数据库上机实验1
实验1
[TOC]
1-6
一、 安装MYSQL
在安装MYSQL的同时,也安装了DataGrip可视化界面,本次实验使用DataGrip与MYSQL命令行界面交叉使用来练习SQL语言。对于DataGrip来说,其显示的代码更完整,以及展示的更规整。
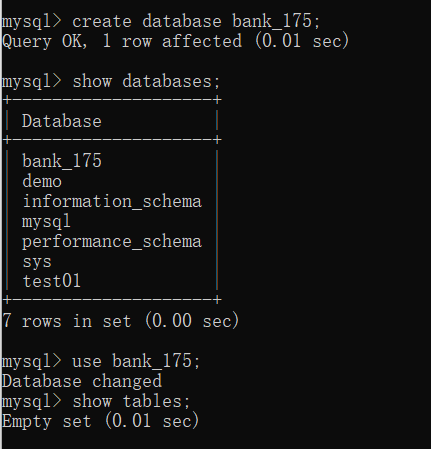
二、 建立并使用BANK
我的学号是20069100175,因此选取后三位175作为bank的后缀。
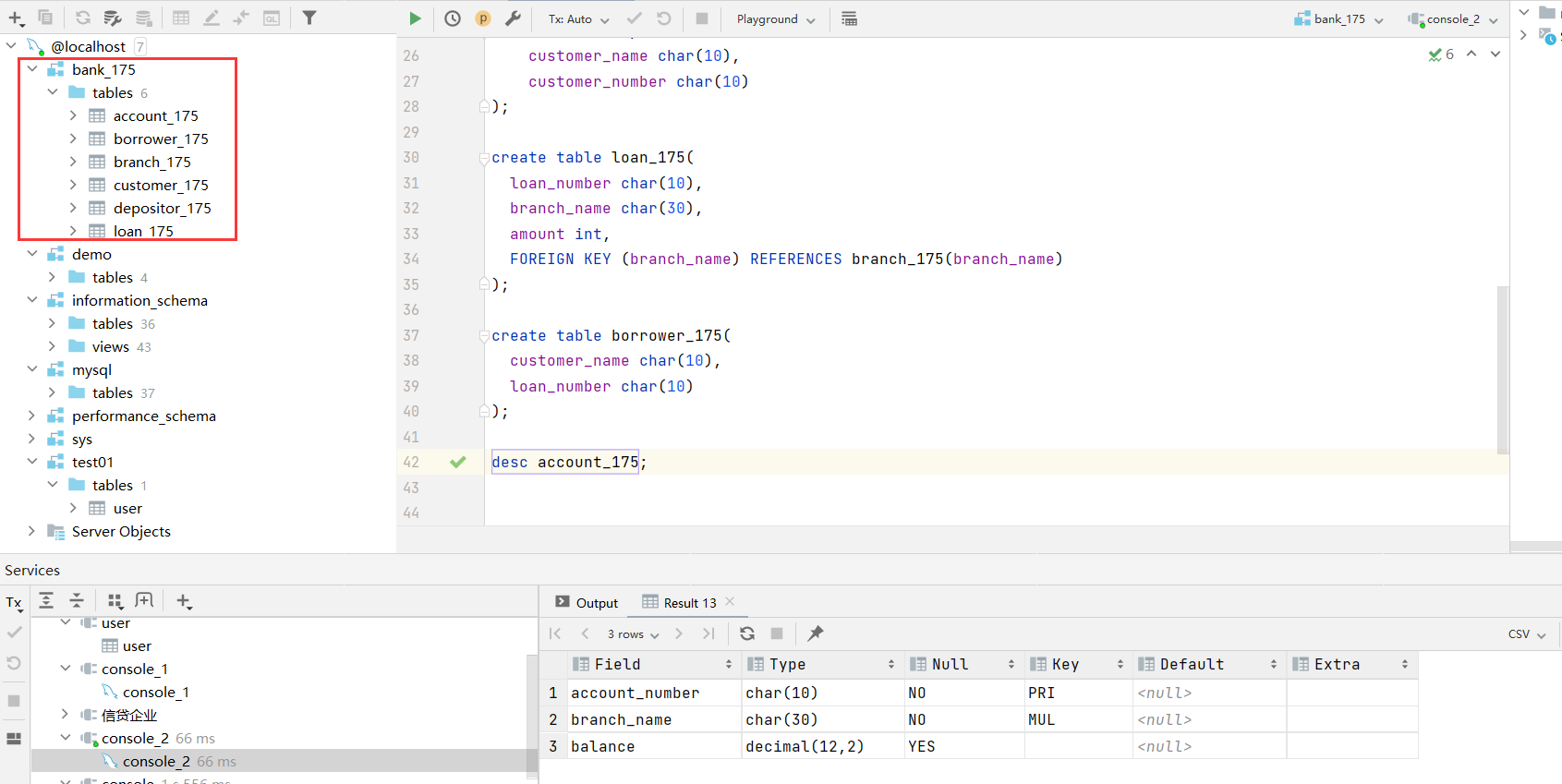
三、建表并输入数据
1 | # 建表:BRANCHxxx, CUSTOMERxxx, LOANxxx, BORROWERxxx, ACCOUNTxxx, DEPOSITORxxx; |
批量建表如下:
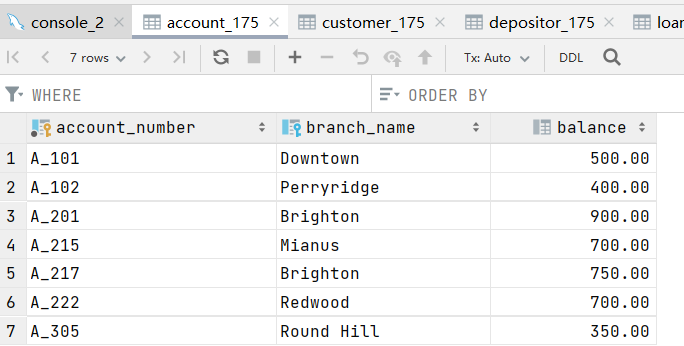
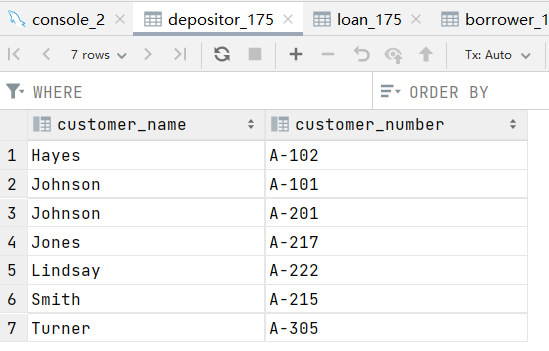
批量录入数据如下:

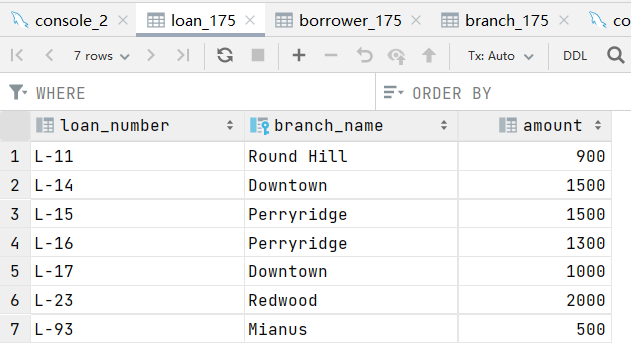
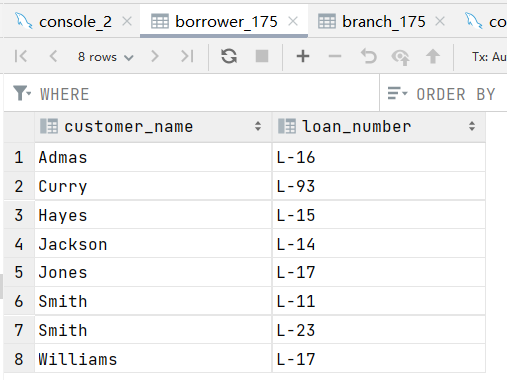
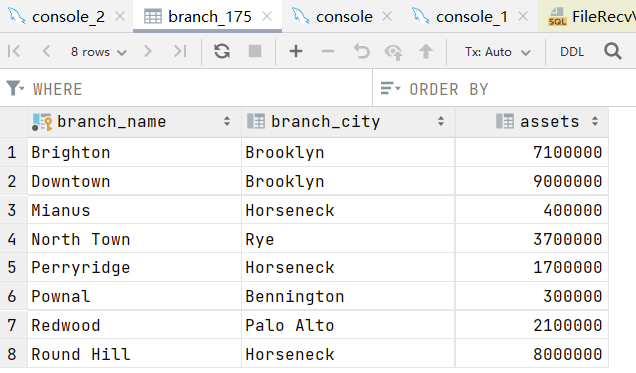
7
