模式识别-Ch4-非参数估计
Ch4 非参数估计

[TOC]
| 参数估计方法 | 非参数估计方法 |
|---|---|
| MLE,贝叶斯估计 | Parzen窗方法、KNN |
| 待估计的概率密度函数的形式已知,利用样本来估 计函数中的某些参数。 | 非参数估计方法不需要对概率密度函数的形式作任何假设,而是直接用样本估计出整个函数。 |
非参数密度估计

难点:选取小窗大小
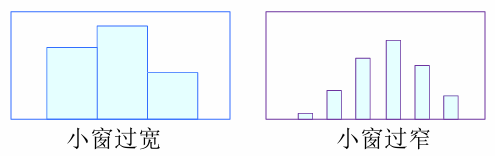
- 小窗过宽:由于假定小舱内p(x)为常数,则导致过于平均的估计结果。
- 小窗过窄:落入小舱的样本将会 很少,或者没有样本落入,从而导致对p(x)的估计不连续。
基本原理
- 给定样本集
,假定这些样本是从一个服从密度函数 的总体分布中独立抽取出来的,目标是给出关于 的估计。 - 考虑
点处的一个小区域 ,一个样本落入该区域概率是:
- 若
个随机样本中有 个样本落入小区域 , 是对概率 的一个很好的估计(无偏估计、最大似然估计)。 - 落入
的样本数服从参数为 的二项分布。 - 当样本数
越来越大时,该估计相当精确。
- 落入
- 另一方面,假设
连续,且小区域 的体积 足够小,可以假定在该小区域内 是常数,则
- 于是有
点处的概率密度估计:
收敛性
对每个样本数
为了使
这几个条件说明:随着样本数目的增加,小舱的体积应该尽可能小,同时又必须保证小舱内有充分多的样本,但每个小舱内的样本又必须是总数的很小一部分。
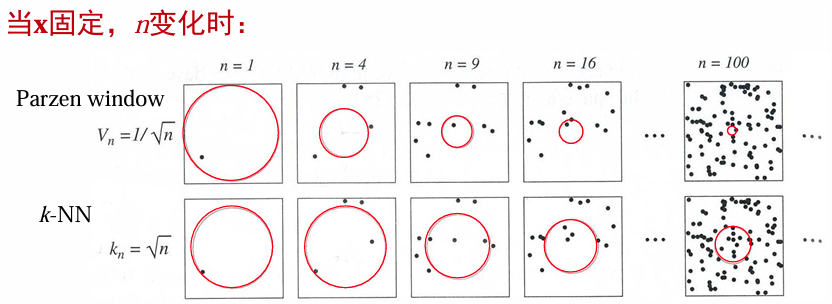
有两种常见的方法来获得满足这些条件的区域序列:
- 指定体积
作为 的函数,保证 收敛到 。这是Parzen - window方法。(对给定的 ,小舱体积在全局处处保持不变,小舱内的样本数可变) - 指定
作为 的函数。这里体积 是增长的,直到它包围 的 个邻居。这是KNN估计方法。(对给定的 ,小舱内的样本数不变,小舱大小可变)
这两种方法都收敛,尽管很难对它们的有限样本行为做出有意义的陈述。
| - | ||
|---|---|---|
