多元统计分析-Ch6-主成分分析
Ch6 主成分分析
[TOC]
目的:根据二八定律(雾),大量有效的信息都在很少的指标中。所以PCA在尽量减少损失信息的前提下,将多个指标降维,综合成几个综合指标。
总的来说,PCA就是数据降维。但需要注意的是,得到的降维后的变量无实际意义(基本上就是原各个变量都混合一点的“大杂烩”)。
思路:选取变量的线性组合,使其
[TOC]
6.0 引入
6.0.1 例子
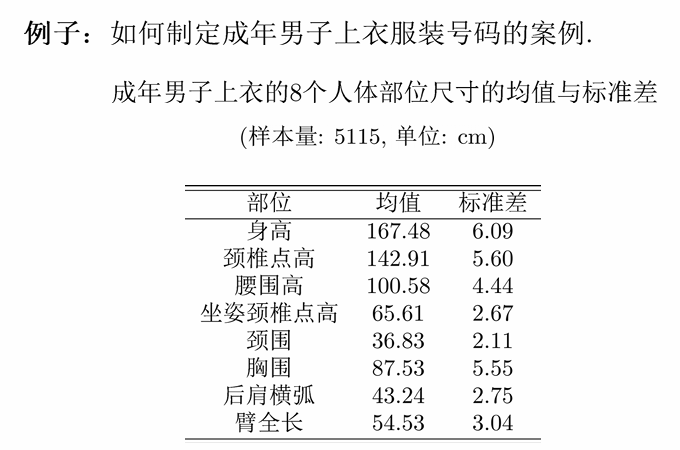
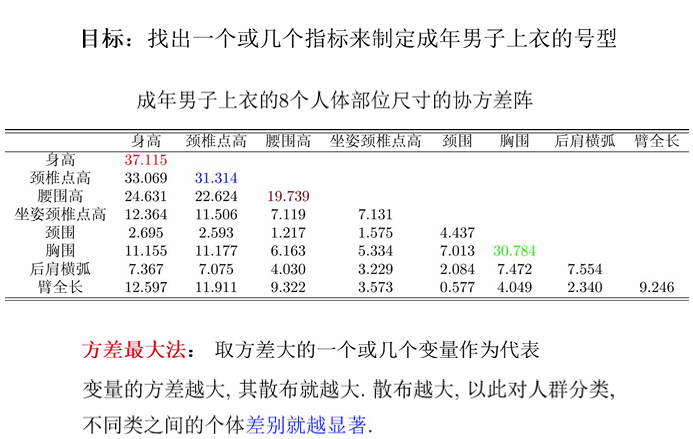
方差
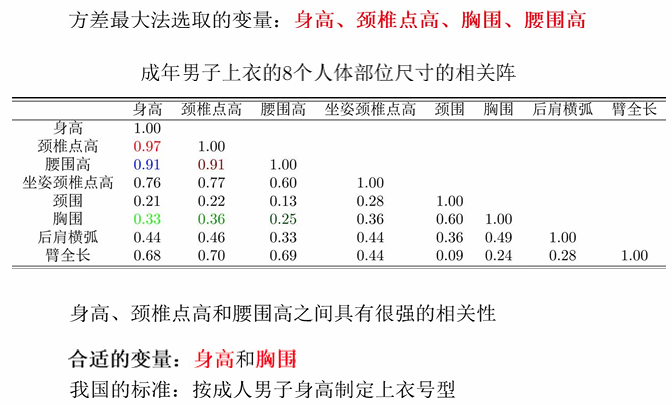
计算相关系数:
最终选取的变量是:身高和胸围。
但仍存在问题:身高和胸围仍然具有相关性,应该对其进行进一步地压缩,以选出更具有代表性的指标。
Q:是否有更具代表性一个or少数指标
代表性标准:方差最大。
6.0.2 主成分分析
记
因为
所以对
令
是正则化系数下方差最大的 的线性组合。 的散布程度最接近 , 是代表 的首选。
A.总体协方差矩阵的特征根与特征向量
首先,我们先回顾一下URV分解、SVD分解、Moore-Penrose伪逆:




令
则第一主成份:
- 方向:总体协差阵的最大特征根所对应的正则特征向量。
- 方差:总体协差阵的最大特征根。
B.随机向量的离散程度
设
第一主成份的作用 :
将
第一主成份离散程度信息的贡献率:
Q:第一主成份代表性是否足够?或第一主成份贡献率是否足够?