创建图3.12的四张表,输入一些数据,查询书上第三章3.2, 3.9的作业题。
一、创建表并输入数据
在给定的schema中,employee_name是主键,说明要求每一位员工的姓名必须是不同的。company_name是主键,说明每一家公式的名字也是不同的。因此建立schema如下:
1 | # set schema |
对于每个员工的上司,最高级的员工,他的上司是他自己;上司的姓名也在员工表内。
插入数据时没有写入E5。
1 | # insert data |
二、查询3.2
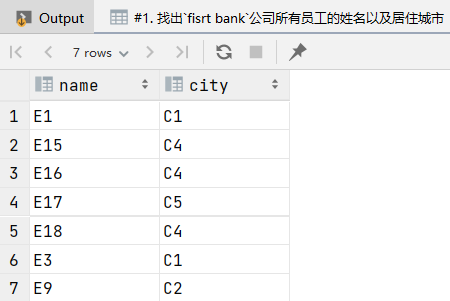
1. 找出fisrt bank公司所有员工的姓名以及居住城市
设first bank为COM1:
1 | select works.employee_name as name,city from employee,works where works.employee_name=employee.employee_name and company_name='COM1'; |
结果:
2.找出fisrt bank公司所有收入超1w美元的员工的姓名、街道地址、居住城市
1 | select works.employee_name as name,street,city,salary from works,employee where salary>10000 and works.employee_name=employee.employee_name; |