| Parzen窗 | 固定局部区域体积 |
|
| KNN | 固定局部样本数 |
Parzen窗估计
方法介绍
假设
现在的任务:要统计落入以
个人感觉会比较像:图像处理-傅里叶变换-冲激函数/单位脉冲。
对于点
上式与
Q: 为什么使用
? A:
表示从目标点 指向样本点 的 相对位移,它是从中心 出发的方向,更符合“以 为中心”的逻辑
若共有
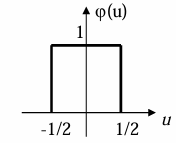
定义如下函数:
引入如下积分变换函数:
窗函数的选择
确与单位脉冲 非常相似,但它是对 的“平滑近似”:
是 有限支持且连续的窗函数,适用于实际计算。 是理想化的数学工具,用于理论分析。 随着窗口宽度
逐渐缩小, 会逐渐逼近 。在概率密度估计中,我们用 来平滑地估计分布,而不是使用离散的 Dirac Delta 函数。
一般地,要保证
反映了样本 对在 处概率密度估计贡献的大小,通常与 到 的距离有关。 - 概率密度估计
就是把 中所有观测样本在 点的贡献进行平均。
除了以上窗函数,还可定义其它函数:
| 其他窗函数 | 公式 |
|---|---|
| 方窗(非单位长度) | |
| 正态窗 | |
| 球窗 | |
| 其中 |
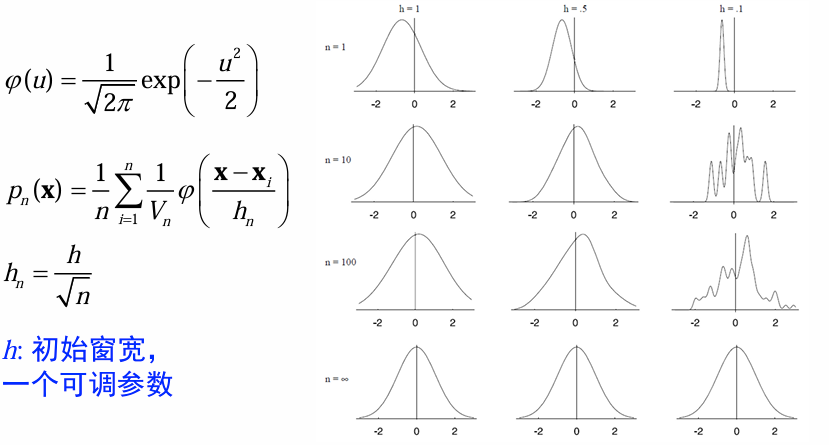
窗宽的影响
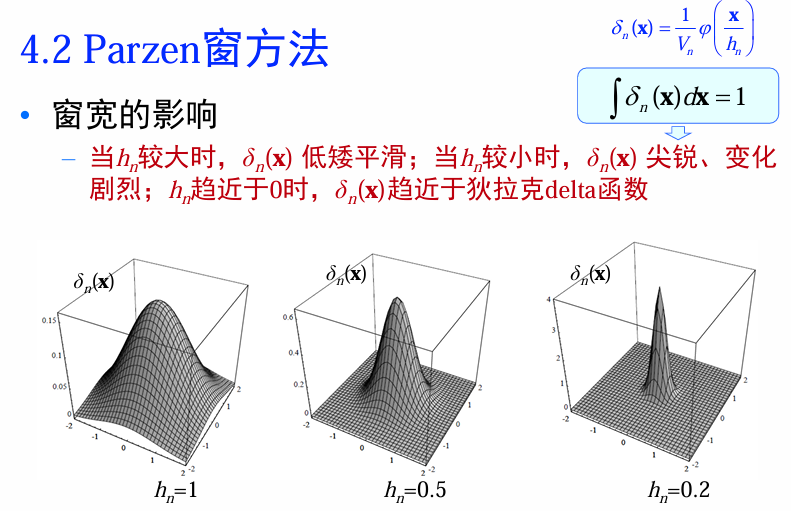
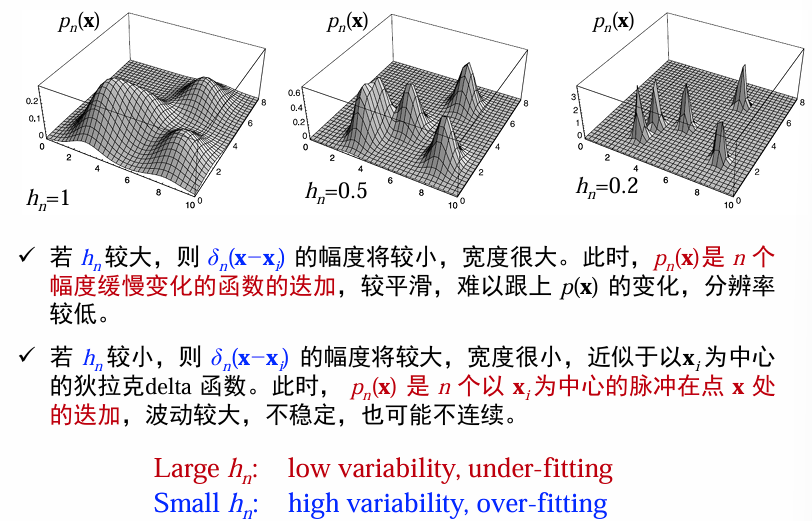
例子:用高斯窗估计高斯分布
1-D
2-D
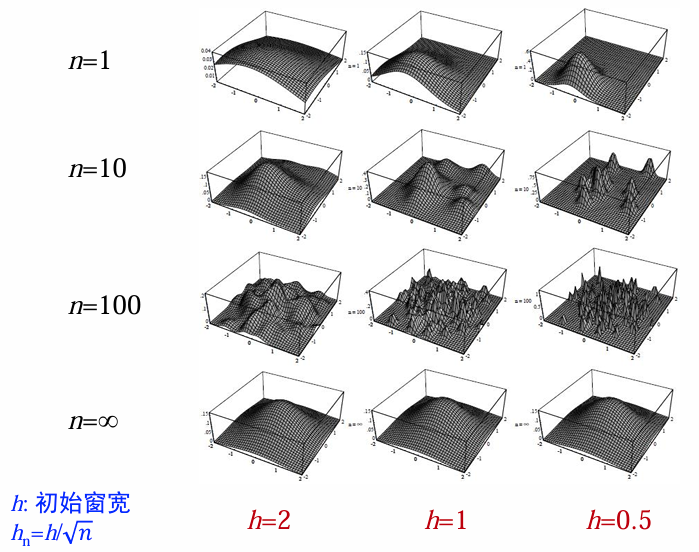
可见:使用小窗宽得到的分类界面比大窗宽的分类界面更复杂。h越大,得到的分布越平滑、h越小得到的分布越尖锐。
算法特点:
- 适用范围广,无论概率函数是规则的或者是不规则的、单峰的还是多峰的;
- 当样本数趋于无穷时,Parzen窗估计收敛于真实p(x);
- 但该方法要求样本的数量要大;
- 选择合适的窗口函数将有利于提高估计的精度和减少样本的数量。