A: 寻找第二主成份
, 第二主成份应该与第一主成份正交,从而不含有第一主成份的信息。优化问题如下: 不难知道,
, 。 即,第二主成份:
- 方向:总体协差阵的第二大特征根所对应的正则特征向量;
- 方差:总体协差阵的第二大特征根。
第一主成份与第二主成份的正交性:
因此,正态总体下,第一主成份与第二主成份相互独立。
第二主成份离散程度信息的贡献率:
第一、第二主成份的累计贡献率:
6.0.3 回到例子
因为
是满秩的,那么 是一个RPN阵,这个时候对它进行SVD分解,得到的U=V都是 值域空间的标准正交基。
那么写一个简单的python程序,对
进行SVD分解结果如下。 特征值&奇异值
序号 特征值 奇异值 1 10115.7573 100.5771 2 809.2391 28.4471 3 33.0498 5.7489 4 19.8222 4.4522 5 10.2260 3.1978 6 6.6843 2.5854 7 1.9138 1.3834 8 0.8612 0.9280 左奇异向量
元素 -0.5920 0.1849 -0.1308 0.1612 -0.0062 -0.0136 -0.5614 0.5067 -0.5469 0.1362 -0.0860 0.0608 -0.0676 -0.0599 -0.0709 -0.8112 -0.4052 0.2028 0.2958 0.0702 0.5535 0.1070 0.5948 0.1752 -0.2062 -0.0083 -0.4074 0.2113 -0.6080 -0.1179 0.5662 0.2065 -0.0638 -0.2320 -0.1151 0.1003 -0.0726 0.9549 -0.0116 -0.0397 -0.2680 -0.9003 0.2347 0.1167 0.0327 -0.2170 -0.0055 0.0272 -0.1416 -0.1867 -0.6008 -0.7004 0.2935 -0.0286 0.0667 0.0472 -0.2183 0.0831 0.5411 -0.6376 -0.4763 0.1055 0.0282 0.0854 右奇异向量
( )
元素 -0.5920 -0.5469 -0.4052 -0.2062 -0.0638 -0.2680 -0.1416 -0.2183 0.1849 0.1362 0.2028 -0.0083 -0.2320 -0.9003 -0.1867 0.0831 -0.1308 -0.0860 0.2958 -0.4074 -0.1151 0.2347 -0.6008 0.5411 0.1612 0.0608 0.0702 0.2113 0.1003 0.1167 -0.7004 -0.6376 -0.0062 -0.0676 0.5535 -0.6080 -0.0726 0.0327 0.2935 -0.4763 -0.0136 -0.0599 0.1070 -0.1179 0.9549 -0.2170 -0.0286 0.1055 -0.5614 -0.0709 0.5948 0.5662 -0.0116 -0.0055 0.0667 0.0282 0.5067 -0.8112 0.1752 0.2065 -0.0397 0.0272 0.0472 0.0854

通过成人男子8个身体部位尺寸的协方差阵知:
第一主成份
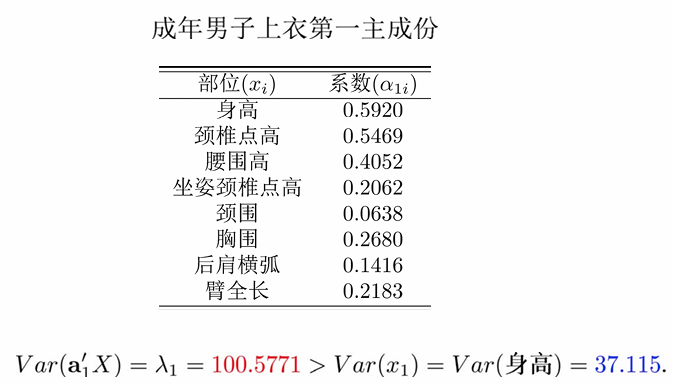
根据定理13.1.1 有:
第一主成份
国外确定服装号型:第一主成份。
成年男子上衣第一主成份的贡献率
通过成人男子8个身体部位尺寸的协方差阵知:
第二主成份

对于成年男子上衣,有:
Q1:第一、第二主成份代表性是否足够?