结果:

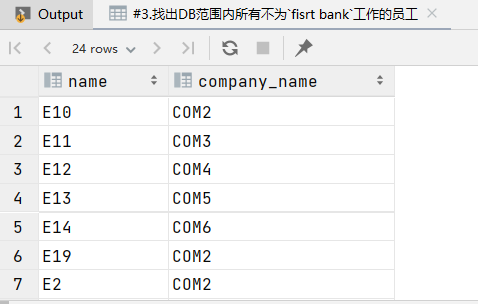
3.找出DB范围内所有不为fisrt bank工作的员工
1 | select works.employee_name as name,company_name from employee,works where works.employee_name=employee.employee_name and company_name!='COM1'; |
结果:
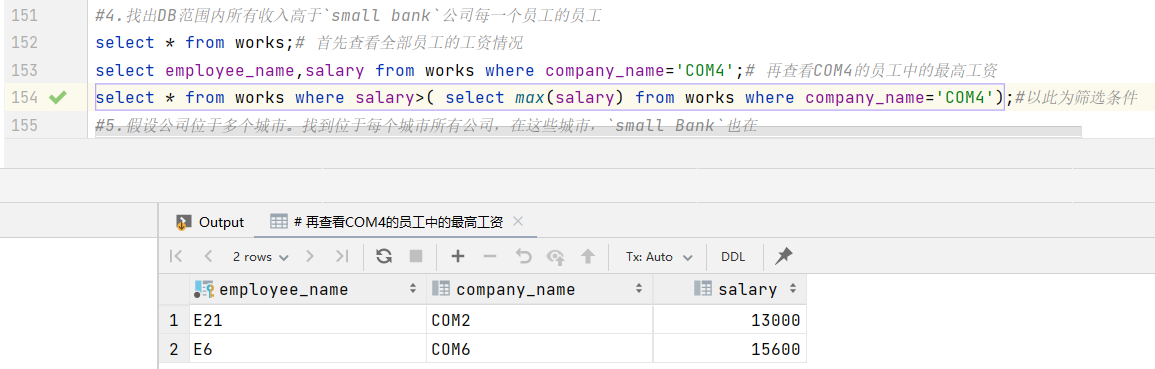
4.找出DB范围内所有收入高于small bank公司每一个员工的员工
假设small bank为COM4。在COM4中,工资最高的是E12,其工资为10200。
1 | select * from works;# 首先查看全部员工的工资情况 |
结果:
5.假设公司位于多个城市。找到位于每个城市所有公司,在这些城市,small Bank也在
公司位于多个城市,可能是类似总公司与子公司的情况。但是由于题干中将company_name设置为了主键,因此是唯一的、不可重复的。由于其对应的city可以是多个,但是对于唯一的公司只能有一条数据,因此没有办法设置为多个城市?