- 与直方图仅仅在每个固定小窗内估计平均密度不同, Parzen窗用滑动的小窗来估计每个点上的概率密度。
K近邻估计
- Parzen窗估计中,小窗的体积
被视为样本个数 的函数,比如 。
- 当
选择得太小,导致大部分区域是空的,会使 不稳定。 - 当
选择得太大,则 会变得过于平坦,从而失去一些重要的空间变化。 近邻估计方法是克服这一问题的一种可能方法。
基本方法
近邻估计是一种采用大小可变舱的密度估计方法。其基本做法是:根据总样本数确定一个参数 ,要求每个小舱内拥有的样本数目是 。 在估计
点处的概率密度 时,我们调整包含 的小舱的体积,直到小舱内恰好落入 个样本,此时有: 其中
不固定,与 的位置相关。
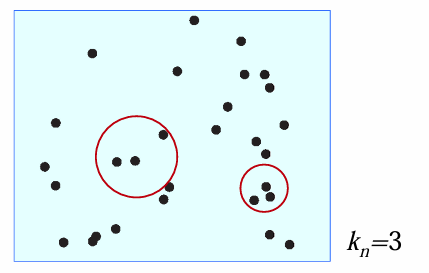
在密度较高的区域,窗口
会比较小,因为周围样本多,窗口不需要太大就可以包含 个样本。 在密度较低的区域,窗口
会比较大,因为样本较稀疏,需要更大的范围来找到 个样本。
收敛性分析:
:当样本数量 时, 应该足够大,这样才能捕捉到整体概率分布。 : 的增长速度不能太快,否则窗口太大,局部密度信息会丢失。
(与Parzen窗方法不同,
在
对于一维来讲,考虑最近邻情形,即
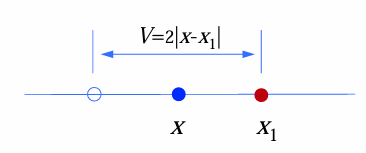
此时,
考虑
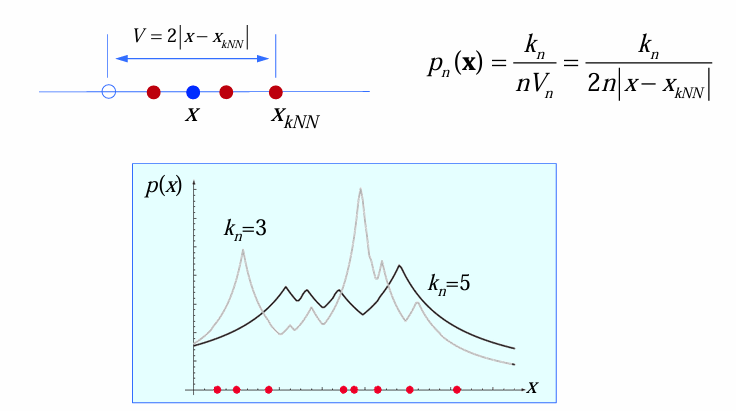
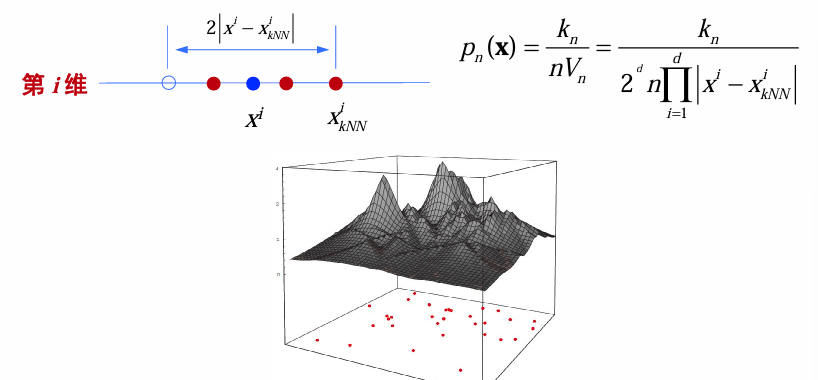
对于多维情形,可以用球来度量
K近邻分类器
最近邻分类器
| 1-NN | 说明 |
|---|---|
| 方法 | 对测试样本 |
| 直观理解 | 给定训练样本集 |
| 决策规则 |
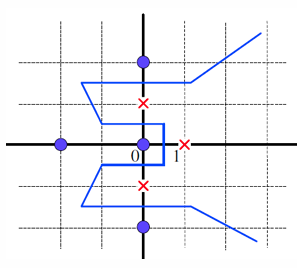
例子
现有7个二维向量:
最近邻规则的错误率分析
研究表明,在训练样本足够多时,最近邻决策可以取得很好的效果。
我们对最近邻规则的行为分析将针对获得无限样本条件平均错误概率