Q2:停止?还是类似地继续寻找更多的主成份?
6.1 总体PCA
设
令
令
, ,则称 为 的主成份. 令 ,则: 的第 主成份: 的第 主成份的方差: , 。
的协方差阵为 ,因此有: 的第 个主成份的方差为 , 。 记
,则 与 具有相同的散布程度。 任意两个主成份都相互独立。
| 定义 | 公式 | 说明 |
|---|---|---|
| 第 |
表示第 |
|
| 前 |
表示前 |
|
| 第 |
||
| 第 |
表示第 |
|
| 前 |
表示前 |
6.1.1 主成分与总体的相关性
记
由于
称
6.1.2 主成分与X分量的复相关系数
令
由
则主成分
这说明主成分中含有分量
事实上,有
6.1.3 回到例子
回答我们上述提到的问题:
Q1:第一、第二主成份代表性是否足够?
Q2:停止?还是类似地继续寻找更多的主成份?
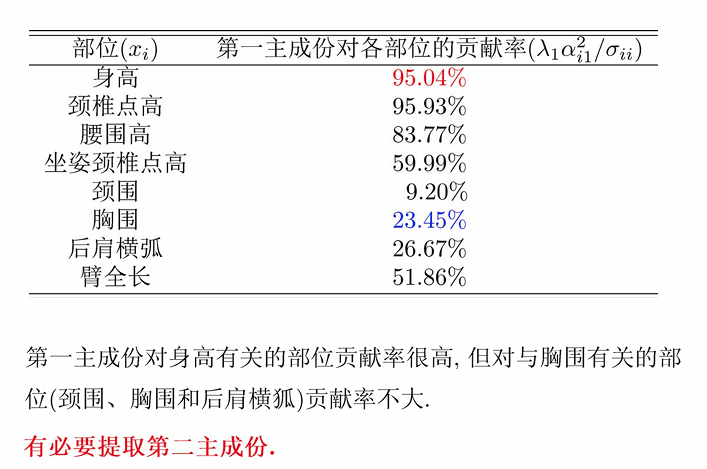
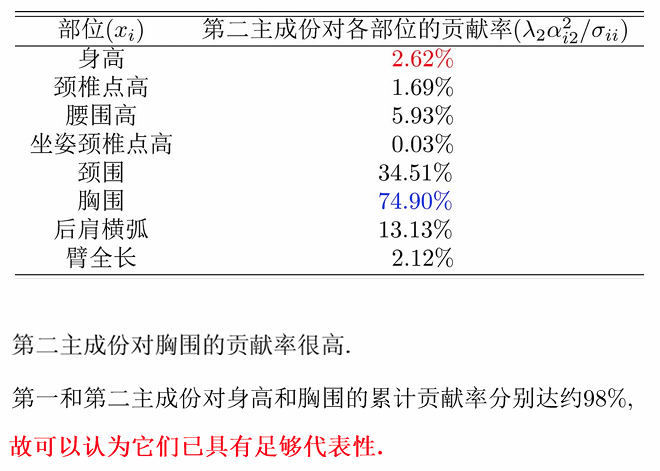
第一、二主成分对身高:
第一、二主成分对胸围:
6.2 R主成分分析:处理量纲
主成分分析主要是对随机变量的协方差矩阵进行分析,将向量投影到方差大的方向以获得重要的主成份。
Q:变量的量纲影响变量的方差,有必要消除量纲对方差的影响。
A:对变量进行标准化处理,即令:
其中
是 的相关阵, 的主成份与量纲无关。
6.2.1 R主成分分析的定义
设
则称
令$Y^{}=(y_{1}^{},\cdots,y_{p}^{})’
| 定义 | 公式 | 说明 |
|---|---|---|
| $\begin{align}\text{Cov}(Y^{})&=\Lambda^{}\&=\text{diag}(\lambda_{1}^{},\cdots,\lambda_{p}^{})\end{align}$ | ||
| 第 |
— | |
| 前 |
— | |
| 第 |
$\alpha_{jk}^{}\sqrt{\lambda_{k}^{}}$ | $\sum_{k = 1}^{p}\lambda_{k}^{}(\alpha_{jk}^{})^{2}=1,\ 1\leq j\leq p$ |
| 前 |
$\sum_{i = 1}^{k}\lambda_{i}^{}(\alpha_{ij}^{})^{2}$ | — |
6.3 样本主成分分析(基于观测数据)
假设总体
样本主成份分析也就是基于样本协方差阵
样本主成份的定义 :(使用
| 相关定义 | 说明 |
|---|---|
| 与特征根对应的正则正交特征向量 | |
| 令 |
|
| 记 |
: 和 分别是 的第 主成份 ,第 主成分系数 和第 主成份的方差 的极大似然估计, 。
相应地,可以得到主成份对总体的贡献率、对总体分量的因子负荷量以及总体分量的贡献率的极大似然估计。