相当于暂时忽略掉主键的设定。
1 | # (1)首先先取消掉设置的主键。并添加一些子公司的地址数据。 |
结果:

然后要删除添加的数据:
1 | # 把company修改为原来样子 |
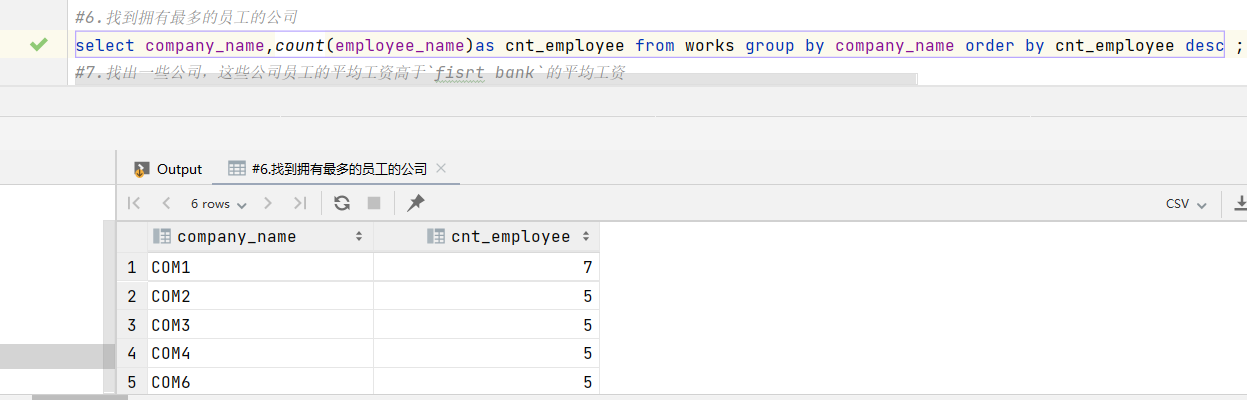
6.找到拥有最多的员工的公司
count解决问题!使用order对人数排序,排在第一的是人数最多的公司。
1 | select company_name,count(employee_name)as cnt_employee from works group by company_name order by cnt_employee desc ; |
结果:
7.找出一些公司,这些公司员工的平均工资高于fisrt bank的平均工资
having后的条件是进行分组后的数据再次进行筛选。
1 | select company_name,avg(salary) as avg_salary from works group by company_name order by avg_salary desc; |
结果:

查询代码
1 | # 查询操作 |
三、查询3.9
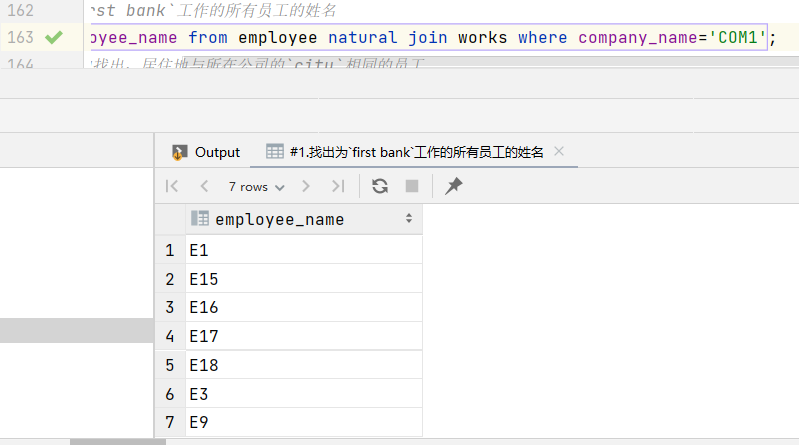