,其中平均是相对于训练样本而言的。一般来说,无条件平均错误概率将通过对所有 平均 得到: 我们应该记得贝叶斯决策规则通过对每个
最小化 来最小化 。 再次回顾如果我们令$P^(e\vert x)
P(e\vert x) P^ P(e)$的最小可能值,那么贝叶斯错误率:
评估最近邻规则的平均错误概率: 特别地,如果
那么,我们有:
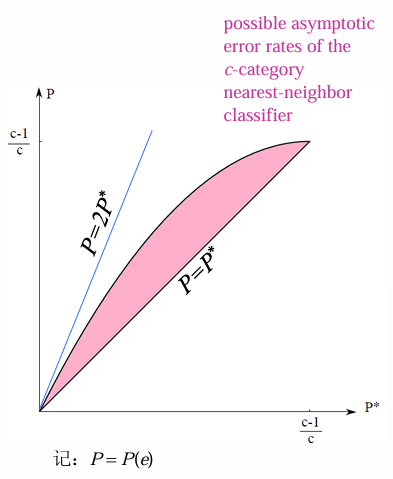
这个结论告诉我们:最近邻法的渐近错误率最坏不会超过两倍的贝叶斯错误率,而最好则有可能接近或达到贝叶斯错误率。
推导过程
- 最近邻规则的错误率:
当
渐近错误率
1 - NN规则的错误界
错误率
错误界
K近邻分类器
在很多情况下,将决策建立在最近邻样本上有一定的风险。(数据分布复杂,存在噪声)
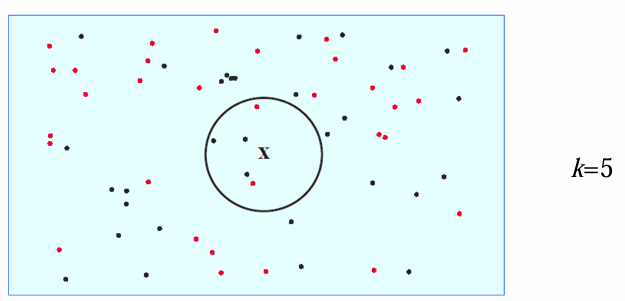
- 一种自然的改进就是引入投票机制:选择前
个距离测试样本最近的训练样本,用它们的类别投票来决定新样本的类别。 - 给定训练集
,对测试样本 ,设 是 在 中的 个最近邻样本。设 类的判别函数 , 是 中 类样本的个数。 - 决策规则:
K近邻分类器与K近邻估计的关系
假设训练集
测试样本
则类条件概率密度
样本
这就是
K近邻的快速计算
- 搜索
近邻的计算复杂度: —d:样本dim, n:训练样本数, K:测试样本数量 - 快速搜索策略:
- 部分距离(partial distance)
- 搜索树
- 剪辑/压缩算法(pruning, condensing)
部分距离
如果部分平方距离已经超过当前最近邻的全局最小距离,可以提前停止后续维度的计算,从而节省计算时间。如果部分平方距离大于
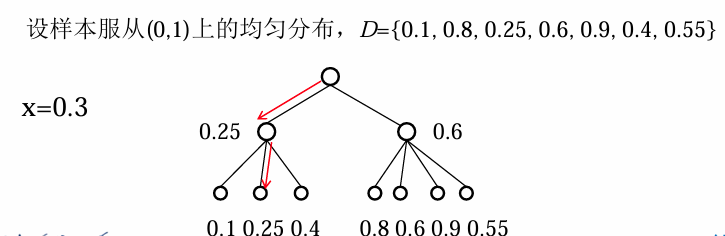
搜索树
使用搜索树(例如 kd-tree)对训练样本进行组织,可以高效查找最近邻。基本思想是:
- 将样本按照特定规则划分成树状结构。
- 测试样本从根节点开始递归搜索,只访问相关子树,从而快速找到最近邻。
在实际应用中,kd-tree 是常用的搜索树结构,尤其适用于低维空间。
压缩近邻法
