多元统计分析-Ch3 多元正态分布的估计与检验
【挑战20天学完多元统计分析,让我们说:DDL是最佳生产力!】
急,只剩下10天了。。。
Ch3 多元正态分布的估计与检验
[TOC]
3.1 多元正态分布样本统计量
设
| metric | 公式 | 说明 |
|---|---|---|
| 样本均值 | 无偏估计,即 |
|
| 样本离差阵 | 衡量了样本点相对于样本均值的离散程度。 | |
| 样本协方差阵 | 对离差阵进行归一化 |
事实:
是 的完全充分统计量, 这意味着 和 包含了样本中关于总体参数 和 的所有信息。
3.1.1 (
; ; 与 相互独立。
证明:
(1)记
,则有 , 。 令
为 阶正交矩阵,其中:
的第一列 被特别选择为与样本均值方向相关的向量。令 记为 ,则 代表了样本均值方向上的信息, 则代表了与样本均值正交的剩余信息。 从上面的
可以得到: 相互独立,且 , 。 因而有 ,即(1)成立。 (2)由于
,即 ,因而有 所以(2)成立。 又由于
, ,因此 与 独立,即(3)成立。
3.2 多元正态分布的参数估计
3.2.1 极大似然估计
观测样本
首先求
易知
将
考虑正交分解
则上面的式子变为:
上式在
因此,正态总体参数
| —- | 公式 | 期望 |
|---|---|---|
| 样本协方差阵 | ||
| 样本精度矩阵 |
因此,
3.2.2 样本相关系数
记
记
A. 样本相关系数的精确分布
考虑二元正态分布的情形: 精确分布假设总体
假设下面的样本来自二元分布总体
由这些样本可以定义样本离差阵:
其中样本均值为
根据相关系数
样本相关系数r与分布的参数
则
则
所以, r 的分布与分布的参数
不妨假设
(
再由Wishart分布的定义知,随机向量
其中,
由变换
当
因此,可以用此分布作为, 零假设为
(书P124-定理5.4.1):假设
是来自p元正态分布 的i.i.d.样本,如果 ,则样本相关系数 的密度函数为:
应用:
检验问题:(双侧检验:检验变量之间是否存在任何形式的相关性:正相关或负相关)
与 独立 等价于:
检验方案一: 计算出C,比较r与C的大小。
- 给定显著性水平
(通常取为0.05); - 计算临界值
,满足 - 如果
,则拒绝零假设,即认为 与 不独立。
检验方案二: 换另外一种方式来确定C:转换为查表计算的t值
通常采用统计量
将相关系数
由Wishart分布的性质6( 独立分解性质 )知, 当
与 独立,即 时,有 :
与 相互独立; ; ; t分布:
为服从自由度为n的t分布。
在零假设(
总结检验方案二:
- 给定显著性水平
; - 如果
,则拒绝零假设,即认为 与 不独立, 其中 是自由度为 的标准 分布的 分位点。
检验方案三:单侧正/负相关检验:检验变量之间是否存在正/负相关。
| 独立 vs 正相关的检验问题 | 独立 vs 负相关的检验问题 |
|---|---|
| 计算检验的 |
计算检验的 |
| 如果 |
如果 |
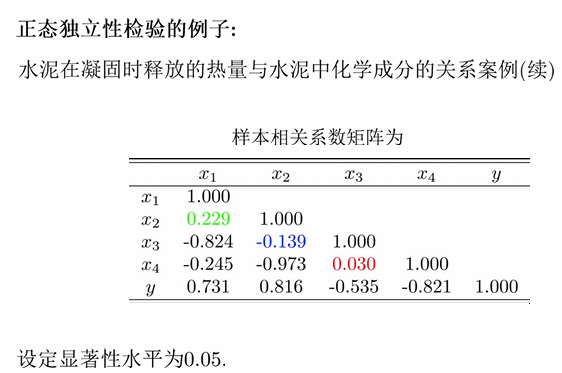
例子(栗子,吃一口)
在Ch1中的栗子继续拿来讨论:
(1)变量
与 独立与正相关检验问题 检验统计量为
因此,变量
与 独立与正相关检验问题: 故而不能拒绝
与 之间的相互独立性。(接受 ) (2) 变量
与 独立与负相关检验问题: 则不能拒绝
与 之间的相互独立性。 (接受 ) (3) 变量
与 独立与负相关检验问题: 则拒绝
与 之间的相互独立性,认为它们负相关。(拒绝 )
B. 样本相关系数的渐近分布(总体不服从正态分布)
注意到,样本相关系数