1.找出为first bank工作的所有员工的姓名
1 | select employee_name from employee natural join works where company_name='COM1'; |
结果:
2.在DB范围中找出,居住地与所在公司的city相同的员工
这里给出了两种代码,所得到的结果是相同的;但是自然连接的代码会比较简洁。
1 | select * from employee,company,works where works.employee_name=employee.employee_name and works.company_name=company.company_name and company.city=employee.city; |
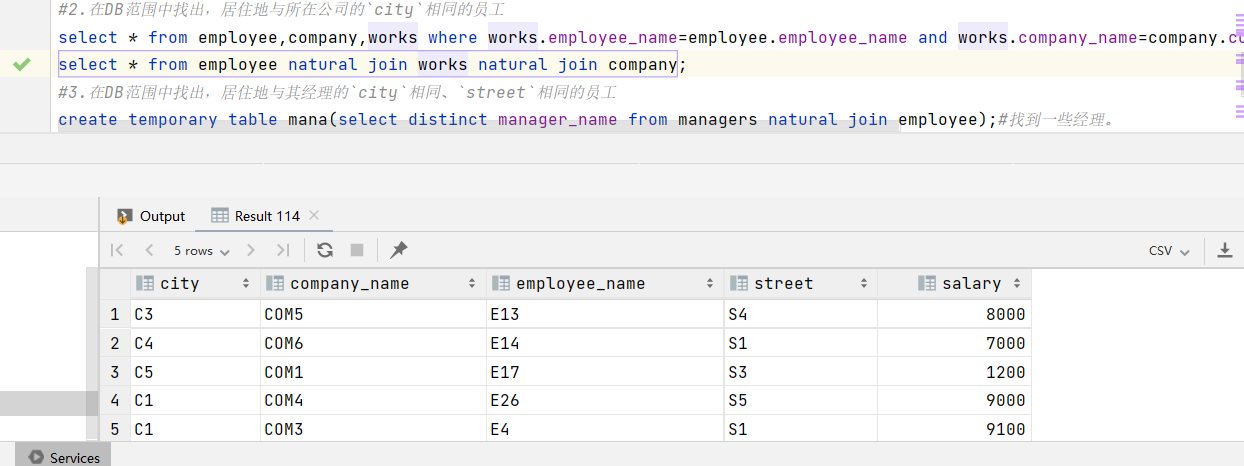
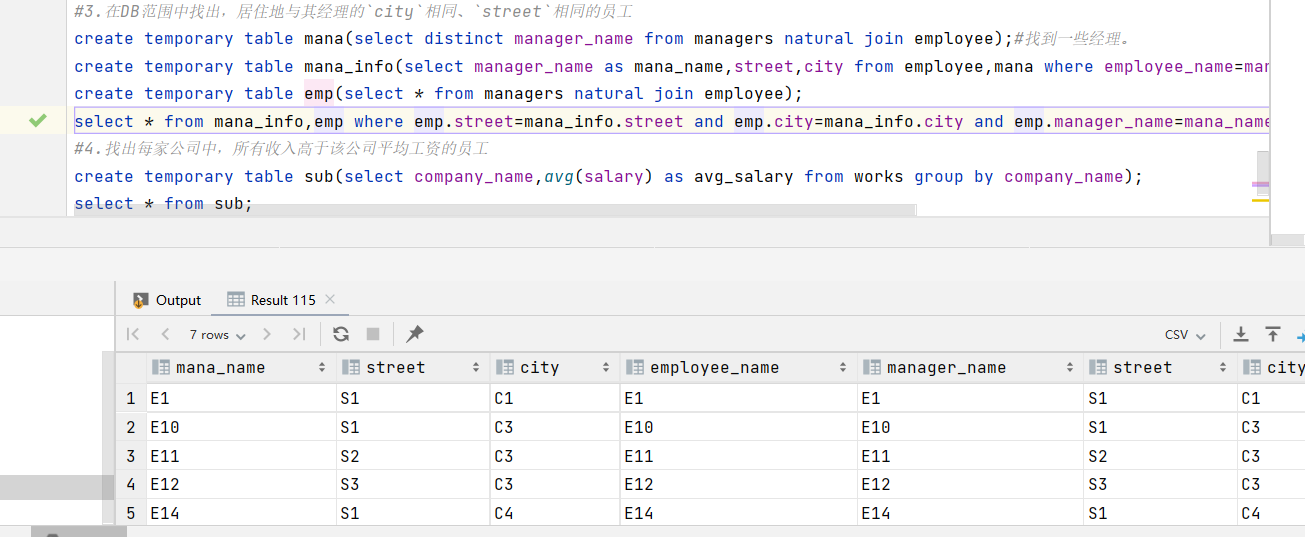
3.在DB范围中找出,居住地与其经理的city相同、street相同的员工
由于我设计了多级的经理,最高级的经理的manager是他自己。因此这里的思路是:先从managers中找到所有的经理,由于所有的经理也在employee中,该表中也有他们的住址信息。因此对两表进行如下操作:
