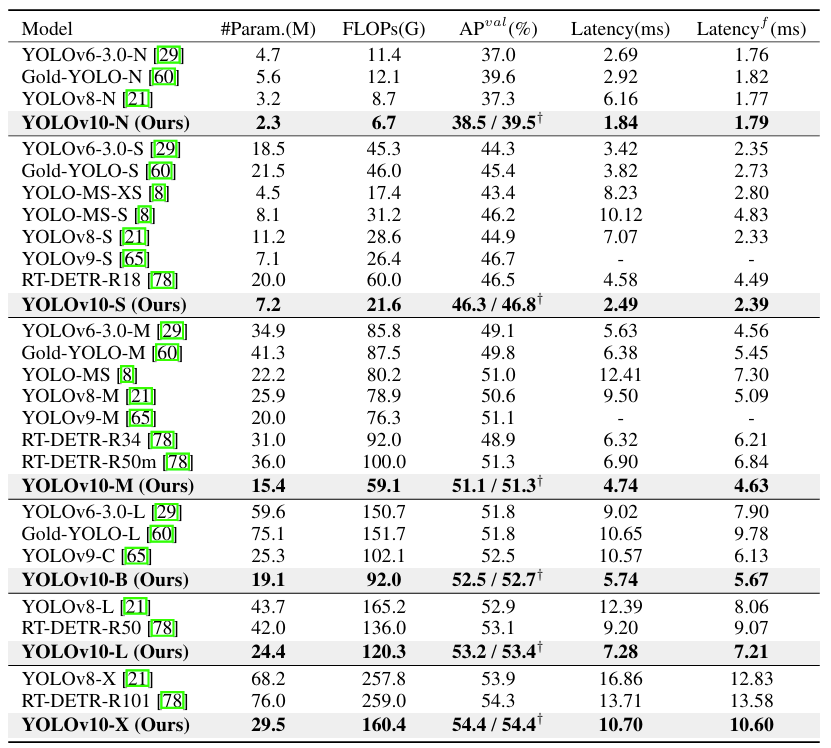
YOLOv10[15]-2024
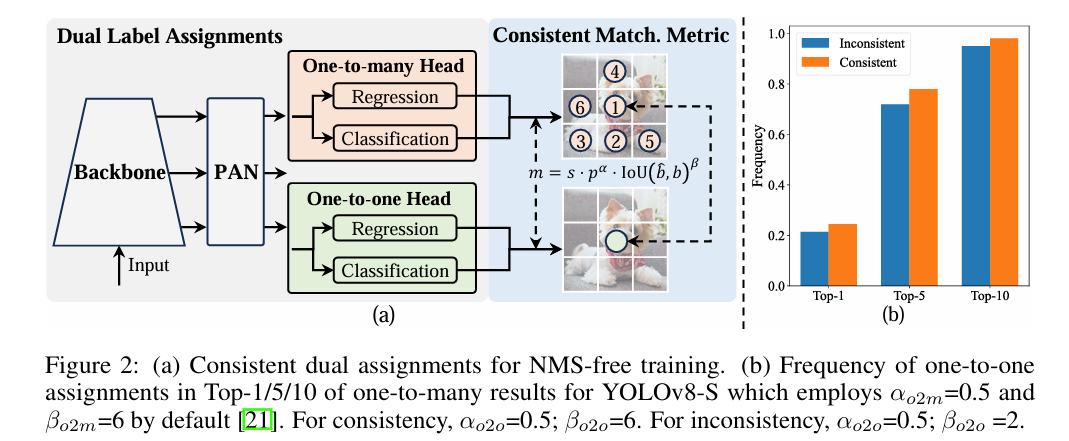
方法:提出 YOLOv10,进一步优化 YOLO 系列,通过引入动态感受野和自适应特征融合模块,提升检测速度与精度。
效果:VOC07-mAP: 75.3%,实时性能提升,推理速度可达 200 fps。
缺点:
- 对小目标和密集目标的检测仍有改进空间。
- 较早的硬件设备可能不支持优化的动态模块。
指标
mAP:综合衡量检测结果
| 相关,正类(positive) | 无关,负类(negative) | |
|---|---|---|
| 被检索到 | true positives(本身是P,预测为P) | false positives(本身是N,预测为P) |
| 未被检索到 | false negatives(本身是P,预测为N) | false negatives(本身是N,预测为N) |
对Recall的理解:分母是TP+FN,FN表示的是我所遗漏的应该被预测为正例的样本,实际上我把它当作负例了。
IoU:交并比

想法—凹凸餐盘的菜品识别
| 复杂的餐盘形状 | 食物混合问题 | 光线及环境因素 | 特殊场景需求 |
|---|---|---|---|
| 餐盘的凹凸结构:凹槽区域、凸起边缘容易遮挡或变形食物轮廓,增加了目标分割的难度。 | 混合食物的难辨性:如拼盘菜,或者盛菜过多,食物之间界限模糊,影响识别效果。 | 光线反射问题:光线在餐盘表面反射可能导致摄像头捕捉到的图像曝光过度或产生光斑,干扰图像质量。 | 液体及半流质食品:如汤类、酱汁等在凹凸餐盘中容易流动,识别时区域划分困难。 |
| 餐盘边界的干扰:传统的图像分割算法容易将餐盘的边缘误判为目标区域,导致结果不准确。 | —- | 拍摄角度的偏差:在不同角度拍摄的餐盘可能出现严重的透视畸变,影响识别模型的稳定性。 | 污渍及残渣干扰:餐盘表面的食物残渣或污渍容易与目标食物混淆。 |
Q:若是目标检测:
- 那么我解决这个问题是使用one-stage/two-stage?