| $\begin{align} v_{xy} &= \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y}) \ &= \frac{1}{n} \sum_{i=1}^{n} x_i y_i - \frac{1}{n} \sum_{i=1}^{n} x_i \bar{y} - \frac{1}{n} \sum_{i=1}^{n} y_i \bar{x} + \frac{1}{n} \sum_{i=1}^{n} \bar{x} \bar{y} \ &= \frac{1}{n} \sum_{i=1}^{n} x_i y_i - \bar{x} \bar{y} - \bar{y} \bar{x} + \bar{x} \bar{y} \ &= \frac{1}{n} \sum_{i=1}^{n} x_i y_i - \bar{x} \bar{y} \ &= t_5 - t_1 t_2 \end{align}$ | $\begin{align}v_{xx}&= \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2 \&= \frac{1}{n} \sum_{i=1}^{n} (x_i^2 - 2 x_i \bar{x} + \bar{x}^2) \&= \frac{1}{n} \sum_{i=1}^{n} x_i^2 - 2 \bar{x} \cdot \frac{1}{n} \sum_{i=1}^{n} x_i + \frac{1}{n} \sum_{i=1}^{n} \bar{x}^2 \&= \frac{1}{n} \sum_{i=1}^{n} x_i^2 - 2 \bar{x} \cdot \bar{x} + \bar{x}^2 \&= \frac{1}{n} \sum_{i=1}^{n} x_i^2 - \bar{x}^2 \&= t_3 - t_1^2\end{align}$ | $\begin{align}v_{yy}&= \frac{1}{n} \sum_{i=1}^{n} (y_i - \bar{y})^2 \&= \frac{1}{n} \sum_{i=1}^{n} (y_i^2 - 2 y_i \bar{y} + \bar{y}^2) \&= \frac{1}{n} \sum_{i=1}^{n} y_i^2 - 2 \bar{y} \cdot \frac{1}{n} \sum_{i=1}^{n} y_i + \frac{1}{n} \sum_{i=1}^{n} \bar{y}^2 \&= \frac{1}{n} \sum_{i=1}^{n} y_i^2 - 2 \bar{y} \cdot \bar{y} + \bar{y}^2 \&= \frac{1}{n} \sum_{i=1}^{n} y_i^2 - \bar{y}^2 \&= t_4 - t_2^2\end{align}$ |
记随机变量序列
由于
当样本量
增加时,样本均值向量 的分布会趋近于多元正态分布,无论原始随机向量 的分布形态如何,前提是每个 有有限的期望和协方差。 定理(多元中心极限定理): 设
是一组相互独立且同分布(i.i.d.)的 p维随机向量,具有期望向量 和协方差矩阵 。当 n 足够大时,标准化的样本均值向量 近似服从多元正态分布 ,即 其中,
是样本均值向量。 引入渐进分布:
令:
, 是经过标准化的协方差项, 是样本协方差, 是样本方差。 令
, 给出
.这个 分布的均值为0,协方差为 . (书p133 定理5.4.3)令
是一列p维的随机向量,b是一个p维固定向量,当 ,使得 , 此处 . 假设
是一个向量值函数,其中每个分量 在 处有非零矩阵,定义矩阵 ,其 元素为 . 当 ,使得: 上面的
的计算有些复杂,换一个 来验证一下这个定理:
让我们回到:
此时有将统计量
再由Cramér定理(定理5.4.3),可得样本相关系数
其中
Q: Cramer定理?(Delta方法)