1 | create temporary table mana(select distinct manager_name from managers natural join employee); |
结果:
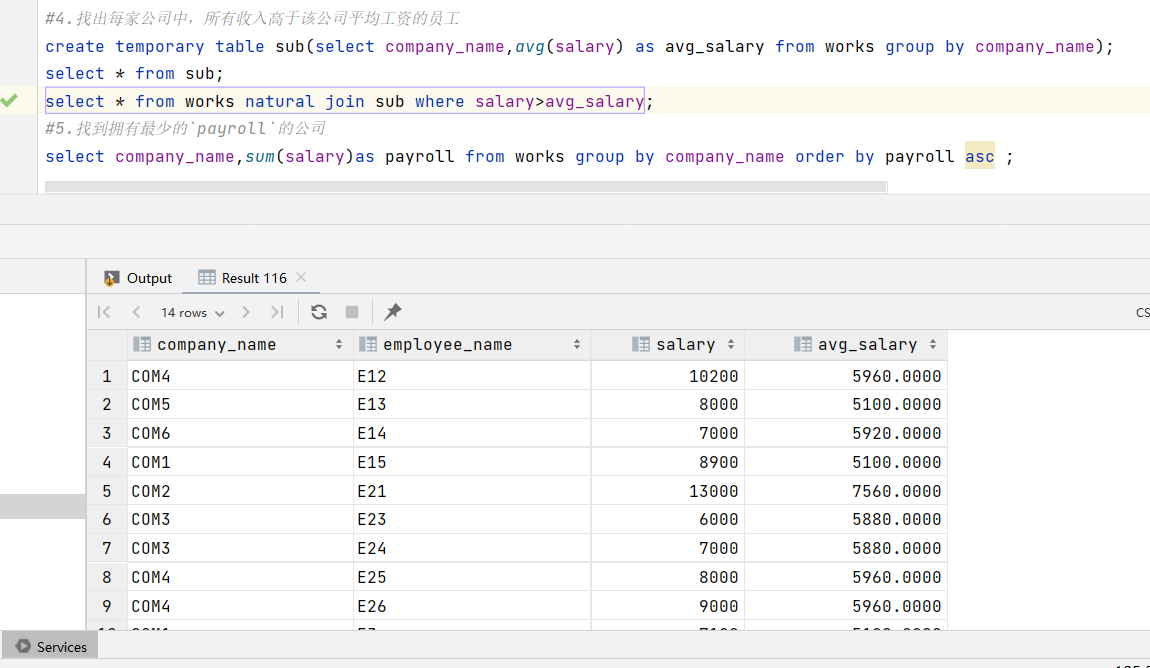
4.找出每家公司中,所有收入高于该公司平均工资的员工
这里也是使用了建立临时表。
1 | create temporary table sub(select company_name,avg(salary) as avg_salary from works group by company_name); |
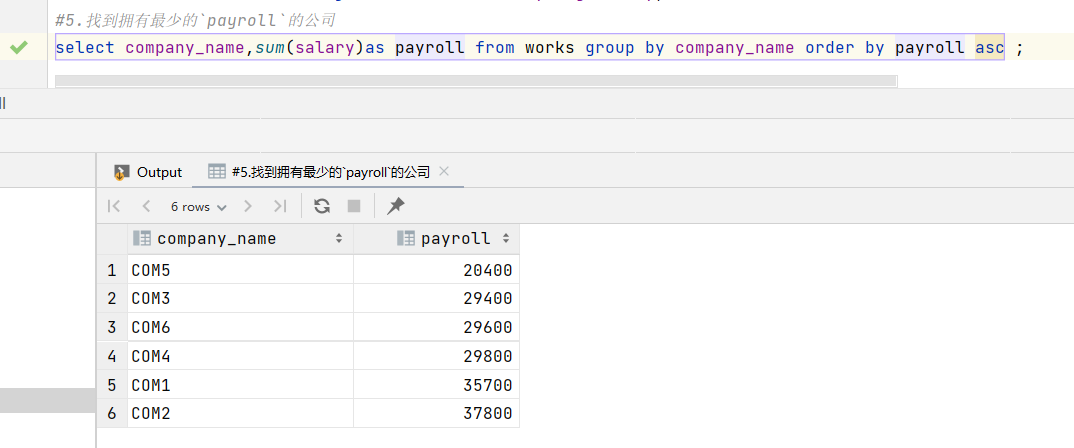
5.找到拥有最少的payroll的公司
payroll指的是公司发放的工资总额。该处使用升序排序,因此排在第一个的公司即为目标公司。
1 | select company_name,sum(salary)as payroll from works group by company_name order by payroll asc ; |
结果:
查询代码
1 | # 3.9 |