6.3.1 经验总体下的总体主成份分析
定义随机向量
则
显然有:
经验总体下主成份的求解 :
| 求 |
主成分 | 说明 |
|---|---|---|
| (1) 求第一主成份 | ||
| (2) 求第二主成份 | ||
| (3) 依次求第三到第 |
—- |
因此,
6.4 样本R主成分分析
基于样本相关阵的主成分分析就是样本R主成分分析。
记:
即
此外,令:
那么$x_{1}^{},\cdots,x_{n}^{}
则对$x_{1}^{},\cdots,x_{n}^{}$进行主成分分析即是样本R主成分分析。
PS:
- (总体)主成分分析与R主成分分析的结论可能不一致。
- 样本主成分分析与样本R主成分分析的结论可能不一致。
6.5 主成分的统计推断
对实际数据进行的主成份分析时,事先会设定一个主成份贡献率的阈值(1 - δ)。
得到样本的主成份后,可以计算前k个样本主成份的贡献率:
如果:
是否就可以认为:
A: 需要对协差阵的特征根
首先假定
,则参数 的似然函数为: 由于
,即 和 仅与 有关,其似然函数为 : 为简单起见,再假定
,即所有特征根都不等。 此时
与 无关。 因为由
的任意性,在给定 下,正交矩阵 也是任意的。 事实上,考虑参数的自由度:在
下
6.5.1 Fisher信息阵与极大似然估计的渐近正态性
假设
则Fisher信息阵为:
在独立同分布情形下,有 :
有对数似然函数:
因此对任意的
那么由Fisher信息阵的结构,知
由于
其中,
因此,对
由于
计算
则
由极大似然估计的渐近正态性知:
当
的特征根有重根时,情况比较复杂。 由极大似然估计的渐近正态性可以构造
的渐近置信区间: 也可通过方差齐性变换,导出 :
可得
的另一个置信水平为 的渐近置信区间:
6.5.2 与主成分分析有关的检验问题
A.检验问题I
检验统计量的构造 - 由
进而可得 :
当:
时,拒绝零假设,它犯第一类错误的概率渐近不超过
B.检验问题II
前k个主成分的累计贡献率是否大于给定的值
考虑如下的累计贡献率统计量的渐近分布 :
定义如下的累计贡献率函数:
由Cramér定理有:
其中 :
事实上,若记
因此:
是指示函数:
将极大似然估计
因此有:
结论:当:
当标准化的统计量大于
C.再次回到例子(统计检验)
样本协差阵的特征根从大到小依次为:
设定累计贡献率的阈值
由于
即检验问题Ⅱ:前2个主成分的累计贡献率是否大于给定的值
?
计算
计算检验临界值 : 其中
结论:拒绝零假设,即认为
6.5.3 R主成分分析的检验
由于在R主成份分析中,样本相关阵的特征根$\hat{\lambda}_{1}^{},\cdots,\hat{\lambda}_{p}^{}
此外,$(\lambda_{1}^{},\cdots,\lambda_{p}^{})