A: 在上面定理5.4.3有提到,总的来说,假设我们有一个大样本的均值向量
,且它的分布趋近于正态分布(由中心极限定理可以得到),那么这个均值向量 可以应用一个可微函数 ,经过变换后的量 也会趋于正态分布。
C. 置信区间(区间估计)
由于样本相关系数的精确分布不是分布自由的,即与未知的总体相关系数
有关,因此无法用于置信区间的构造。
因此使用其渐近分布构造总体相关系数
(1) plug-in插入方法
既然渐进方差
当
因此,总体相关系数
其中
置信区间的统计意义
记:
是栗子,我们有救了
(1) 变量
| 变量 | 置信区间 | 相互独立性 |
|---|---|---|
| 变量 |
0在此区间里,故不能拒绝 |
|
| 变量 |
0在此区间里,故也不能拒绝 |
|
| 变量 |
0不在此区间里,故不能认为 |
(2) 方差齐性变换(Fisher Z变换)
求函数
所以:
由上式可以构造
为构造
称
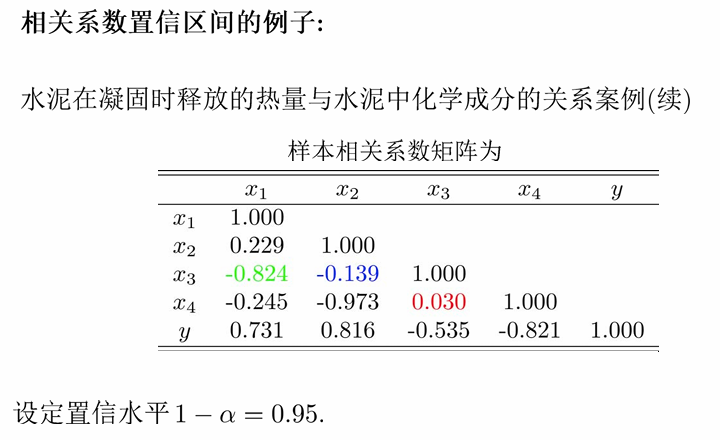
栗子
水泥在凝固时释放的热量与水泥中化学成分的关系案例(续) 设定置信水平
变量
与 的相关系数 的置信区间的计算: 其中
。
| 变量 | 置信区间 |
|---|---|
| 变量 |
|
| 变量 |
|
| 变量 |
注意:置信区间变窄。
3.2.3 正态总体均值的置信域估计
A.单总体
设
如果总体协方差矩阵
则
即有
Q:
分布与置信域的联系? A: 具体来说,样本均值
和总体均值 之间的偏差经过标准化后(即通过协方差矩阵的逆来标准化)符合 分布。这意味着,我们可以通过卡方分布的分位点来构建置信区间。 置信域 D中
是卡方分布自由度为 时,置信度为 的分位点。这表示总体均值 在给定的样本数据下落入该置信域的概率为 。
因为
由正态样本统计量的性质知 :
, , 且 与 独立. Hotelling
分布性质如下:
性质 说明 1. ,其中分子分母相互独立; 2.
因此有:
则当
即有
PS: 因为这个置信域D是一个二次型,那么上述的不等式就是对这个二次型的约束,所以,这个置信域是一个超椭球。
- 协方差矩阵
的逆 定义了椭球的方向和形状,特征值决定了每个方向上的伸缩因子。 分布的临界值 确定了超椭球的大小。
B.两总体
设独立总体
记
已知:
| 已知条件 | 对应公式 |
|---|---|
| 样本X的样本离差阵和协方差矩阵 | |
| 样本Y的样本离差阵和协方差矩阵 |
我们下面讨论的问题是:
: ① 未知,② 已知 (这种情况在本课程中不涉及,下面也不会涉及)
因此下面对于
由
根据二次型的性质:
,假设有个p阶方阵 ,则有 . 当 时, .
由此得到
记
由
知
记
由于
进而可知
由此得到
3.2.4 正态总体均值的Bayes估计
Bayes方法两要素:
- 样本的密度函数形式已知、只是参数未知.
- 参数也被视为随机变量,其密度函数(先验密度)完全确定.
先验密度如何确定?
- 专业知识和专家经验.
- 数学方法,如:共轭先验、Jeffery先验、无信息先验等.
A. Bayes推断
基于后验密度(分布): 后验密度 ∝ 似然函数 × 先验密度
- 数据(样本)的似然函数为给定参数下的条件密度:
- 数据(样本)和参数的联合密度:
- 数据(样本)的边缘密度:
- Bayes后验密度为给定数据(样本)下参数的条件密度:
.
逆Wishart分布
若
逆Wishart分布的密度函数 :
多元正态分布参数
其中,
后验密度
其中,
因此,该先验分布是共轭先验分布。
注:后验密度(分布)的形式一般都比较复杂,通常采用Markov chain Monte Carlo方法来计算。
Bayes估计
- Bayes估计 = 参数的后验均值
的Bayes估计: 的Bayes估计: (性质8)
作业1
设
首先,我们知道这个答案是
(雾),然后开始写…
对于每个样本
由于
为了求