考虑近邻法的分类原理,远离分类边界的样本对于分类决策没有贡献。只要能够找出各类样本中最有利于与其它类相互区分的代表性样本,则可将很多训练样本去掉,简化决策过程中的计算。
压缩近邻法通过减少训练样本的数量来加速分类:
删除冗余样本:对于类别边界之外的样本(远离决策边界的样本),它们对分类结果的贡献很小,可以删除。
保留代表样本:通过算法挑选最能区分不同类别的样本点,形成代表性集合
。 算法过程:
将样本集分为两个活动的子集:
和 ,前者称为储存集(Storage),后者称为备选集(GrabBag)。首先,在算法开始时, 中只有一个样本,其余样本均在 中。 遍历
中的每一个样本,如果采用 中的样本能够对其正确分类,则该样本仍然保留在 中,否则移动到 中,从而扩大代表集合。依次重复进行上述操作,直到没有样本需要搬移为止。 最后,用
中的样本作为代表样本,对新来的样本进行分类。
距离度量
距离度量是模式分类的基础: 设有
| 性质 | 对应公式 |
|---|---|
| 非负性 | |
| 自相似性 | |
| 对称性 | |
| 三角不等式 |
距离可以描述点对间的相异程度,距离越大,两个点越不相似;距离越小,两个点越相似。
设
时, (城区距离/曼哈顿距离) 时, (欧氏距离) 时, (切比雪夫距离)
欧氏距离
Mahalanobis(马氏)距离
设
(其中,
为单位矩阵时,退化为欧氏距离。 为对角矩阵时,退化为特征加权欧氏距离。 - 由
, ,可看作是在新特征空间中的欧氏距离。
性质
距离对坐标变换敏感:
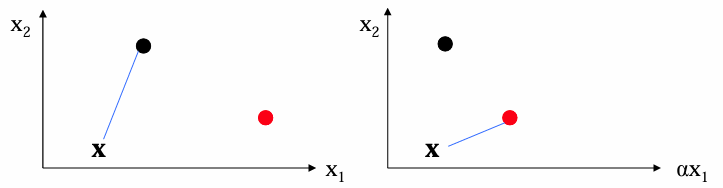
向量间距离的扩展:
- 分布间距离:KL散度、交叉熵
- 集合间距离:见chapter 9(聚类)
距离通常是无监督概念
- 如何利用先验知识、监督信息?
Tangent Distance(切向距离)
切向距离用于处理因 变换(如平移、旋转、缩放等)导致的样本相似性问题。
Q: 变换对距离的影响?
A: 例如:
- 图像的平移、旋转或缩放可能导致类内距离(同一类别样本的距离)变大,而超过类间距离(不同类别样本的距离)。
- 直接使用欧氏距离可能会导致错误分类。