- 对于识别问题的速度要求有多快?
- 如何在时间和准确率上进行权衡?
现在对于two-stage的似乎可能过时了,因为并不适用于实时的物体检测。
现在还没看One-stage的详细步骤,但是我揣测是可以适用YOLO v8/10来进行。
问题:应用问题。应用难点是:凹凸餐盘造成的前后景难以辨析,影响了检测识别的准确率。
这个写得也太简单了、对问题的认识不够深入。
引用文献
[1] Girshick, Ross, et al. “Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation.” 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, https://doi.org/10.1109/cvpr.2014.81.
[2] He, Kaiming, et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” IEEE Transactions on Pattern Analysis and Machine Intelligence, Sept. 2015, pp. 1904–16, https://doi.org/10.1109/tpami.2015.2389824.
[3] Girshick, Ross. “Fast R-CNN.” 2015 IEEE International Conference on Computer Vision (ICCV), 2015, https://doi.org/10.1109/iccv.2015.169.
[4] Ren, Shaoqing, et al. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” IEEE Transactions on Pattern Analysis and Machine Intelligence, June 2017, pp. 1137–49, https://doi.org/10.1109/tpami.2016.2577031.
[5] Lin, Tsung-Yi, et al. “Feature Pyramid Networks for Object Detection.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, https://doi.org/10.1109/cvpr.2017.106.
[6] He, Kaiming, et al. “Mask r-cnn.” Proceedings of the IEEE international conference on computer vision. 2017.
[7] Redmon, Joseph, et al. “You Only Look Once: Unified, Real-Time Object Detection.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, https://doi.org/10.1109/cvpr.2016.91.
[8] Lin, Tsung-Yi, et al. “Focal Loss for Dense Object Detection.” 2017 IEEE International Conference on Computer Vision (ICCV), 2017, https://doi.org/10.1109/iccv.2017.324.
[9] Tan, Mingxing, Ruoming Pang, and Quoc V. Le. “Efficientdet: Scalable and efficient object detection.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[10] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[11] Xu, Yufei, et al. “Vitae: Vision transformer advanced by exploring intrinsic inductive bias.” Advances in neural information processing systems 34 (2021): 28522-28535.
[12] Zhang, Hao, et al. “Dino: Detr with improved denoising anchor boxes for end-to-end object detection.” arXiv preprint arXiv:2203.03605 (2022).
[13] Bao, Hangbo, et al. “Beit: Bert pre-training of image transformers.” arXiv preprint arXiv:2106.08254 (2021).
[14] Wang, Wenhui, et al. “Image as a foreign language: Beit pretraining for vision and vision-language tasks.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[15] Wang, Ao, et al. “Yolov10: Real-time end-to-end object detection.” arXiv preprint arXiv:2405.14458 (2024).
软件工程大作业
感觉二因为缺少企业的数据,但是能不能去爬一点数据?
感觉可以结合LLM的方向:
- 智能职位匹配(但是集合AI感觉就行,没必要做LLM)
- 辅助求职:准备一些题库,去除原先的评分标准,现在让求职者回答一些问题,然后模型打分、并给出一些求职建议或经验。
设置有关的prompt:比如,假设你是一个求职专家,你需要给予不同专业方向的面试者一些题(?)
对于企业方,可以查看所有应聘的人,但是旁边会标注上此项得分,帮助HR进行简历初筛。
Q:什么问题?
首先,求职者分很多的类别,我们可以先设计一些疑问。然后对方求职者回答采用文字陈述的方式输出。
再将这些文字陈述+简历信息投入LLM,获得对此人的初步评价以及得分。