多元统计分析-Ch7-因子分析
Ch7 因子分析
一只码字机踩过…
时间远远不够です、どうしますか…
[TOC]
7.1 引入
因子分析法:
在多变量分析中,某些变量间往往存在相关性。
Q1: 是什么原因使变量间有关联呢?
Q2: 是否存在不能直接观测到的,但影响可观测变量变化的公共因子?
因子分析法就是寻找这些公共因子的模型分析方法。 通过构建若干意义较为明确的公共因子,以它们为框架分解原变量,以此考察原变量间的联系与区别。
因子分析的目的和应用:
- 目的 :用有限个不可观测的隐变量来解释原始变量之间的相关关系,是一种把多个变量化为少数几个综合变量的多变量分析方法。
- 主要应用 :
- 减少分析变量个数。
- 通过对变量间相关关系的探测,将原始变量进行分类,即可以将相关性高的变量分为一组,并用共性因子代替该组变量。
7.1.1 例1: Spearman因素分析
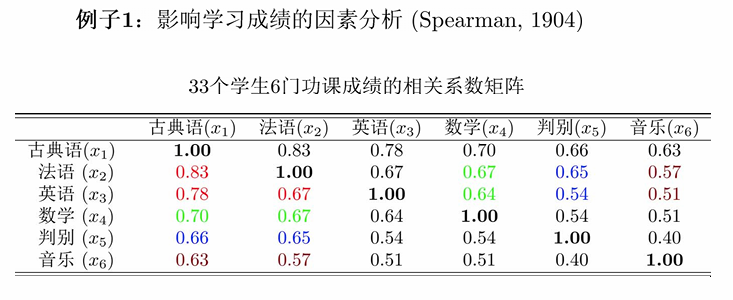

Spearman推测的解释:
因为相关系数矩阵是对称的,所以行=列。那么此处以列说明:每列基本上的相关系数值都差不多,所以任一两个值的比也都差不多。
的结果与 无关,说明所有变量的相关性可以通过共同因子解释。 这个推测为 因子分析 提供了理论依据,即变量间的相关性具有内在结构。

其中,
记
或:
A. Spearman模型的解释
- 每一门功课的成绩都由两部分组成:
. - 前一部分中的
是对所有课程的成绩都有贡献的随机变量; - 后一部分中
是仅对第 门课程的成绩有贡献的随机变量。 - 因此,称
为公共因子,称 为特殊因子。
- 前一部分中的
- 因子载荷:
称为第 门课程成绩的因子载荷,理解为公共因子 对第 门课程成绩的作用程度。 - 公共因子含义:
可以理解为学生的阅读能力。 - 由于不同人的阅读能力有差异,故它是一个随机变量。
- 阅读能力对不同课程的贡献率
不一样。
结论:Spearman模型是最早的仅有一个公共因子的因子模型。此模型就是在发现学生6门功课成绩的相关性后,挖掘出影响学习成绩的公共因子,并解释其对学习成绩影响的因子分析模型。
7.1.2 例2: 顾客感知因子模型

潜变量定义:
| 潜变量 | |||||
|---|---|---|---|---|---|
| 说明 | 顾客对质量的感知 | 顾客对价值的感知 | 顾客满意度 | 顾客抱怨 | 顾客忠诚度 |
观测变量与潜变量的关系:
| 观察变量 | 意义 | 与潜变量关系 | 潜变量意义 |
|---|---|---|---|
| 分别表示顾客对质量、质量可靠性和质量满足需求程度的评价 | 与 |
对质量感知 | |
| 分别表示给定价格后顾客对质量的评价和给定质量后顾客对价格的评价 | 与 |
对价值的感知 | |
| 分别表示顾客对企业的总评价、感知的质量与期望的比较,以及感知的质量与理想中的质量的差距 | 与 |
顾客满意度 | |
| 表示顾客正式或非正式的投诉行为对质量的评价和给定质量后顾客对价格的评价 | 与 |
顾客抱怨 | |
| 分别表示顾客重复购买的可能性,顾客可承受的涨价幅度或促销(降价)对顾客购买的影响 | 与 |
顾客忠诚度 |
7.1.3 因子分析模型
记观察变量
假设:
相互独立,且 。 相互独立,且 。 与 相互独立。 。
记因子载荷矩阵
记
称
公共因子对
公共因子
对任意
因此,因子载荷矩阵
是 与 的相关系数。 是 对公共因子的依赖程度。 是公共因子 对 的各个分量的影响总和。
7.2 正交因子模型
正交因子模型:令
| 因子载荷矩阵 | 公共因子 | 特殊因子 |
注意:因子载荷矩阵并不唯一,因为对任意
阶正交矩阵 ,有:
7.2.1 因子载荷矩阵的表示
Q: 在给定
的相关阵 和对角阵 的条件下,如何求解 ?
约相关阵:
易知,
记$R^
目标:求解
要求:使得
利用特征根和特征向量求解:
记
其中
7.3 因子载荷矩阵的估计
7.3.1 R主成分估计法
认为比较粗糙,一般对$R^=R-D$进行主成分分析,此处*直接对R进行主成分分析。
记
其中,
先取
- 如果接近对角阵,表明剩下的都是特殊因子的影响,只有一个公共因子。
- 否则一直进行下去。
实际操作中,给定一个阈值
则取 :
7.3.2 MSE-极大似然估计法
假设
其中,
对
对其求偏微分、极大似然估计满足:
求解
因此,第一项关于 AA 的偏导数为:
矩阵的迹的偏导性质为:
将两项的偏导数相加,得到:
由于
是非奇异矩阵,且 ,所以要求: 而对
求解,结果也是
根据我们计算偏导的结果,能够知道极大似然估计满足下面的方程组::
A. 其他表示
Q: 进行变换有何意义?
A: GPT大爷如是说到——
- 解耦和标准化:
- 通过引入
和 ,将原始因子分析模型中的协方差分解标准化,减少了特殊方差 D 对求解的影响。 - 变换后的方程更简洁,特别是在数值迭代计算中,便于求解。
- 结构性分解:
- 方程
和标准化方程 提供了一个明确的框架,展示了样本协方差矩阵与因子载荷之间的关系。 - 数值求解的基础:
- 在实际应用中,这些变换是迭代估计算法(如极大似然估计和 EM 算法)的基础。
- 归一化后的方程可以用于更新 A 和 D,直到收敛。
由:
因为
上述的解可以被写成:
上面的方程还可以被写成:
B.因子载荷矩阵的唯一解
注意到:因子负荷矩阵
这是因为
个变量(自由度)。
因此,为使
如果加上约束条件:
表明下列例子成立:
表明
由于:
而
因此
在给定
则方程
C.MSE迭代算法
给出
的一个初始估计: 可由主成分法等确定 的一个粗估计,或简单地由各分量的方差估计作为 初始估计。记 。 计算特征根和特征向量并估计因子载荷矩阵: 计算
的前 个特征根 以及它们所对应的正则正交特征向量 。记: 是因子载荷矩阵的估计,这里要求 ,否则减小 ,或停止。 给出
的迭代估计 - 由方程(2)给出 的迭代估计: 这里要求
,否则停止。 迭代循环 - 返回(1),直至迭代停止。
也可以使用EM算法,视作隐变量进行计算。