定义
| 定义 | 说明 |
|---|---|
| 变换的参数化表示 | 给定一个样本 |
| 变换下的样本空间 | 样本 |
| 样本 |
定义 |
线性近似流形
Q: 流形?
A: 流形(Manifold) 是数学中用来描述复杂形状的一种概念,可以看作是局部上类似于欧几里得空间的几何对象。它广泛应用于几何、物理学和机器学习中,尤其是在高维空间中建模复杂数据分布。
简单来说:局部像平坦的欧几里得空间,但全局可能是弯曲的。
例子:地球=二维流形,局部是二维平面、全局是球体。
由于流形
对变换
的线性近似: 在 点的泰勒展开,其中 称为切向量(tangent vector) 用线性子空间近似
: 样本
到 的切向距离:( 到子空间的最小距离)
多参数变换
假设变换
此时,变换
对应的线性近似为:
其中
样本
距离度量学习
使用不同的距离度量,会得到不同的分类结果。
- 为了反映特征之间的关联关系
- 为了充分利用先验知识
- 反映特定问题的特定需求
在某些机器学习任务中(如聚类、分类等),我们需要定义一个适当的距离度量,用于衡量数据点之间的相似性或不相似性。
然而,标准的欧氏距离可能不足以捕捉数据的复杂关系,尤其是当有侧信息 (side information) 时,这些侧信息可以指导距离度量的优化。
假设我们有一组数据点
- Must-link 集合 S:
表示 和 应该是相似的(即,它们应该在同一类中)。 - Cannot-link 集合 D:
表示 和 应该是不相似的(即,它们应该属于不同的类)。
这些信息告诉我们哪些点需要在距离上更靠近,哪些点需要更远。
我们希望学习一个距离度量,使得:
- 对于 Must-link 对,点之间的距离尽可能小。
- 对于 Cannot-link 对,点之间的距离尽可能大。
为了实现这一目标,可以使用一个参数化的马氏距离 (Mahalanobis Distance):
其中
优化目标:
希望 Cannot-link 集合中的点的距离尽可能大。
确保 Must-link 集合中的点的距离尽可能小。
保证
是一个半正定矩阵,使得距离 是有效的。