7.4 因子旋转
由于因子载荷矩阵不唯一,因此可以寻找一个正交矩阵
7.4.1 方差最大的正交旋转(Varimax旋转)
先考虑两个因子的正交旋转,设因子载荷矩阵和正交矩阵为:
令
目标:旋转后,因子的“贡献”越分散越好。
结果:
可分为两部分,一部分主要与第一因子有关,另一部分主要与第二因子有关。
定义
其中
记:(
此法具有显式解:
进而得正交矩阵:
取得的方差
在旋转的同时,都会更接近收敛(比原来好),因此到达停止条件的时候,收敛。
7.4.2 更多公共因子的情形
当公共因子个数
自然而然地联想到矩阵分解方法:Givens reduction(√)


这样做
由Varimax的性质知,
而因子载荷矩阵的元素绝对值均不大于1,因此上述单调序列有上界,故收敛。
实际中,若认为因子载荷矩阵的相对方差差总和已经变化很小时,则停止旋转。
7.5 正交因子模型协方差结构的检验
在因子分析中,正交因子模型假设观测变量的协方差矩阵可以被分解为因子载荷矩阵和特殊方差矩阵的组合形式:
模型假设的是一个特定的协方差结构,但这个假设不一定总是成立,因此需要检验协方差的结构是否符合模型的理论假设。
检验协方差结构的目的和意义:
- 理论协方差矩阵
是因子模型根据参数 A 和 D 推导得到的。 - 实际协方差矩阵 S 是根据样本数据计算出来的。
目标是检验实际协方差矩阵 S 是否与理论协方差矩阵
足够接近。
- 如果
,说明因子模型合理,协方差的结构假设成立; - 如果
与 偏差较大,说明因子模型可能不适合当前数据。
7.5.1 正交因子模型极大似然估计相关推导
设
有关正交因子模型
其中
记
由于极大似然估计满足似然方程,故有:
对任意方阵
由
根据
因此有:
正交因子模型检验的似然比
计算参数空间的自由度:
- 由于
为对角阵,即 有 个约束。因此 - 自由度
为:
由Wilks定理知:
检验方案: 当
正交因子模型的识别性问题: 当自由度
时,正交因子模型存在可识别性问题。
- 当
时,分解 不唯一;( 偏大) - 当
时,分解 或不存在,或存在唯一。
7.6斜交旋转
设
其中,
称模型
Actually,存在满秩阵
易知:
则
由于
7.7 因子得分
将因子表示成变量的线性组合(反代)
- 因子得分函数:
- 因子得分矩阵:
由因子得分函数知:
7.7.1 因子得分的计算—计算因子得分矩阵
假定变量
假定因子载荷矩阵
对任意
因此对
7.7.2 估计(因子载荷矩阵)—回归法
因子载荷矩阵估计:
因子得分矩阵
则因子得分估计为
因子得分:
- 判断公共因子的重要度:得分高,更重要。
- 样本聚类:可以使用因子得分对样本进行聚类(但不是唯一)。
7.8 PCA与因子分析
本质:寻找一个低秩矩阵,使其无限接近于原矩阵。
因子需要考虑对角阵,主成分考虑范数。

因子LS(Least Square)估计(不需要正态):
迭代训练:
,得到 前m个主成分。
不一定是正态的时候使用,但是是正态的时候还是MSE更优。==证明?==
因子也是HMM。
7.8.1 EM-模式识别作业参考
对混合高斯模型参数估计问题,在EM优化的框架下,请给出其中的
解:
E-step: 固定当前参数,对每个样本求
M-step: 固定